Clear Sky Science · it
Un set di dati di riferimento per surrogate di apprendimento automatico delle interazioni CO2-acqua a scala porosa
Perché conservare il carbonio sottoterra richiede immagini migliori
Quando si parla di contrastare il cambiamento climatico, una grande idea è catturare anidride carbonica (CO2) dalle emissioni e immagazzinarla in profondità sotto terra. Ma le rocce sotterranee non sono serbatoi lisci: somigliano piuttosto a spugne intricate piene di piccoli tortuosi passaggi dove acqua e CO2 si contendono lo spazio. Questo articolo presenta un nuovo, dettagliato "film" digitale di come la CO2 spinga via l’acqua attraverso questi pori microscopici, fornendo ai ricercatori il materiale grezzo necessario per costruire modelli informatici più veloci in grado di prevedere se lo stoccaggio sotterraneo manterrà effettivamente la CO2 bloccata in sicurezza.
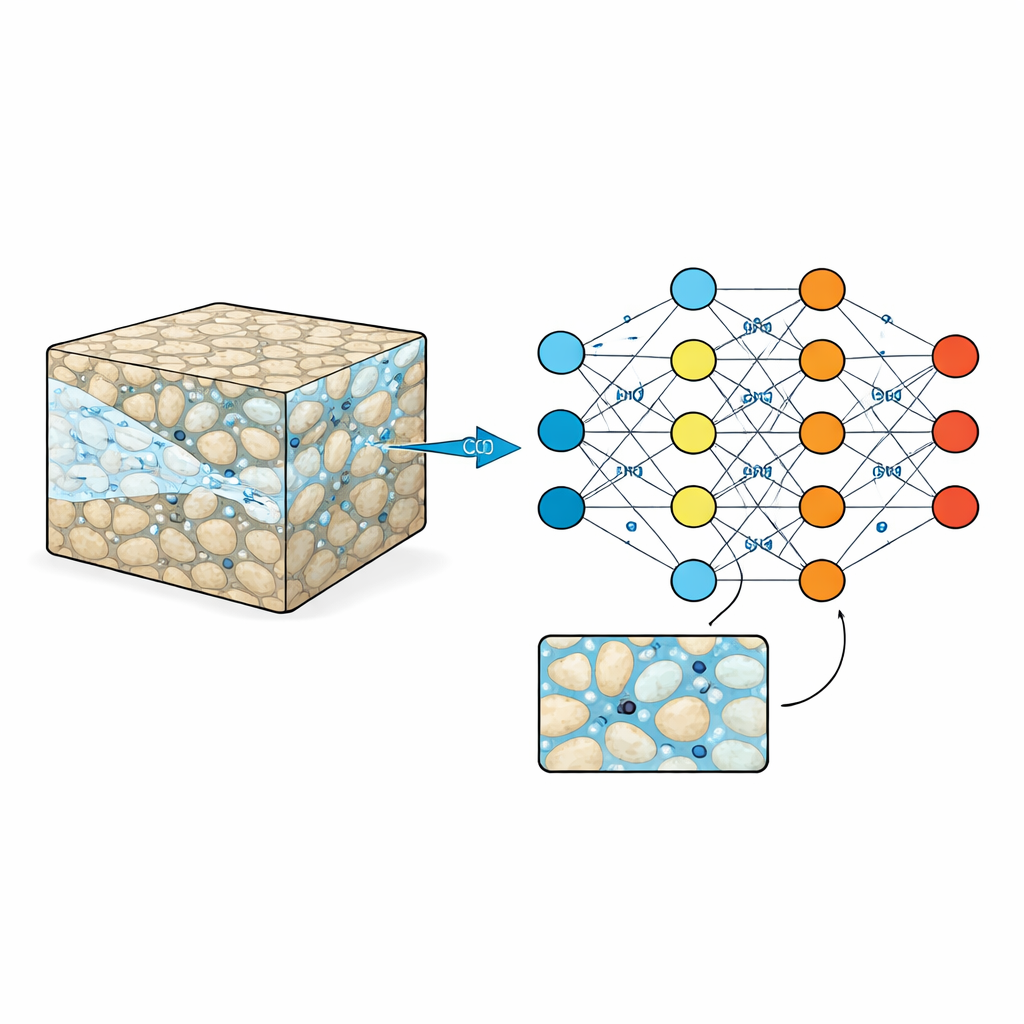
Osservare la spugna rocciosa
I serbatoi sotterranei come arenarie o rocce vulcaniche sono attraversati da pori microscopici pieni d’acqua. Quando la CO2 viene pompata, deve farsi strada attraverso questo labirinto, a volte correndo in canali preferenziali e a volte rimanendo bloccata in vicoli ciechi. Questi schemi a piccola scala controllano quanto CO2 può essere immagazzinata e quanto sicuro sarà lo stoccaggio nel corso di decenni o secoli. Gli esperimenti di laboratorio tradizionali e le immagini possono intravedere ciò che accade in pochi campioni, mentre le simulazioni numeriche ad alta precisione possono seguire ogni dettaglio—ma a costo elevato in tempo e potenza di calcolo. Di conseguenza, gli ingegneri spesso si affidano a formule semplificate che sfumano il quadro microscopico disordinato, rischiando di perdere comportamenti importanti.
Perché i surrogate intelligenti hanno bisogno di dati di addestramento ricchi
I modelli di apprendimento automatico promettono una scorciatoia: una volta addestrati, possono prevedere come la CO2 si muoverà nella roccia molto più rapidamente delle simulazioni fisiche complete. Ma, come ogni studente, questi modelli sono buoni quanto gli esempi che osservano. Molti dataset esistenti sono troppo piccoli, coprono solo pattern rocciosi semplici o registrano soltanto il risultato finale di un’iniezione, non il modo in cui il processo si svolge nel tempo. Ciò rende difficile per gli algoritmi apprendere le forme variabili delle plume di CO2, l’accumulo di pressione o come sottili cambiamenti nella struttura della roccia influenzino il flusso. Senza materiale di addestramento più ricco, i surrogate intelligenti rischiano di formulare previsioni sicure ma inaffidabili quando esposti a formazioni rocciose nuove e più complesse.
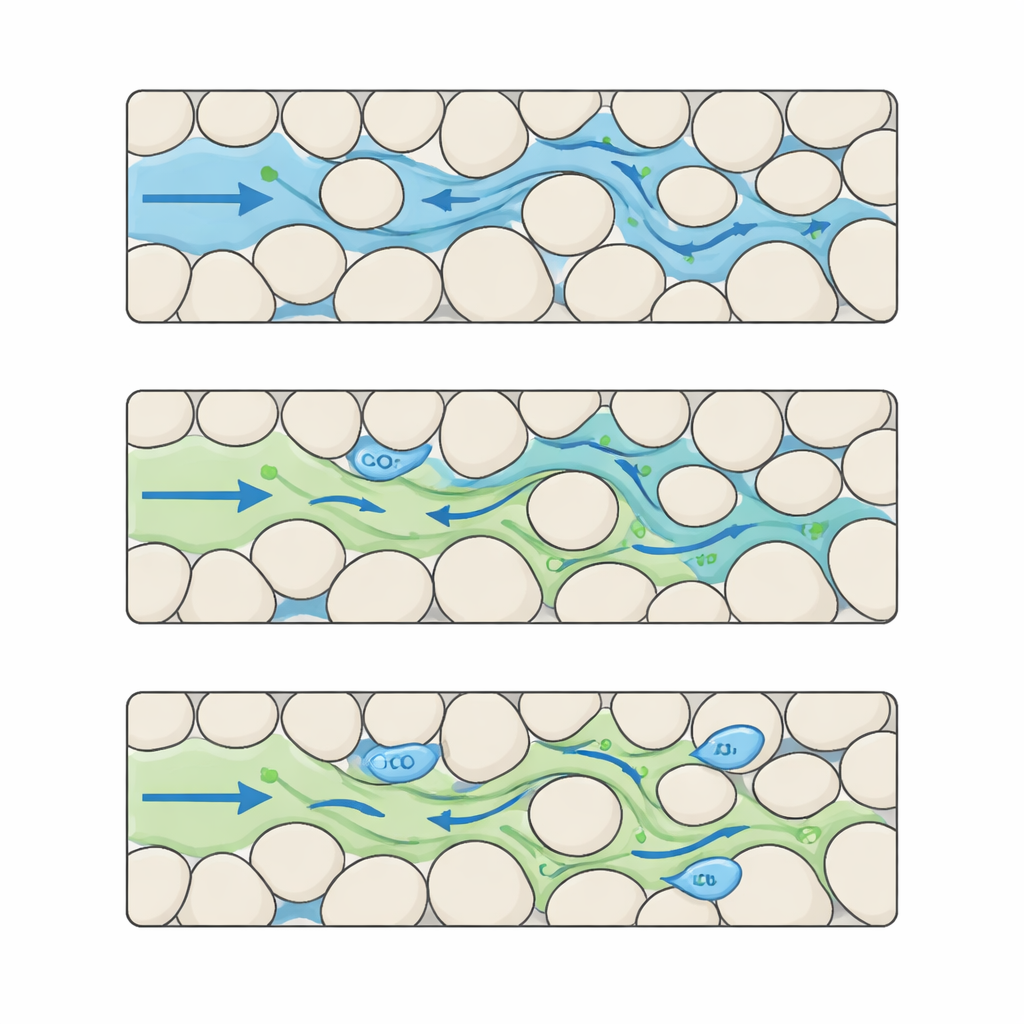
Costruire un film dettagliato di CO2 e acqua in pori complessi
Gli autori colmano questa lacuna assemblando un set di dati di riferimento che cattura l’interazione CO2–acqua a un livello di dettaglio molto fine. Partono creando molti "sassi" sintetici come mappe a pixel in cui i granuli solidi e i pori aperti sono disposti in diversi pattern. Variando con cura la dimensione e la spaziatura dei granuli, generano cinque livelli distinti di complessità strutturale, dall’ordine regolare all’irregolarità elevata. Per ciascuna di queste rocce digitali eseguono simulazioni avanzate in cui la CO2 entra da un lato e scaccia l’acqua attraverso lo spazio poroso. Ogni simulazione produce 100 istantanee equamente distanziate nel tempo, registrate su una griglia di 512 × 512 pixel con risoluzione a scala micrometrica, tracciando dove si trovano CO2 e acqua, come varia la pressione e come cambiano le velocità dei fluidi nel labirinto.
Che cosa contiene il dataset e come può essere usato
La collezione risultante include 624 strutture porose uniche, ciascuna accoppiata con una serie temporale completa del comportamento dei fluidi. Per ogni campione, il dataset fornisce immagini dello scheletro roccioso, la frazione di ogni pixel occupata dall’acqua, oltre ai campi di pressione e di flusso sia orizzontali sia verticali. Tabelle aggiuntive elencano proprietà globali come porosità (quanto spazio vuoto contiene la roccia) e permeabilità (quanto facilmente i fluidi possono muoversi), insieme a misure che gli ingegneri utilizzano per descrivere la resistenza al flusso. Tutto è conservato in formati di file scientifici standard, facilitando l’integrazione nei codici dei ricercatori. Questa struttura permette ai modelli di apprendimento automatico di essere addestrati non solo a indovinare i risultati finali, ma anche a procedere nel tempo—prevedendo come una pluma di CO2 evolve da un istante al successivo.
Testare se la varietà migliora l’apprendimento
Per mostrare perché questa diversità è importante, gli autori addestrano tre versioni di una rete neurale basata su immagini su diverse porzioni del dataset. Una versione vede tutti e cinque i livelli di complessità della roccia, un’altra ne vede solo quattro e una terza vede un unico livello, il più semplice. Quando questi modelli sono chiamati a prevedere i pattern di CO2 nelle rocce più complesse, quella addestrata sulla varietà più ricca ottiene i migliori risultati medi, riproducendo più fedelmente le forme delle plume simulate su molti passi temporali. I modelli esposti a esempi di addestramento più ristretti commettono errori più grandi, specialmente man mano che le previsioni si spingono più avanti nel tempo. Allo stesso tempo, gli autori osservano che maggiore varietà non garantisce miglioramenti in ogni singolo caso, suggerendo che esiste un equilibrio tra ricchezza e sovraccarico nella progettazione dei dati di addestramento.
Che cosa significa per il futuro dello stoccaggio del carbonio
In termini semplici, questo lavoro fornisce un "campo di pratica" di alta qualità per algoritmi che un giorno aiuteranno a progettare e monitorare i progetti di stoccaggio sotterraneo della CO2. Offrendo molti esempi dettagliati di come CO2 e acqua si intrecciano attraverso reti di pori realistiche, il dataset aiuta gli strumenti di apprendimento automatico ad apprendere le regole del gioco anziché memorizzare poche situazioni. La conclusione principale è che abbracciare la variabilità disordinata delle rocce reali nei dati di addestramento porta a previsioni medie migliori su come la CO2 iniettata si muoverà e verrà intrappolata. Questo, a sua volta, può supportare decisioni più affidabili ed efficienti su dove e come immagazzinare il carbonio in sicurezza sotto i nostri piedi.
Citazione: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Parole chiave: stoccaggio del carbonio, rocce porose, apprendimento automatico, flusso a scala porosa, iniezione di CO2