Clear Sky Science · sv
En referensdatamängd för maskininlärningssurrogat av CO2–vatteninteraktion i porskala
Varför kolinlagring under marken behöver bättre bilder
När vi talar om att bekämpa klimatförändringarna är en stor idé att fånga koldioxid (CO2) från rökgaser och lagra den djupt under marken. Men berggrunden är inte släta tankar — den liknar snarare invecklade svampar fulla av små vrår där vatten och CO2 trängs om utrymmet. Denna artikel presenterar en ny, detaljerad digital ”film” av hur CO2 tränger undan vatten genom dessa små porer, vilket ger forskare råmaterialet de behöver för att bygga snabbare datorbaserade modeller som kan förutsäga om underjordisk lagring faktiskt kommer att hålla CO2 säkert inlåst.
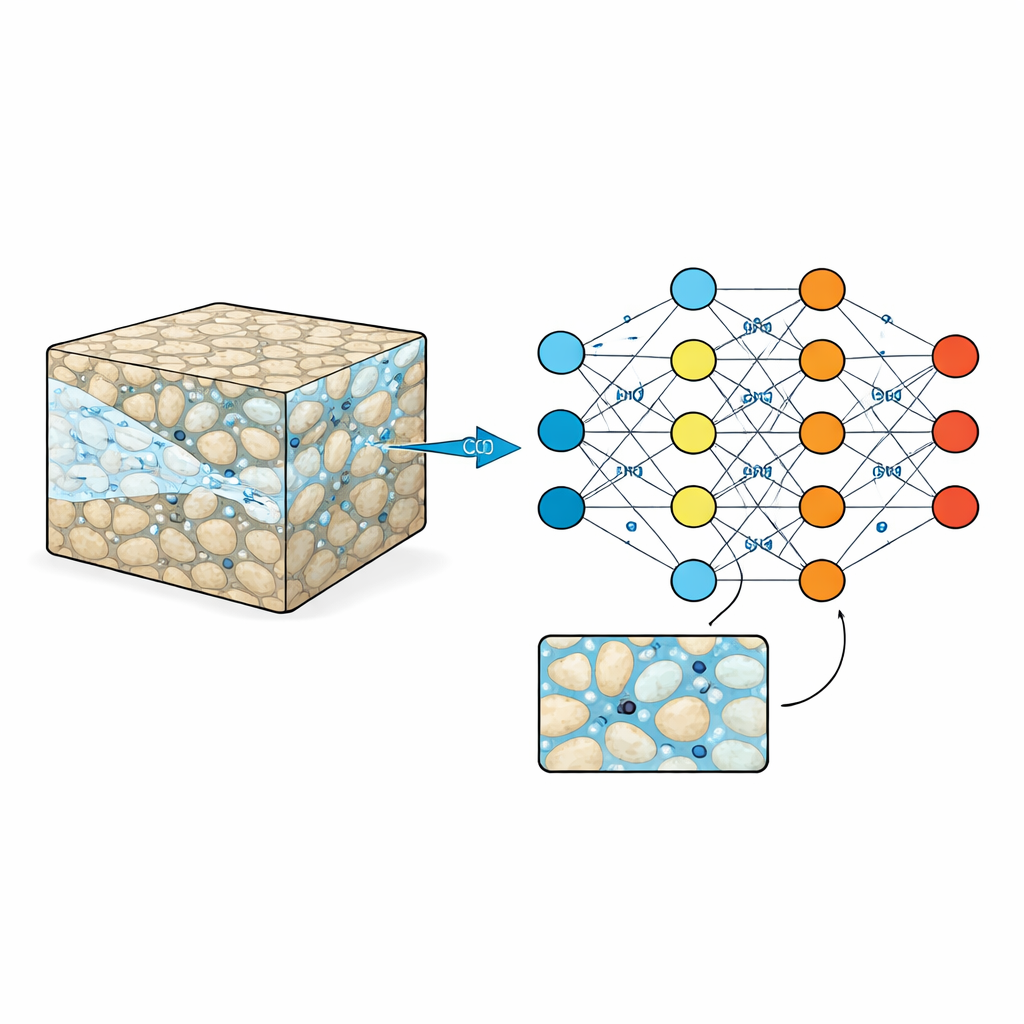
Inspektera bergsvampen
Underjordiska reservoarer som sandsten eller vulkaniska bergarter är korsade av mikroskopiska porer fyllda med vatten. När CO2 pumpas in måste det slingra sig genom denna labyrint, ibland rusa fram i kanaler och ibland fastna i återvändsgränder. Dessa mönster på fin skala styr hur mycket CO2 som kan lagras och hur säker den lagringen är under årtionden till århundraden. Traditionella laboratorieexperiment och bildtekniker kan skymta vad som händer i ett fåtal små prover, medan högprecisionsimuleringar kan följa varje detalj — men till hög kostnad i tid och beräkningsresurser. Som ett resultat förlitar sig ingenjörer ofta på förenklade formler som suddar ut den röriga småskaliga bilden, vilket kan missa viktigt beteende.
Varför smarta surrogat behöver rikt träningsdata
Maskininlärningsmodeller erbjuder en genväg: när de väl är tränade kan de förutsäga hur CO2 rör sig genom berg mycket snabbare än fullständiga fysikbaserade simuleringar. Men likt en elev är dessa modeller bara så bra som de exempel de får se. Många befintliga datamängder är för små, täcker bara enkla bergmönster eller registrerar endast det slutliga resultatet av en injektion, inte hur processen utvecklas över tid. Det gör det svårt för algoritmer att lära sig de föränderliga formerna av CO2-släpp, tryckuppbyggnad eller hur subtila förändringar i bergstrukturen påverkar flödet. Utan rikare träningsmaterial riskerar de smarta surrogaten att göra självsäkra men opålitliga förutsägelser när de utsätts för nya, mer komplicerade bergformationer.
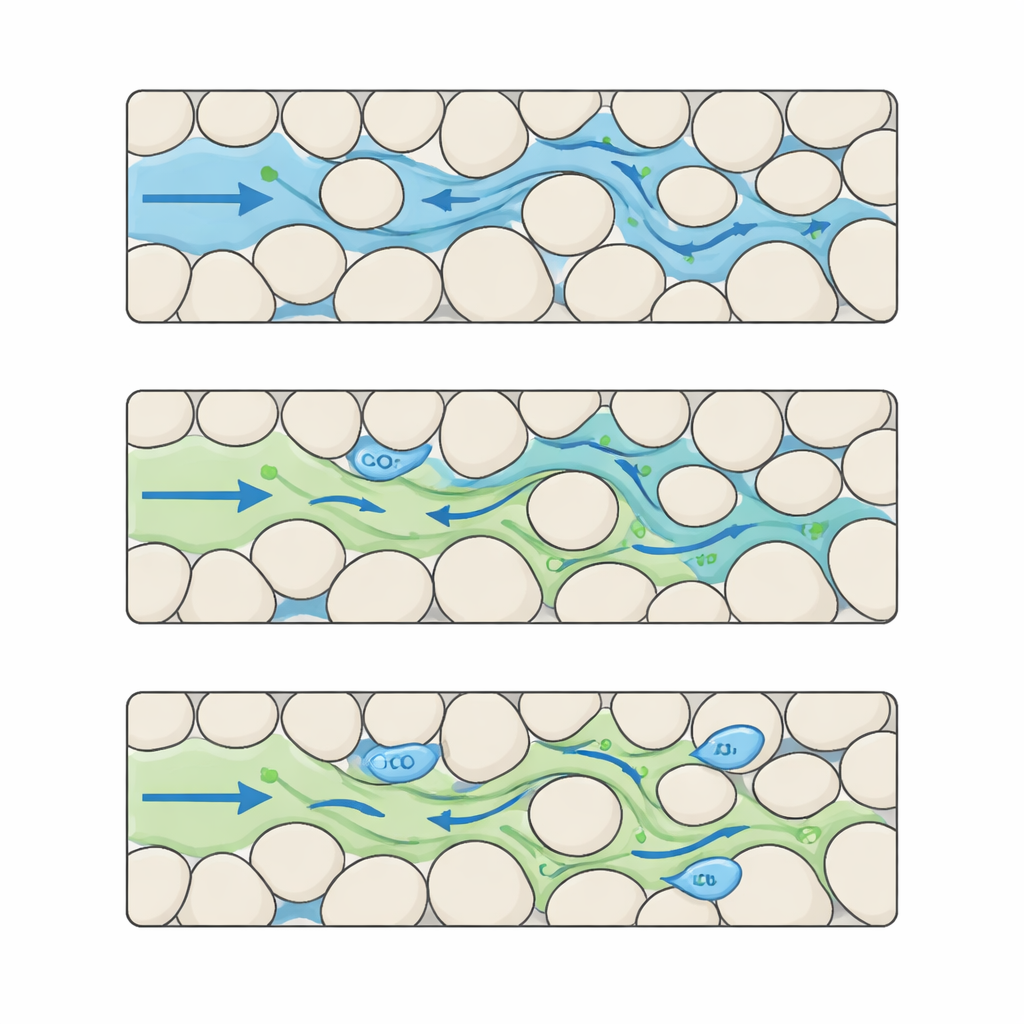
Att bygga en detaljerad film av CO2 och vatten i komplexa porer
Författarna tar sig an denna lucka genom att sammanställa en referensdatamängd som fångar CO2–vatteninteraktion på mycket hög detaljnivå. De börjar med att skapa många syntetiska ”berg” som pixelbaserade kartor där fasta korn och öppna porer läggs ut i olika mönster. Genom att noggrant variera kornstorlek och avstånd skapar de fem distinkta nivåer av strukturell komplexitet, från välordnade till mycket oregelbundna. För var och en av dessa digitala berg körs avancerade simuleringar där CO2 kommer in från ena sidan och tränger undan vatten genom poresystemet. Varje körning ger 100 jämnt fördelade tidsbilder, inspelade på ett 512 × 512 pixlars rutnät med mikrometerskala upplösning, och spårar var CO2 och vatten befinner sig, hur trycket förändras och hur vätskans hastigheter varierar genom labyrinten.
Vad datamängden innehåller och hur den kan användas
Den resulterande samlingen innehåller 624 unika porestrukturer, vardera kopplad till en full tidsserie av vätskebeteende. För varje prov tillhandahåller datamängden bilder av bergskelettet, andelen av varje pixel som är fylld med vatten, samt tryck- och flödesfält i både horisontell och vertikal riktning. Ytterligare tabeller listar bulkegenskaper såsom porositet (hur mycket tomrum berget har) och permeabilitet (hur lätt vätskor kan röra sig), tillsammans med mått som ingenjörer använder för att beskriva flödesmotstånd. Allt är lagrat i standardiserade vetenskapliga filformat, vilket gör det enkelt för forskare att ansluta till sina egna kodbaser. Denna struktur tillåter maskininlärningsmodeller att tränas inte bara för att gissa slutresultat, utan också för att stegvis förutsäga i tiden — att prognostisera hur en CO2-släpp utvecklas från ett ögonblick till nästa.
Testa om variation förbättrar inlärningen
För att visa varför denna mångfald är viktig tränar författarna tre versioner av ett populärt bildbaserat neuralt nätverk på olika snitt av datamängden. En version ser alla fem nivåer av bergskomplexitet, en annan ser bara fyra, och en tredje ser endast en, den enklaste nivån. När dessa modeller ombeds att förutsäga CO2-mönster i de mest komplexa bergen presterar den som tränats på den rikaste variationen bäst i genomsnitt och återger de simulerade släppformerna mer troget över många tidssteg. Modellerna som exponerats för snävare träningsexempel gör större misstag, särskilt när förutsägelser drivs längre fram i tiden. Samtidigt finner författarna att mer variation inte garanterar förbättring i varje enskilt fall, vilket antyder att det finns en balans mellan rikedom och överkomplicering i utformningen av träningsdata.
Vad detta innebär för framtida koldioxidlagring
Kort sagt erbjuder detta arbete ett högkvalitativt ”övningsfält” för algoritmer som en dag kommer att hjälpa till att utforma och övervaka projekt för underjordisk CO2-lagring. Genom att erbjuda många detaljerade exempel på hur CO2 och vatten väver sig genom realistiska poresystem hjälper datamängden maskininlärningsverktyg att lära sig spelets regler snarare än att memorera några få uppställningar. Huvudslutsatsen är att ett omfamnande av den röriga variationen i verkliga berg i träningsdata leder till bättre genomsnittliga förutsägelser av hur injicerad CO2 kommer att röra sig och fångas. Det kan i sin tur stödja mer tillförlitliga och effektiva beslut om var och hur man säkert lagrar koldioxid under våra fötter.
Citering: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Nyckelord: koldioxidlagring, porösa bergarter, maskininlärning, flöde i porskala, CO2-injektion