Clear Sky Science · pl
Zestaw danych referencyjnych dla surrogatów uczenia maszynowego opisujących oddziaływanie CO2 i wody w skali porów
Dlaczego potrzeba lepszych obrazów, by przechowywać węgiel pod ziemią
Gdy mówimy o walce ze zmianami klimatu, jedną z głównych idei jest wychwytywanie dwutlenku węgla (CO2) z kominów i magazynowanie go głęboko pod ziemią. Ale podziemne skały to nie gładkie zbiorniki — przypominają raczej misterną gąbkę pełną drobnych zakrętów, gdzie woda i CO2 walczą o przestrzeń. Artykuł przedstawia nowy, szczegółowy cyfrowy „film” pokazujący, jak CO2 wypiera wodę przez te maleńkie pory, dostarczając badaczom surowych danych potrzebnych do tworzenia szybszych modeli komputerowych, które potrafią przewidzieć, czy magazynowanie podziemne rzeczywiście zatrzyma CO2 na długo.
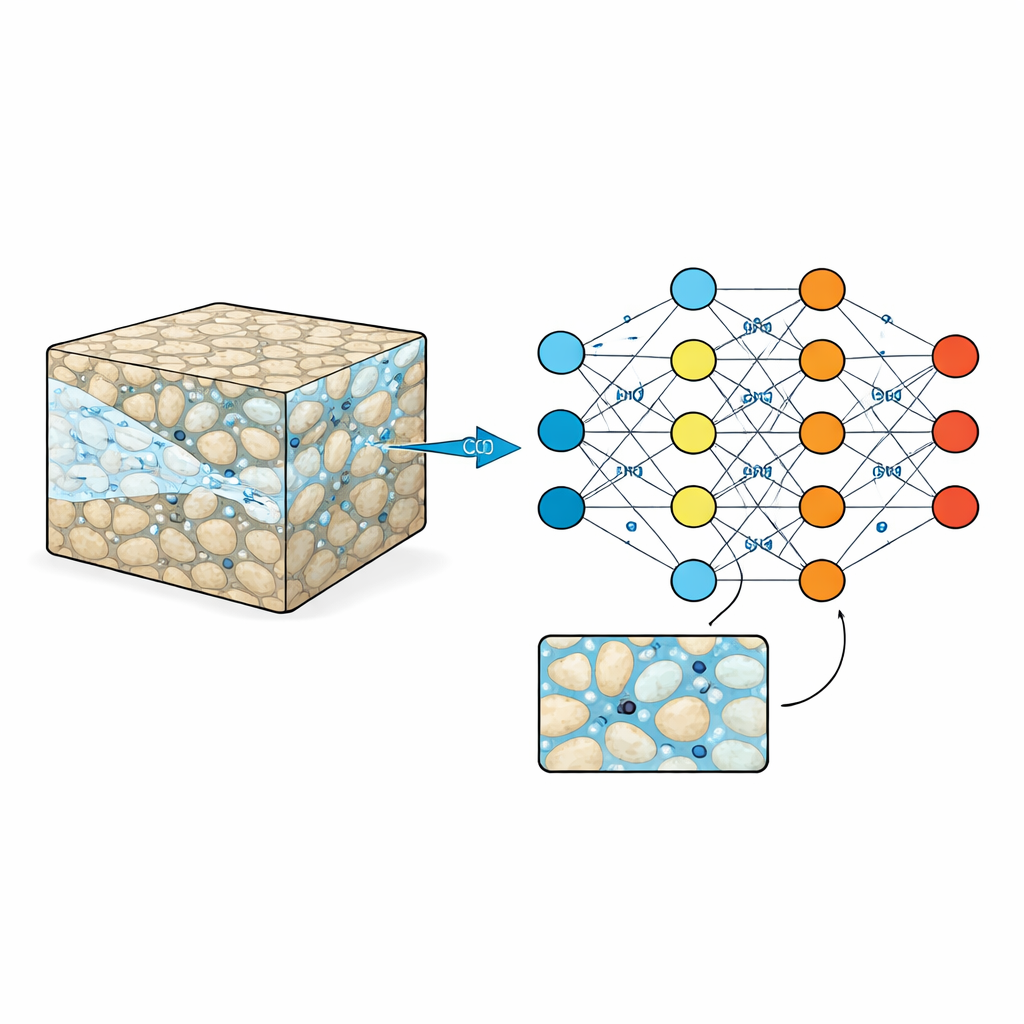
Zajrzeć do skalnej gąbki
Rekawacje podziemne, takie jak piaskowce czy skały wulkaniczne, są poprzecinane mikroskopijnymi porami wypełnionymi wodą. Kiedy pompuje się CO2, musi się przedzierać przez ten labirynt, czasem pędząc kanałami, innym razem ugrzęznąć w ślepych zaułkach. Te drobne wzory decydują o tym, ile CO2 można przechować i jak bezpieczne będzie to magazynowanie przez dziesięciolecia czy wieki. Tradycyjne eksperymenty laboratoryjne i obrazowanie pozwalają zajrzeć, co dzieje się w kilku małych próbkach, a wysokiej precyzji symulacje komputerowe śledzą każdy szczegół — ale kosztem czasu i mocy obliczeniowej. W efekcie inżynierowie często polegają na uproszczonych wzorach, które wygładzają złożony obraz małej skali i mogą pominąć istotne zachowania.
Dlaczego inteligentne surrogaty potrzebują bogatych danych treningowych
Modele uczenia maszynowego obiecują skrót: po wytrenowaniu potrafią przewidzieć, jak CO2 będzie się poruszać w skale znacznie szybciej niż pełne symulacje oparte na prawach fizyki. Ale podobnie jak każdy uczeń, modele te są tak dobre, jak przykłady, które widziały. Wiele istniejących zbiorów danych jest zbyt małych, obejmuje tylko proste wzory skał lub rejestruje jedynie końcowy rezultat wstrzyknięcia, a nie przebieg procesu w czasie. To utrudnia algorytmom naukę zmieniających się kształtów pióropuszy CO2, narastania ciśnienia czy wpływu subtelnych różnic w strukturze skały na przepływ. Bez bogatszych materiałów treningowych inteligentne surrogaty ryzykują dawanie pewnych, lecz zawodnych prognoz wobec nowych, bardziej złożonych formacji skalnych.
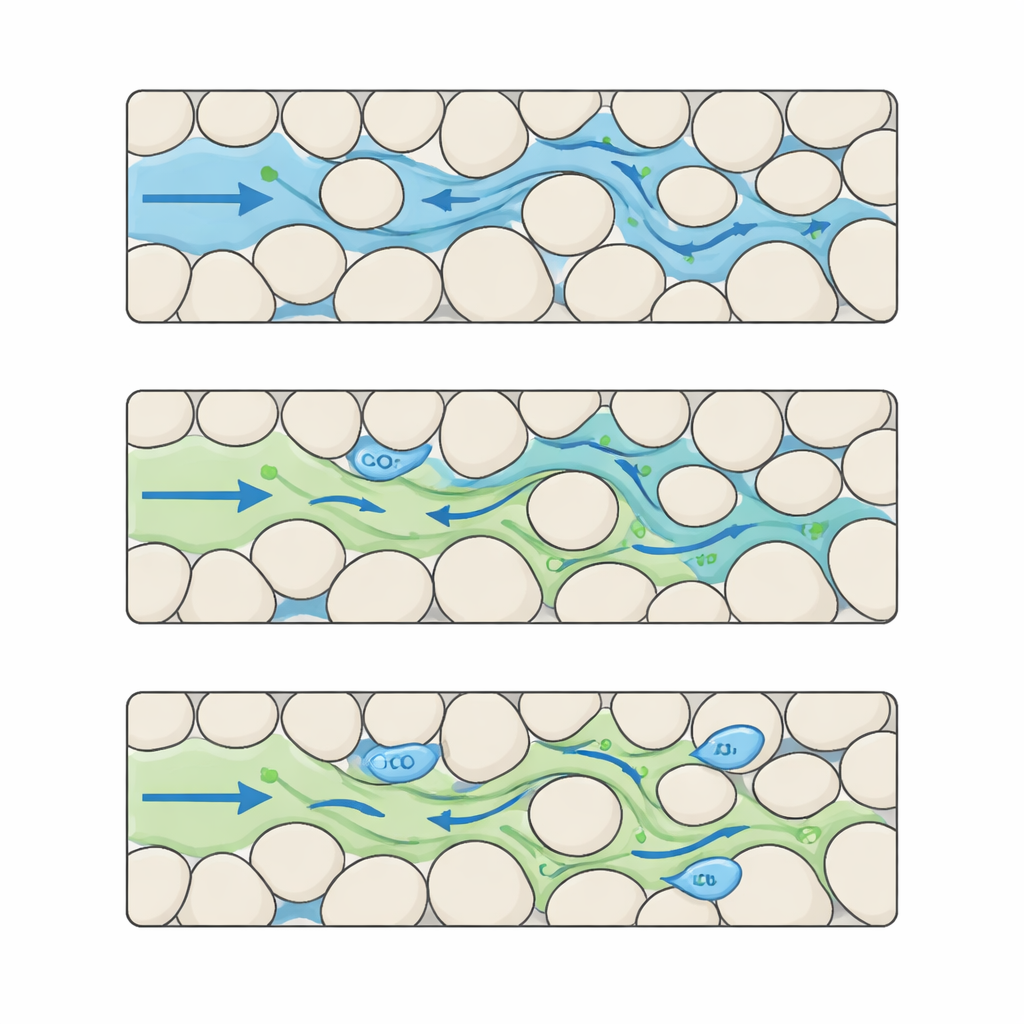
Budowanie szczegółowego filmu CO2 i wody w złożonych porach
Autorzy wypełniają tę lukę, tworząc zestaw danych referencyjnych, który uchwyca oddziaływanie CO2 i wody na bardzo drobnym poziomie szczegółu. Rozpoczynają od stworzenia wielu syntetycznych „skał” w postaci map pikselowych, gdzie ziarniste ciała stałe i otwarte pory rozmieszczono w różnych układach. Poprzez staranne zmiany wielkości i odstępów ziaren generują pięć odrębnych poziomów złożoności strukturalnej, od dobrze uporządkowanych po silnie nieregularne. Dla każdej z tych cyfrowych skał uruchamiają zaawansowane symulacje, w których CO2 wchodzi z jednej strony i wypiera wodę przez przestrzeń porową. Każde uruchomienie daje 100 równomiernie rozmieszczonych migawkowych zapisów w czasie, zapisanych na siatce 512 × 512 pikseli z rozdzielczością rzędu mikrometrów, śledząc rozmieszczenie CO2 i wody, zmiany ciśnienia oraz zmiany prędkości płynów w całym labiryncie.
Co zawiera zestaw danych i jak można go wykorzystać
W rezultacie powstała kolekcja obejmuje 624 unikalne struktury porowe, z których każda powiązana jest z pełnym szeregiem czasowym zachowania płynów. Dla każdej próbki zestaw danych dostarcza obrazy szkieletu skały, ułamek każdego piksela zajęty przez wodę, a także pola ciśnienia i pola przepływu w kierunkach poziomym i pionowym. Dodatkowe tabele zawierają właściwości makroskopowe, takie jak porowatość (ile pustej przestrzeni ma skała) i przepuszczalność (jak łatwo płyny mogą się poruszać), wraz z miarami używanymi przez inżynierów do opisu oporu przepływu. Wszystko jest przechowywane w standardowych naukowych formatach plików, co ułatwia badaczom podłączenie ich do własnych kodów. Taka struktura pozwala trenować modele uczenia maszynowego nie tylko do zgadywania końcowych rezultatów, ale także do krokowego prognozowania w czasie — przewidywania, jak pióropusz CO2 zmienia się z chwili na chwilę.
Testowanie, czy różnorodność poprawia uczenie
Aby pokazać, dlaczego ta różnorodność ma znaczenie, autorzy trenują trzy wersje popularnej sieci neuronowej pracującej na obrazach, używając różnych wycinków zestawu danych. Jedna wersja widzi wszystkie pięć poziomów złożoności skał, inna tylko cztery, a trzecia jedynie najprostszy poziom. Gdy poproszono te modele o przewidywanie wzorców CO2 w najbardziej złożonych skałach, najlepiej wypadła ta wytrenowana na najbogatszej różnorodności — średnio najwierniej odtwarzała kształty symulowanych pióropuszy na wielu krokach czasowych. Modele eksponowane na węższych przykładach treningowych popełniały większe błędy, szczególnie gdy prognozy były przesuwane dalej w przyszłość. Jednocześnie autorzy zauważają, że większa różnorodność nie gwarantuje poprawy w każdym pojedynczym przypadku, co sugeruje, że istnieje równowaga między bogactwem a nadmiernym skomplikowaniem w projektowaniu danych treningowych.
Co to oznacza dla przyszłego magazynowania węgla
Mówiąc prosto, praca ta dostarcza wysokiej jakości „pole do ćwiczeń” dla algorytmów, które kiedyś pomogą projektować i monitorować podziemne projekty składowania CO2. Dostarczając wiele szczegółowych przykładów tego, jak CO2 i woda przeplatają się w realistycznych sieciach porowych, zestaw danych pomaga narzędziom uczenia maszynowego poznać reguły gry, zamiast zapamiętywać kilka zagrań. Główny wniosek jest taki, że uwzględnianie złożonej zmienności prawdziwych skał w danych treningowych prowadzi do lepszych średnich prognoz dotyczących przemieszczania się i uwięzienia wstrzykniętego CO2. To z kolei może wspierać bardziej wiarygodne i efektywne decyzje o tym, gdzie i jak bezpiecznie magazynować węgiel pod naszymi stopami.
Cytowanie: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Słowa kluczowe: magazynowanie dwutlenku węgla, skały porowate, uczenie maszynowe, przepływ w skali porów, wstrzykiwanie CO2