Clear Sky Science · es
Un conjunto de referencia para modelos sustitutos de aprendizaje automático de la interacción CO2-agua a escala de poro
Por qué almacenar carbono bajo tierra necesita mejores imágenes
Cuando hablamos de combatir el cambio climático, una idea importante es capturar dióxido de carbono (CO2) de las chimeneas industriales y almacenarlo en lo profundo del subsuelo. Pero las rocas subterráneas no son tan simples como tanques: se parecen más a esponjas intrincadas llenas de giros y recovecos diminutos donde el agua y el CO2 compiten por el espacio. Este artículo presenta una nueva “película” digital detallada de cómo el CO2 desplaza el agua a través de estos poros minúsculos, proporcionando a los investigadores el material bruto que necesitan para construir modelos informáticos más rápidos capaces de predecir si el almacenamiento subterráneo mantendrá el CO2 confinado de forma segura.
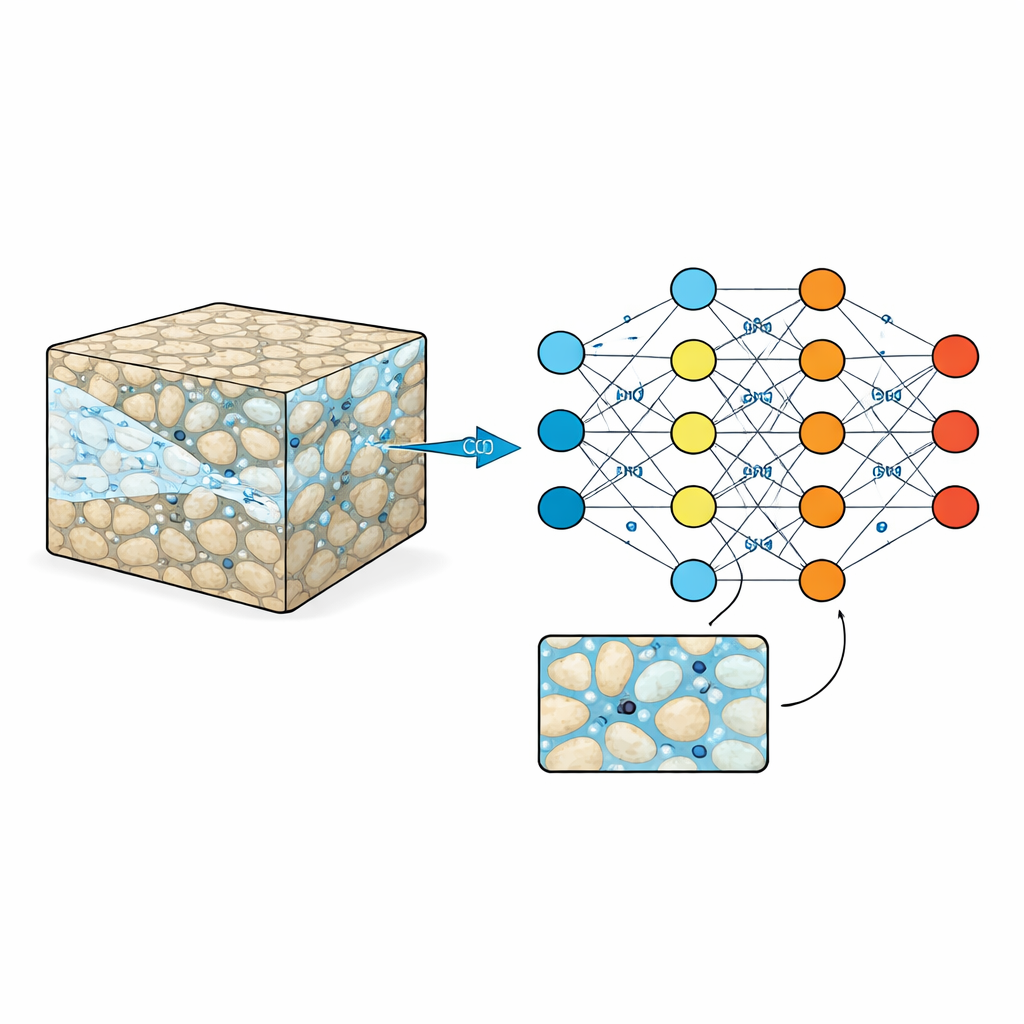
Mirando dentro de la esponja de roca
Los yacimientos subterráneos como las areniscas o las rocas volcánicas están surcados por poros microscópicos llenos de agua. Cuando se inyecta CO2, debe abrirse paso por este laberinto, a veces avanzando velozmente por canales y otras veces quedando atrapado en callejones sin salida. Estos patrones a pequeña escala controlan cuánto CO2 puede almacenarse y cuán seguro es ese almacenamiento a lo largo de décadas o siglos. Los experimentos de laboratorio tradicionales y las imágenes pueden vislumbrar lo que ocurre en unas pocas muestras pequeñas, mientras que las simulaciones computacionales de alta precisión pueden seguir cada detalle, pero a un coste elevado en tiempo y potencia de cálculo. Como resultado, los ingenieros a menudo recurren a fórmulas simplificadas que desenfocan la compleja imagen de pequeña escala, lo que puede pasar por alto comportamientos importantes.
Por qué los sustitutos inteligentes necesitan datos de entrenamiento ricos
Los modelos de aprendizaje automático prometen un atajo: una vez entrenados, pueden predecir cómo se moverá el CO2 por la roca mucho más rápido que las simulaciones físicas completas. Pero, como cualquier alumno, estos modelos solo son tan buenos como los ejemplos que ven. Muchos conjuntos de datos existentes son demasiado pequeños, cubren patrones de roca sencillos o solo registran el resultado final de una inyección, no cómo se desarrolla el proceso en el tiempo. Eso dificulta que los algoritmos aprendan las formas cambiantes de las plumas de CO2, la acumulación de presión o cómo cambios sutiles en la estructura de la roca afectan el flujo. Sin material de entrenamiento más rico, los sustitutos inteligentes corren el riesgo de hacer predicciones seguras pero poco fiables cuando se enfrentan a formaciones rocosas nuevas y más complejas.
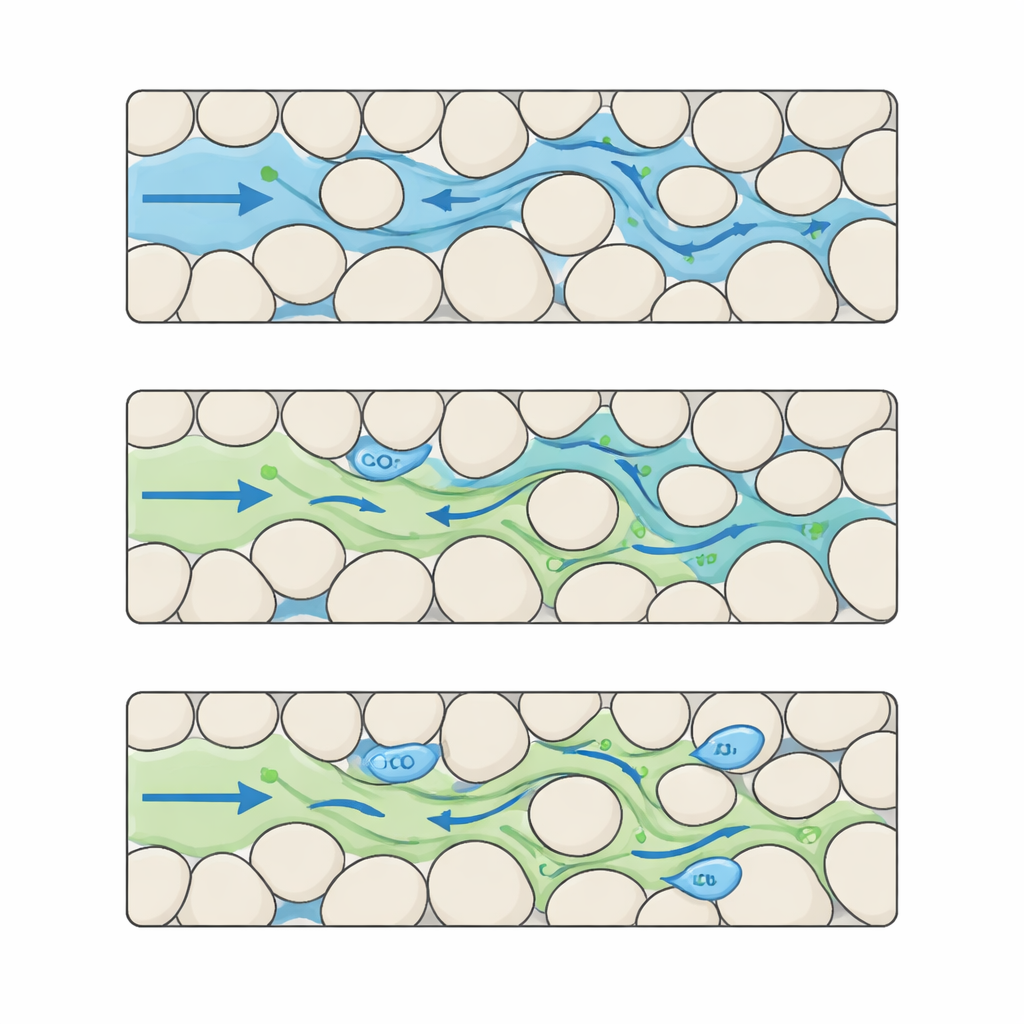
Construyendo una película detallada de CO2 y agua en poros complejos
Los autores abordan esta laguna reuniendo un conjunto de referencia que captura la interacción CO2–agua con un nivel de detalle muy fino. Empiezan creando muchas “rocas” sintéticas como mapas basados en píxeles donde los granos sólidos y los poros abiertos se disponen en distintos patrones. Al variar cuidadosamente el tamaño y la separación de los granos, generan cinco niveles distintos de complejidad estructural, desde bien ordenados hasta altamente irregulares. Para cada una de estas rocas digitales ejecutan simulaciones avanzadas en las que el CO2 entra por un lado y desplaza el agua a través del espacio poroso. Cada simulación produce 100 instantáneas espaciadas uniformemente en el tiempo, registradas en una rejilla de 512 × 512 píxeles con resolución micrométrica, siguiendo dónde se sitúan el CO2 y el agua, cómo cambia la presión y cómo varían las velocidades del fluido a lo largo del laberinto.
Qué contiene el conjunto de datos y cómo puede usarse
La colección resultante incluye 624 estructuras de poros únicas, cada una acompañada de una serie temporal completa del comportamiento de los fluidos. Para cada muestra, el conjunto de datos proporciona imágenes del esqueleto rocoso, la fracción de cada píxel ocupada por agua, así como campos de presión y de flujo en direcciones horizontal y vertical. Tablas adicionales listan propiedades globales como porosidad (cuánto espacio vacío tiene la roca) y permeabilidad (qué facilidad tienen los fluidos para moverse), junto con medidas que los ingenieros usan para describir la resistencia al flujo. Todo se almacena en formatos de archivo científicos estándar, lo que facilita a los investigadores integrarlo en sus propios códigos. Esta estructura permite entrenar modelos de aprendizaje automático no solo para adivinar resultados finales, sino también para avanzar en el tiempo, prediciendo cómo evoluciona una pluma de CO2 de un instante al siguiente.
Comprobar si la variedad mejora el aprendizaje
Para mostrar por qué importa esta diversidad, los autores entrenan tres versiones de una red neuronal popular basada en imágenes con distintos subconjuntos del conjunto de datos. Una versión ve los cinco niveles de complejidad de roca, otra solo cuatro y una tercera ve un único nivel más simple. Cuando se pide a estos modelos que predigan los patrones de CO2 en las rocas más complejas, la entrenada con la mayor variedad obtiene, de media, los mejores resultados, reproduciendo las formas de las plumas simuladas con mayor fidelidad a lo largo de muchos pasos temporales. Los modelos expuestos a ejemplos de entrenamiento más limitados cometen errores mayores, especialmente a medida que las predicciones se proyectan más hacia el futuro. Al mismo tiempo, los autores encuentran que más variedad no garantiza mejora en cada caso individual, lo que sugiere que existe un equilibrio entre la riqueza y la sobrecomplicación en el diseño de datos de entrenamiento.
Qué significa esto para el futuro del almacenamiento de carbono
En términos sencillos, este trabajo ofrece un “campo de práctica” de alta calidad para algoritmos que algún día ayudarán a diseñar y supervisar proyectos de almacenamiento subterráneo de CO2. Al ofrecer muchos ejemplos detallados de cómo el CO2 y el agua se entrelazan en redes de poros realistas, el conjunto de datos ayuda a las herramientas de aprendizaje automático a aprender las reglas del juego en lugar de memorizar unas pocas jugadas. La conclusión principal es que abrazar la variabilidad desordenada de las rocas reales en los datos de entrenamiento conduce a mejores predicciones medias sobre cómo el CO2 inyectado se moverá y quedará atrapado. Eso, a su vez, puede respaldar decisiones más fiables y eficientes sobre dónde y cómo almacenar carbono de forma segura bajo nuestros pies.
Cita: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Palabras clave: almacenamiento de carbono, rocas porosas, aprendizaje automático, flujo a escala de poro, inyección de CO2