Clear Sky Science · de
Ein Benchmark-Datensatz für Machine-Learning-Surrogate der CO2‑Wasser‑Interaktion auf Porenmaßstab
Warum die unterirdische Speicherung von Kohlenstoff bessere Bilder braucht
Wenn wir über den Kampf gegen den Klimawandel sprechen, ist eine große Idee, Kohlendioxid (CO2) aus Schornsteinen abzuscheiden und tief unter der Erde zu lagern. Unterirdische Gesteine sind jedoch keine glatten Tanks — sie ähneln komplexen Schwämmen voller winziger Windungen, in denen Wasser und CO2 um Raum kämpfen. Diese Arbeit stellt einen neuen, detaillierten digitalen „Film“ vor, der zeigt, wie CO2 Wasser durch diese feinen Poren verdrängt, und liefert Forschenden das Rohmaterial, das sie brauchen, um schnellere Computermodelle zu bauen, die vorhersagen können, ob die unterirdische Speicherung CO2 tatsächlich sicher einschließt.
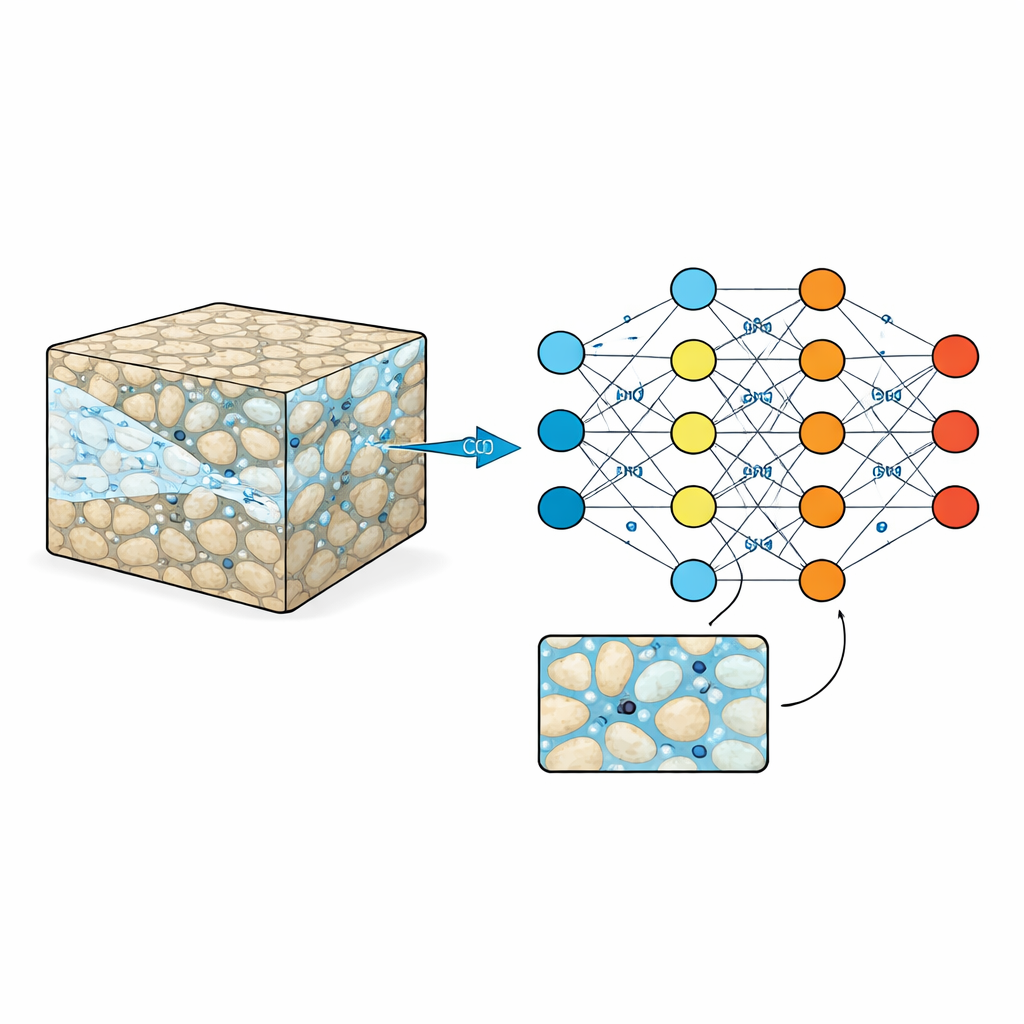
Im Schwamm des Gesteins nachsehen
Unterirdische Reservoirs wie Sandstein oder vulkanische Gesteine sind von mikroskopischen Poren durchzogen, die mit Wasser gefüllt sind. Wenn CO2 injiziert wird, muss es sich durch dieses Labyrinth winden, manchmal in Kanälen schnell vorstoßen, manchmal in Sackgassen steckenbleiben. Diese feinkörnigen Muster kontrollieren, wie viel CO2 gespeichert werden kann und wie sicher diese Speicherung über Jahrzehnte bis Jahrhunderte ist. Traditionelle Laborexperimente und Bildgebungsverfahren können erahnen, was in wenigen kleinen Proben geschieht, während hochpräzise Computersimulationen jedes Detail verfolgen können — allerdings zu hohen Kosten in Zeit und Rechenleistung. Daher verlassen sich Ingenieure oft auf vereinfachte Formeln, die das unordentliche Kleinmaß ausblenden und dabei wichtige Verhaltensweisen übersehen können.
Warum intelligente Surrogate reichhaltige Trainingsdaten brauchen
Modelle des maschinellen Lernens versprechen eine Abkürzung: Einmal trainiert, können sie wesentlich schneller vorhersagen, wie sich CO2 durch Gestein bewegt als vollständige physikbasierte Simulationen. Doch wie jeder Lernende sind diese Modelle nur so gut wie die Beispiele, die sie sehen. Viele bestehende Datensätze sind zu klein, decken nur einfache Gesteinsmuster ab oder zeichnen nur das Endresultat einer Injektion auf, nicht den zeitlichen Ablauf. Das erschwert es Algorithmen, die sich verändernden Formen von CO2‑Wolken, Druckaufbau oder wie subtile Veränderungen in der Gesteinsstruktur den Fluss beeinflussen, zu erlernen. Ohne reichhaltigeres Trainingsmaterial laufen intelligente Surrogate Gefahr, übermäßig selbstsichere, aber unzuverlässige Vorhersagen für neue, komplexere Gesteinsformationen zu liefern.
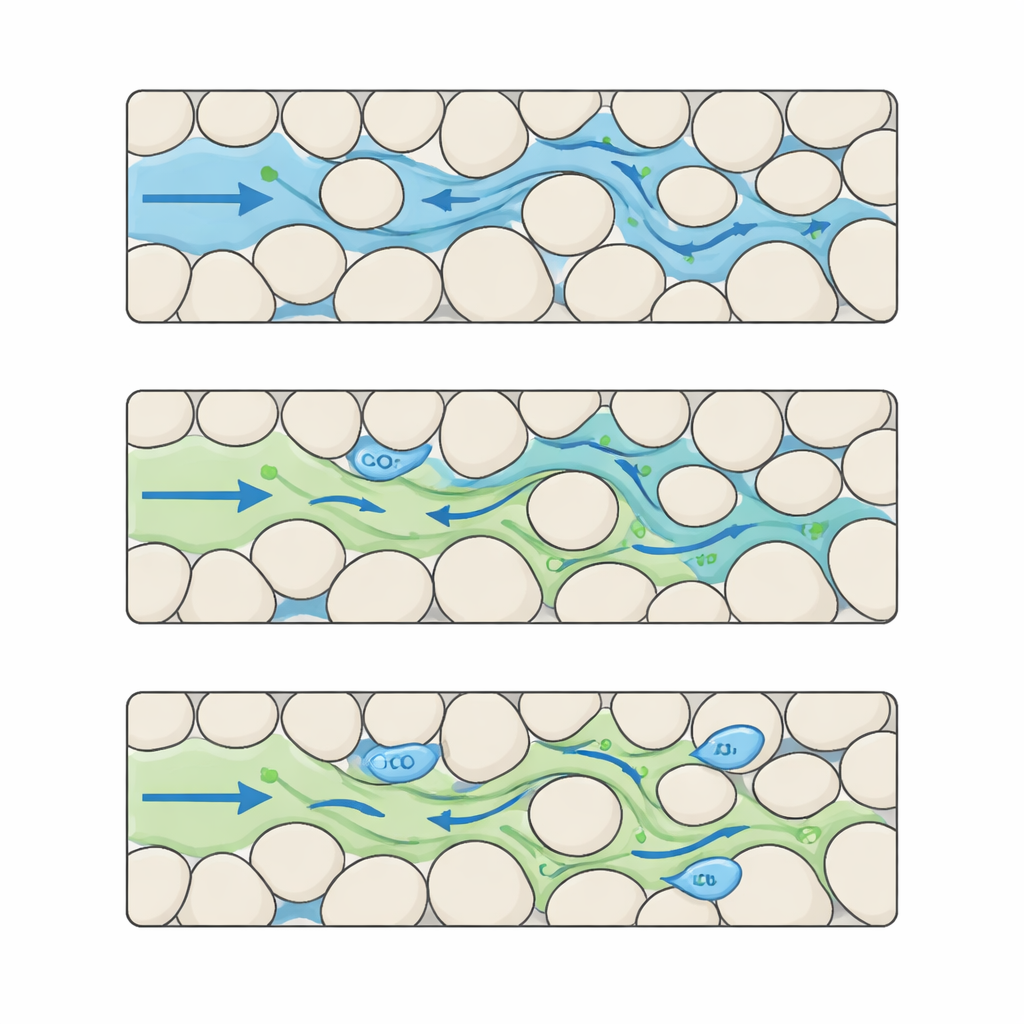
Ein detaillierter Film von CO2 und Wasser in komplexen Poren
Die Autorinnen und Autoren schließen diese Lücke, indem sie einen Benchmark‑Datensatz zusammenstellen, der die CO2–Wasser‑Interaktion auf sehr feiner Ebene erfasst. Sie beginnen damit, viele synthetische „Gesteine“ als pixelbasierte Karten zu erzeugen, auf denen feste Körner und offene Poren in unterschiedlichen Mustern angeordnet sind. Durch gezielte Variation von Korngröße und Abstand erzeugen sie fünf verschiedene Stufen struktureller Komplexität, von gut geordnet bis hochgradig unregelmäßig. Für jedes dieser digitalen Gesteine führen sie fortgeschrittene Simulationen durch, in denen CO2 von einer Seite eintritt und Wasser durch den Porenraum verdrängt. Jeder Durchlauf liefert 100 gleichmäßig verteilte Zeitaufnahmen, aufgezeichnet auf einem 512 × 512 Pixel‑Raster mit Mikrometerauflösung, wobei festgehalten wird, wo CO2 und Wasser liegen, wie sich der Druck verändert und wie sich die Flussgeschwindigkeiten durch das Labyrinth variieren.
Was der Datensatz enthält und wie er genutzt werden kann
Die resultierende Sammlung umfasst 624 einzigartige Porenstrukturen, jeweils gepaart mit einer vollständigen Zeitreihe des Fluidverhaltens. Für jede Probe liefert der Datensatz Bilder des Gesteinsskeletts, den Anteil jedes Pixels, der mit Wasser gefüllt ist, sowie Druck‑ und Strömungsfelder in horizontaler und vertikaler Richtung. Zusätzliche Tabellen listen makroskopische Eigenschaften wie Porosität (wie viel Leerraum das Gestein hat) und Permeabilität (wie leicht sich Fluide bewegen können) sowie Kenngrößen auf, die Ingenieure zur Beschreibung des Strömungswiderstands verwenden. Alles ist in gängigen wissenschaftlichen Dateiformaten gespeichert, sodass Forschende es leicht in ihre eigenen Codes einbinden können. Diese Struktur erlaubt es, Maschinenlernmodelle nicht nur darauf zu trainieren, Endergebnisse zu erraten, sondern auch zeitschrittweise vorwärtszusagen — also wie sich eine CO2‑Plume von einem Zeitpunkt zum nächsten entwickelt.
Prüfen, ob Vielfalt das Lernen verbessert
Um zu zeigen, warum diese Vielfalt wichtig ist, trainieren die Autorinnen und Autoren drei Versionen eines populären bildbasierten neuronalen Netzes mit unterschiedlichen Ausschnitten des Datensatzes. Eine Version sieht alle fünf Komplexitätsstufen, eine andere nur vier und eine dritte nur die einfachste Stufe. Wenn diese Modelle aufgefordert werden, CO2‑Muster in den komplexesten Gesteinen vorherzusagen, schneidet das auf der reichhaltigsten Vielfalt trainierte Modell im Mittel am besten ab und reproduziert die simulierten Plume‑Formen über viele Zeitschritte am treuesten. Die Modelle, die nur engere Trainingsbeispiele gesehen haben, machen größere Fehler, besonders je weiter die Vorhersagen in die Zukunft reichen. Gleichzeitig zeigen die Autorinnen und Autoren, dass mehr Vielfalt nicht in jedem einzelnen Fall eine Verbesserung garantiert, was darauf hindeutet, dass ein Gleichgewicht zwischen Reichhaltigkeit und Überkomplexität bei der Gestaltung von Trainingsdaten besteht.
Was das für die zukünftige Kohlenstoffspeicherung bedeutet
Einfach ausgedrückt liefert diese Arbeit ein hochwertiges „Spielfeld“ für Algorithmen, die eines Tages bei der Planung und Überwachung unterirdischer CO2‑Speicherprojekte helfen sollen. Indem sie viele detaillierte Beispiele dafür bietet, wie CO2 und Wasser durch realistische Porennetzwerke wandern, hilft der Datensatz maschinellen Lernwerkzeugen, die Spielregeln zu erlernen, statt nur ein paar Abläufe auswendig zu lernen. Die wichtigste Erkenntnis ist, dass das Einbeziehen der unordentlichen Variabilität realer Gesteine in Trainingsdaten zu besseren mittleren Vorhersagen darüber führt, wie injiziertes CO2 wandert und eingeschlossen wird. Das wiederum kann zu zuverlässigeren und effizienteren Entscheidungen darüber beitragen, wo und wie Kohlenstoff sicher unter unseren Füßen gespeichert werden sollte.
Zitation: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Schlüsselwörter: Kohlenstoffspeicherung, poröse Gesteine, maschinelles Lernen, Strömung auf Porenmaßstab, CO2‑Injektion