Clear Sky Science · ar
تحسين التعلم غير الخاضع للإشراف لمعادلة هوية الأشخاص بين الكاميرات لصورة واحدة
لماذا تهم الكاميرات الأذكى
تعتمد المدن الحديثة على شبكات من كاميرات الأمن للمساعدة في الحفاظ على سلامة الناس، لكن هذه الكاميرات لا «تتفق» تلقائياً على هوية الأفراد. قد يظهر الشخص بشكل مختلف جداً من كاميرا إلى أخرى بسبب تغير الزوايا، الظلال، أو الازدحام. تتناول هذه الورقة تحدّي تتبّع نفس الشخص عبر عدة كاميرات بشكل موثوق دون إشراف بشري مكثف. صمّم المؤلفون نظاماً جديداً ينقّي ويكيّف صور الكاميرات قبل مقارنتها، مما يجعل المراقبة الرقمية أكثر دقة ويستثمر اللقطات الموجودة بكفاءة أكبر.
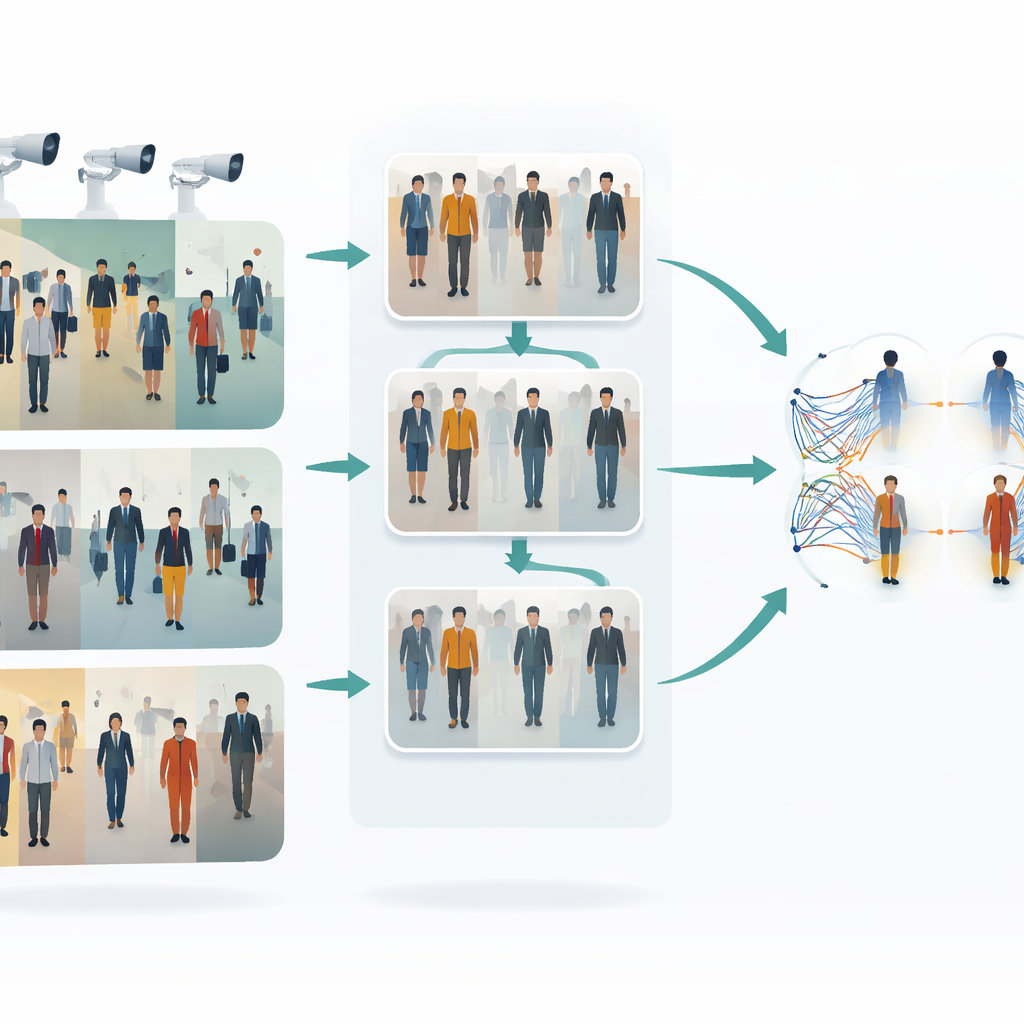
تحدّي تتبع الأشخاص عبر الكاميرات
عندما يمشي شخص عبر محطة قطار، مركز تسوق، أو شبكة شوارع، تلتقطه كاميرات مختلفة لوهَات مختلفة. قد تبدو الملابس أكثر سطوعاً أو باهتة، وتكون الوجوه مغطّاة جزئياً، وتتغير أوضاع الجسم باستمرار. تحاول الطرق التقليدية «للصورة الواحدة» التعرف على الشخص من صورة واحدة لكل كاميرا في مرور سريع، وهو ما يكون سريعاً لكنه غالباً هشّ: قد يفشل عند تغيّر الإضاءة، عندما يُحجب الشخص جزئياً، أو عندما تختلف إعدادات الكاميرات. ترميز آلاف الصور يدوياً لتدريب نظام قوي مكلف وبطيء، لذا هناك اهتمام كبير بأساليب تتعلم من بيانات غير معنونة مع الحفاظ على القدرة على التعامل مع هذا التنوع البصري.
تعليم الكاميرات مشاركة نمط بصري مشترك
الفكرة الأساسية الأولى في هذا العمل هي جعل صور الكاميرات المختلفة تبدو أكثر تشابهاً قبل أي محاولة للمطابقة. يستخدم المؤلفون نوعاً من محوّلات الصورة إلى صورة يُدعى CycleGAN لتحويل صور من كاميرا إلى نمط يبدو وكأنها ملتقطة من كاميرا أخرى، دون الحاجة إلى أمثلة مُقرنة تماماً. يخلق ذلك العديد من المتغيرات الواقعية لكل شخص، معبّرة عن زوايا رؤية مختلفة، وإضاءات، وخلفيات متنوعة. من خلال مزج وإعادة توازن الأنماط عبر الكاميرات، يقلّل النظام الفجوة البصرية بينها. ونتيجة لذلك، يرى خوارزم التعلم مجموعة تدريب أغنى وأكثر توحيداً تمثل أفضل ما يحدث فعلياً في شبكة مراقبة متعددة الكاميرات.
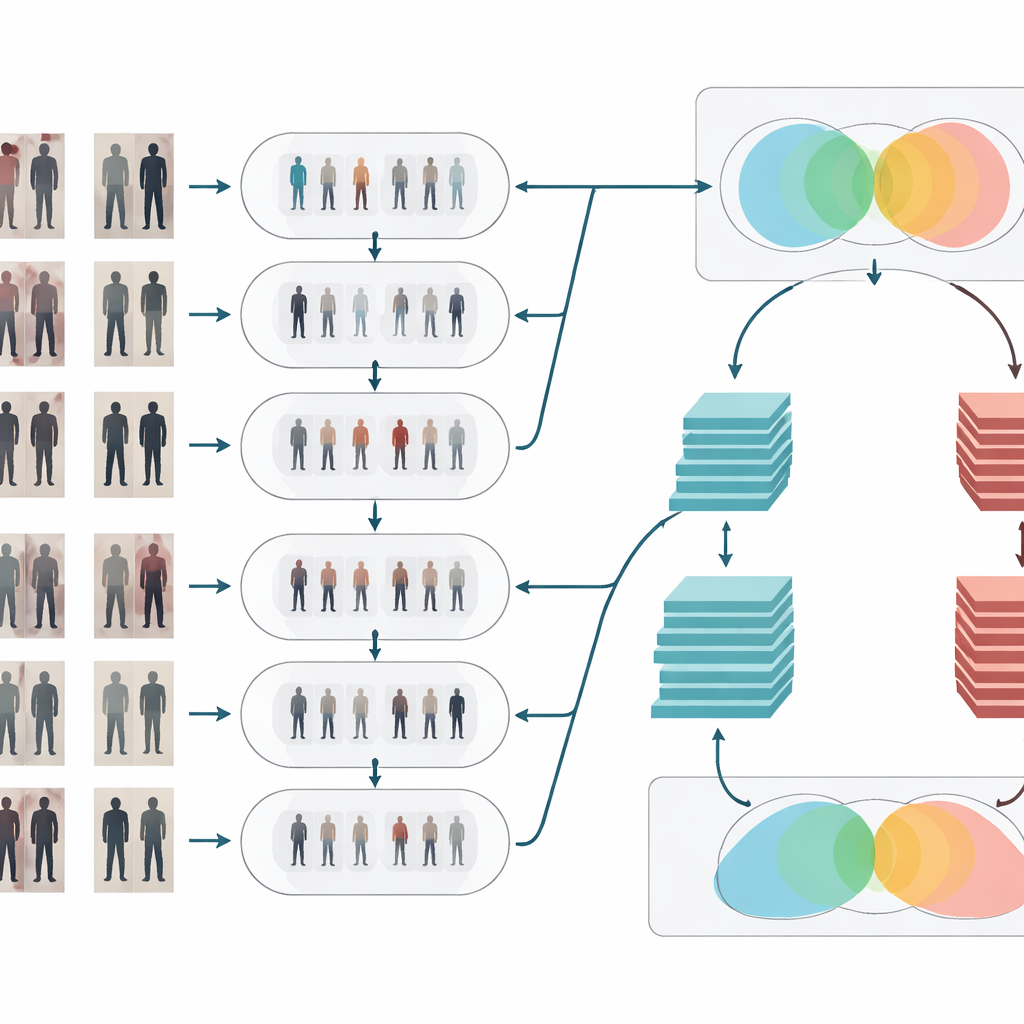
تنقية وتوضيح الإشارة البصرية
بعد تكييف النمط، تمرّ الصور بمرحلتين تنقية تقليديتين. أولاً، يزيل مرشح الوسيط الضوضاء الصغيرة والبقع—مثل عيوب المستشعر أو تشوّهات الضغط—مع الحفاظ على الحواف الهامة مثل ملامح الجسم ونقوش الملابس حادة. ثانياً، يقوم معادلة المدرج الترددي بتعديل توزيع السطوع بحيث تُرفع المناطق الداكنة وتُهدأ المناطق الفائقة السطوع، مما يحسّن التباين. معاً، تجعل هاتان العمليتان أشكال وملمس الأشخاص أكثر وضوحاً واتساقاً عبر الكاميرات، ما يساعد مرحلة التعرّف على التركيز على التفاصيل البصرية المهمة بدلاً من الانشغال بالإضاءة الضعيفة أو البكسلات المشوشة.
دماغان يفكران معاً
للاستدلال ما إذا كان صورتان تُظهران نفس الشخص، يستخدم النظام شبكة سيامية—بمعنى شبكتين عصبيتين متطابقتين تشتركان في الأوزان وتعملا بالتوازي على كل صورة. تعزز هذه الورقة الفكرة بمنح التصميم السيامي فرعين بعمقين مختلفين. يعتمد أحد الفروع على نموذج ضحل نسبياً (ResNet-50) يلتقط دلائل متوسطة المستوى مثل مناطق الملابس العامة وشكل الجسم الكلي. أما الآخر فيستخدم نموذجاً أعمق (ResNet-152) يلتقط تفاصيل أدق مثل الطيات الخفيفة، والملمس، والإكسسوارات الصغيرة. تُجمع خرائط الميزات هذه بعناية ثم تدمج، ليكوّن التمثيل النهائي مزيجاً من البنية الواسعة والمظهر الدقيق. بعد ذلك تحسب الشبكة درجة تشابه تشير إلى ما إذا كانت لقطتان من كاميرتين مختلفتين تنتميان على الأرجح إلى نفس الفرد.
تجربة الطريقة
يقوم المؤلفون بتقييم إطارهم على مجموعة بيانات معيارية واسعة الاستخدام لصور المشاة الملتقطة بواسطة كاميرات متعددة. يقارنون نهجهم مع عدة طرق قوية قائمة تركز إما على سياق الكاميرا، أو التجميع الذكي، أو التصاميم السيامية التقليدية. عبر العديد من مقاييس النجاح—مثل الدقة، والموثوقية، والحساسية—يظهر النظام الجديد متفوقاً باستمرار، مقترباً أو متجاوزاً 99% دقة في بعض تقسيمات التدريب والاختبار. كما تظهر تجارب مفصّلة أن كل مكوّن مهم: حذف تعزيز CycleGAN أو تنظيف الصورة أو التصميم ذي الفرعين يقلل الأداء، مما يؤكد أن المكاسب تأتي من عمل خط المعالجة كُله معاً.
ماذا يعني هذا للمراقبة في العالم الواقعي
بعبارات عملية، يُظهر هذا البحث كيفية جعل شبكات الكاميرات أفضل بكثير في تتبّع الأشخاص أثناء تحركهم عبر مساحات معقّدة، حتى عندما تتغير الظروف ولا يتوافر وقت لترميز البيانات يدوياً. من خلال توحيد مظهر الصور وتنقيتها ثم مقارنتها بشبكة توأمية مصممة بعناية، يمكن للنظام المقترح التعرف على الأفراد بشكل أكثر موثوقية عبر مشاهد كاميرات متعددة. قد يدعم هذا فضاءات عامة أكثر أمناً ورقابة أكثر كفاءة، مع التأكيد أيضاً على أهمية الاستخدام المدروس والواعي للخصوصية لأدوات التعريف القوية هذه.
الاستشهاد: Vidhyalakshmi, M.K., Neduncheliyan, S., Hemlathadhevi, A. et al. Enhancing single shot unsupervised domain adaptation for inter-camera person re-identification. Sci Rep 16, 11247 (2026). https://doi.org/10.1038/s41598-026-37168-9
الكلمات المفتاحية: إعادة تعرف الشخص, كاميرات المراقبة, التعلم غير الخاضع للإشراف, رؤية حاسوبية, الشبكات العصبية العميقة