Clear Sky Science · fr
Un jeu de données de référence pour des substituts d’apprentissage automatique des interactions CO2-eau à l’échelle des pores
Pourquoi le stockage du carbone souterrain a besoin de meilleures images
Quand on parle de lutter contre le changement climatique, une grande idée consiste à capter le dioxyde de carbone (CO2) des cheminées industrielles et à le stocker profondément sous terre. Mais les roches souterraines ne sont pas des réservoirs lisses — elles ressemblent plutôt à des éponges complexes remplies de minuscules méandres où l’eau et le CO2 se disputent l’espace. Cet article présente un nouveau « film » numérique détaillé montrant comment le CO2 pousse l’eau à travers ces pores microscopiques, fournissant aux chercheurs la matière première nécessaire pour construire des modèles informatiques plus rapides capables de prédire si le stockage souterrain retiendra effectivement le CO2 en toute sécurité.
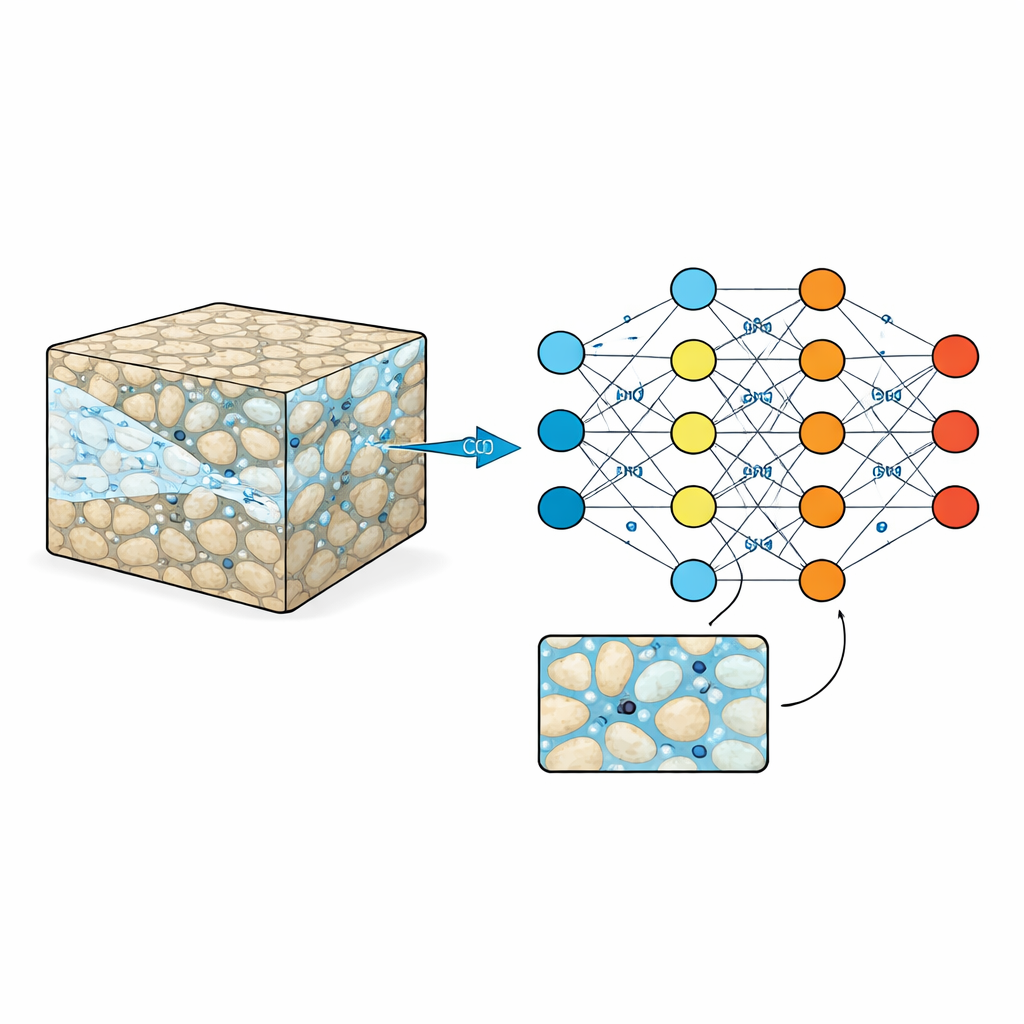
Regarder à l’intérieur de l’éponge rocheuse
Les réservoirs souterrains, comme le grès ou les roches volcaniques, sont parcourus de pores microscopiques remplis d’eau. Lorsque le CO2 est injecté, il doit se frayer un chemin dans ce labyrinthe, parfois en avançant rapidement dans des canaux et parfois en restant coincé dans des impasses. Ces motifs à petite échelle contrôlent la quantité de CO2 qui peut être stockée et la sécurité de ce stockage sur des décennies à des siècles. Les expériences de laboratoire traditionnelles et l’imagerie peuvent entrevoir ce qui se passe dans quelques petits échantillons, tandis que des simulations informatiques de haute précision suivent chaque détail — mais au prix d’un coût élevé en temps et en puissance de calcul. Par conséquent, les ingénieurs s’appuient souvent sur des formules simplifiées qui estompent l’image désordonnée à petite échelle, ce qui peut faire manquer des comportements importants.
Pourquoi les substituts intelligents ont besoin de données d’entraînement riches
Les modèles d’apprentissage automatique promettent un raccourci : une fois entraînés, ils peuvent prédire beaucoup plus rapidement que des simulations physiques complètes comment le CO2 se déplacera à travers la roche. Mais comme tout élève, ces modèles ne valent guère mieux que les exemples qu’ils voient. Beaucoup de jeux de données existants sont trop petits, ne couvrent que des motifs rocheux simples, ou n’enregistrent que le résultat final d’une injection, et non la manière dont le processus se déroule dans le temps. Cela rend difficile pour les algorithmes d’apprendre les formes changeantes des panaches de CO2, l’accumulation de pression ou la façon dont de subtiles variations de la structure de la roche influent sur l’écoulement. Sans matériel d’entraînement plus riche, les substituts intelligents risquent de produire des prédictions assurées mais peu fiables lorsqu’ils sont confrontés à de nouvelles formations rocheuses plus complexes.
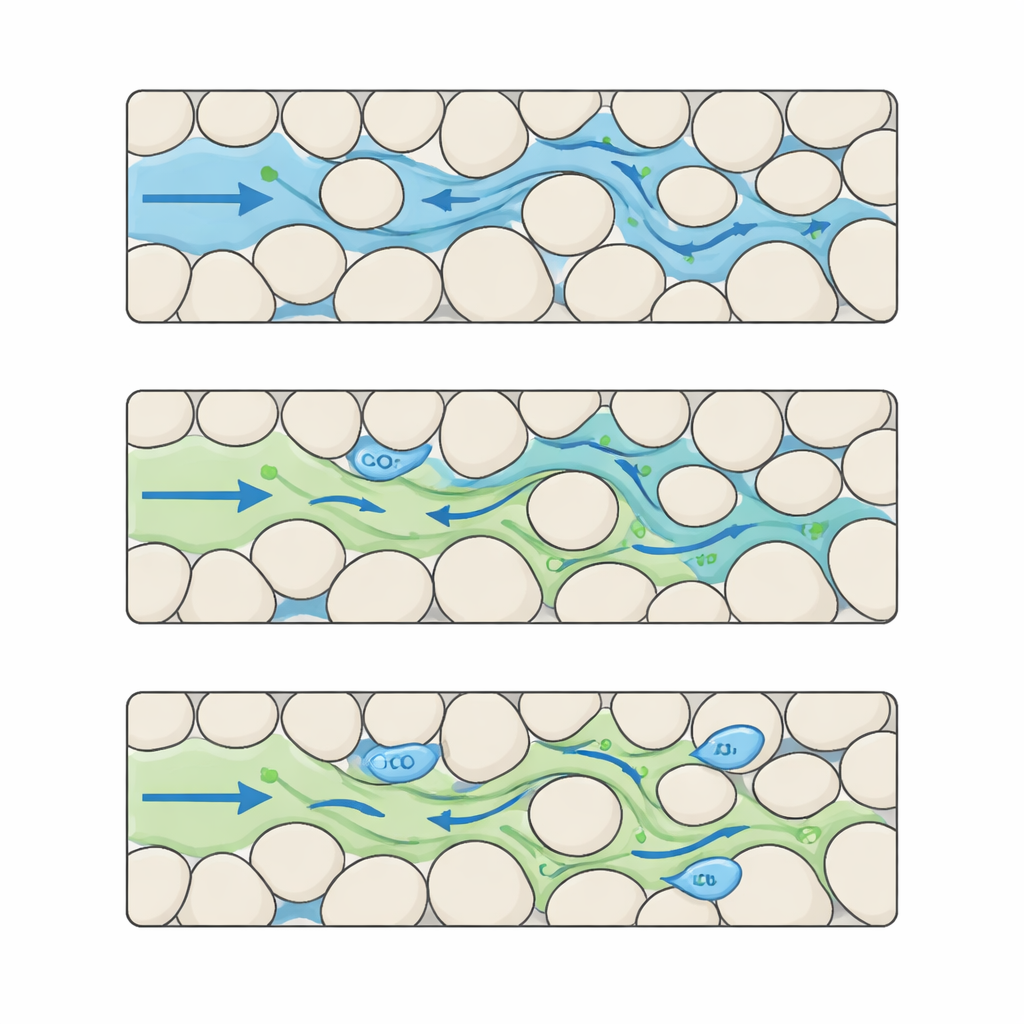
Construire un film détaillé du CO2 et de l’eau dans des pores complexes
Les auteurs comblent cette lacune en assemblant un jeu de données de référence qui capture l’interaction CO2–eau à un niveau de détail très fin. Ils commencent par créer de nombreuses « roches » synthétiques sous forme de cartes en pixels où les grains solides et les pores ouverts sont disposés selon différents motifs. En modifiant soigneusement la taille et l’espacement des grains, ils génèrent cinq niveaux distincts de complexité structurelle, allant d’un ordre bien établi à une grande irrégularité. Pour chacune de ces roches numériques, ils exécutent des simulations avancées dans lesquelles le CO2 entre par un côté et déplace l’eau à travers l’espace poreux. Chaque simulation produit 100 instantanés temporels régulièrement espacés, enregistrés sur une grille de 512 × 512 pixels avec une résolution à l’échelle micrométrique, suivant la répartition du CO2 et de l’eau, l’évolution de la pression et les variations de vitesse des fluides dans tout le labyrinthe.
Ce que contient le jeu de données et comment il peut être utilisé
La collection résultante comprend 624 structures de pores uniques, chacune associée à une série temporelle complète du comportement des fluides. Pour chaque échantillon, le jeu de données fournit des images du squelette rocheux, la fraction de chaque pixel remplie d’eau, ainsi que les champs de pression et d’écoulement en directions horizontale et verticale. Des tableaux supplémentaires listent des propriétés globales telles que la porosité (la quantité d’espace vide dans la roche) et la perméabilité (la facilité de déplacement des fluides), ainsi que des grandeurs utilisées par les ingénieurs pour décrire la résistance à l’écoulement. Tout est stocké dans des formats de fichiers scientifiques standards, facilitant l’intégration par les chercheurs dans leurs propres codes. Cette structure permet aux modèles d’apprentissage automatique d’être entraînés non seulement pour deviner les résultats finaux, mais aussi pour avancer dans le temps — en prédisant comment un panache de CO2 évolue d’un instant à l’autre.
Tester si la diversité améliore l’apprentissage
Pour montrer pourquoi cette diversité est importante, les auteurs entraînent trois versions d’un réseau neuronal populaire basé sur l’image avec différents sous-ensembles du jeu de données. Une version voit les cinq niveaux de complexité rocheuse, une autre n’en voit que quatre, et une troisième ne voit qu’un seul niveau, le plus simple. Lorsqu’on demande à ces modèles de prédire les motifs de CO2 dans les roches les plus complexes, celui entraîné sur la variété la plus riche donne en moyenne les meilleurs résultats, reproduisant plus fidèlement les formes du panache simulé sur de nombreux pas de temps. Les modèles exposés à des exemples d’entraînement plus restreints commettent des erreurs plus importantes, surtout lorsque les prédictions sont poussées plus loin dans le futur. Parallèlement, les auteurs constatent qu’une plus grande diversité n’assure pas une amélioration pour chaque cas isolé, suggérant qu’il existe un équilibre entre richesse et surcomplexification dans la conception des jeux de données d’entraînement.
Ce que cela signifie pour le stockage futur du carbone
Sans détours, ce travail fournit un « terrain d’entraînement » de haute qualité pour des algorithmes qui, un jour, aideront à concevoir et surveiller des projets de stockage souterrain de CO2. En offrant de nombreux exemples détaillés de la manière dont le CO2 et l’eau se faufilent à travers des réseaux de pores réalistes, le jeu de données aide les outils d’apprentissage automatique à apprendre les règles du jeu plutôt qu’à mémoriser quelques scénarios. L’idée principale est que l’intégration de la variabilité désordonnée des roches réelles dans les données d’entraînement conduit à de meilleures prédictions moyennes de la manière dont le CO2 injecté se déplacera et sera piégé. Cela peut, à son tour, soutenir des décisions plus fiables et efficaces sur l’endroit et la manière de stocker le carbone en toute sécurité sous nos pieds.
Citation: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Mots-clés: stockage du carbone, roches poreuses, apprentissage automatique, écoulement à l’échelle des pores, injection de CO2