Clear Sky Science · en
A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction
Why storing carbon underground needs better pictures
When we talk about fighting climate change, one big idea is to capture carbon dioxide (CO2) from smokestacks and store it deep underground. But underground rocks are not smooth tanks—they are more like intricate sponges full of tiny twists and turns where water and CO2 jostle for space. This paper presents a new, detailed digital "movie" of how CO2 pushes water through these tiny pores, giving researchers the raw material they need to build faster computer models that can predict whether underground storage will actually keep CO2 safely locked away.
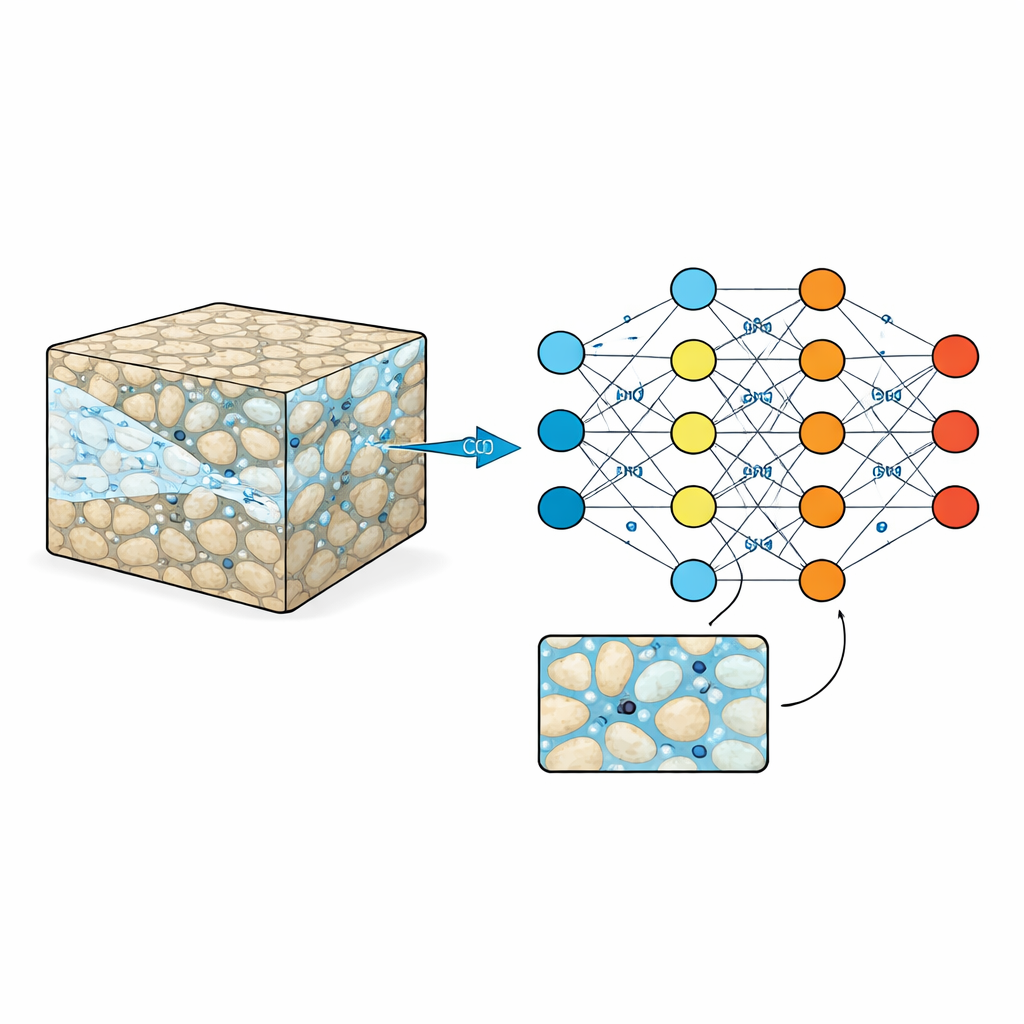
Looking inside the rock sponge
Underground reservoirs such as sandstone or volcanic rocks are criss-crossed by microscopic pores filled with water. When CO2 is pumped in, it has to wind its way through this maze, sometimes racing ahead in channels and sometimes getting stuck in dead-ends. These fine-scale patterns control how much CO2 can be stored and how secure that storage is over decades to centuries. Traditional laboratory experiments and imaging can glimpse what happens in a few small samples, while high-precision computer simulations can follow every detail—but at a high cost in time and computing power. As a result, engineers often rely on simplified formulas that blur out the messy small-scale picture, which can miss important behavior.
Why smart surrogates need rich training data
Machine learning models promise a shortcut: once trained, they can predict how CO2 will move through rock much faster than full physics-based simulations. But like any student, these models are only as good as the examples they see. Many existing datasets are too small, cover only simple rock patterns, or only record the final result of an injection, not how the process unfolds over time. That makes it hard for algorithms to learn the changing shapes of CO2 plumes, pressure build-up, or how subtle changes in the rock’s structure affect flow. Without richer training material, smart surrogates risk making confident but unreliable predictions when exposed to new, more complicated rock formations.
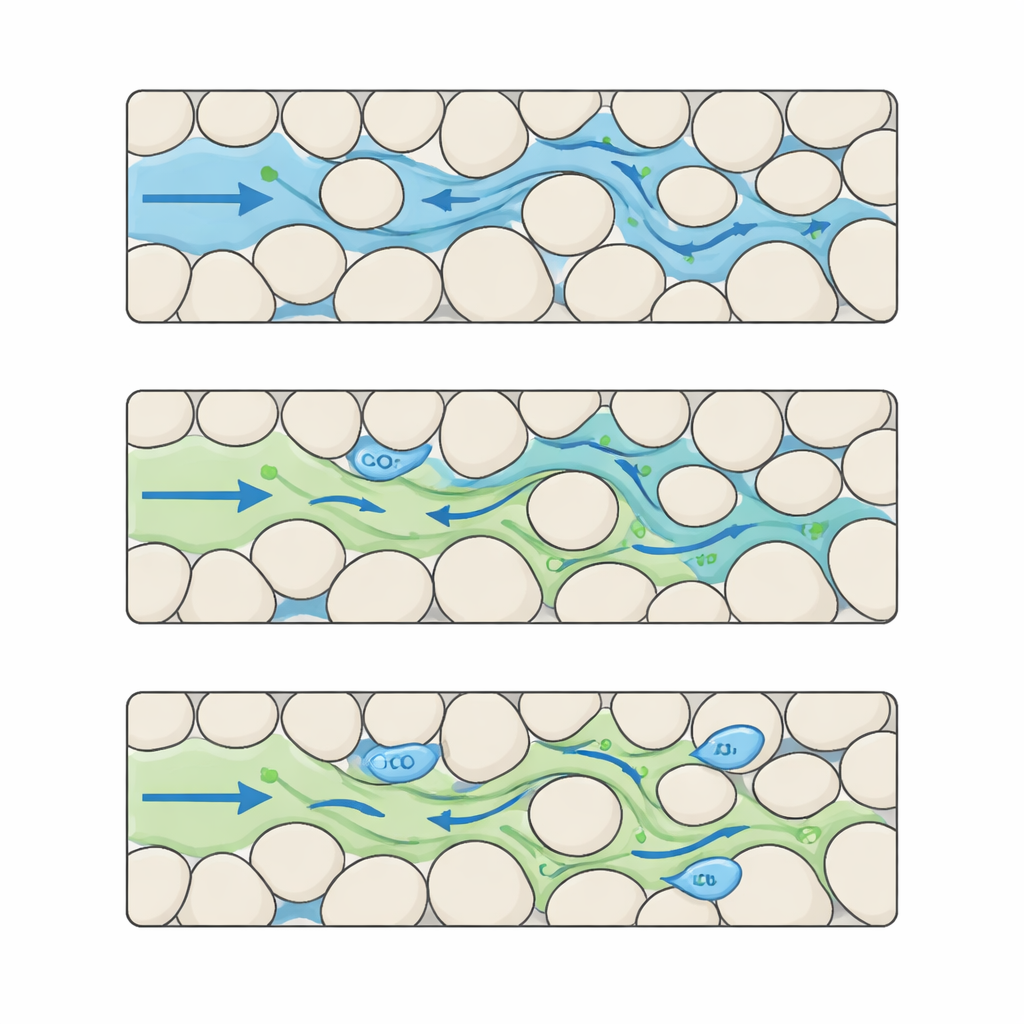
Building a detailed movie of CO2 and water in complex pores
The authors tackle this gap by assembling a benchmark dataset that captures CO2–water interaction at a very fine level of detail. They start by creating many synthetic "rocks" as pixel-based maps where solid grains and open pores are laid out in different patterns. By carefully changing grain size and spacing, they generate five distinct levels of structural complexity, from well-ordered to highly irregular. For each of these digital rocks, they run advanced simulations in which CO2 enters from one side and displaces water through the pore space. Each run produces 100 evenly spaced snapshots in time, recorded on a 512 × 512 pixel grid with micrometer-scale resolution, tracking where CO2 and water sit, how pressure changes, and how fluid speeds vary throughout the maze.
What the dataset contains and how it can be used
The resulting collection includes 624 unique pore structures, each paired with a full time series of fluid behavior. For every sample, the dataset provides images of the rock skeleton, the fraction of each pixel filled with water, as well as pressure and flow fields in both horizontal and vertical directions. Additional tables list bulk properties such as porosity (how much empty space the rock has) and permeability (how easily fluids can move), along with measures that engineers use to describe flow resistance. Everything is stored in standard scientific file formats, making it easy for researchers to plug into their own codes. This structure allows machine learning models to be trained not only to guess final outcomes, but also to step forward in time—predicting how a CO2 plume evolves from one instant to the next.
Testing whether variety improves learning
To show why this diversity matters, the authors train three versions of a popular image-based neural network on different slices of the dataset. One version sees all five levels of rock complexity, another sees only four, and a third sees a single, simplest level. When these models are asked to predict CO2 patterns in the most complex rocks, the one trained on the richest variety does best on average, reproducing the simulated plume shapes more faithfully over many time steps. The models exposed to narrower training examples make larger mistakes, especially as predictions are pushed further into the future. At the same time, the authors find that more variety does not guarantee improvement for every single case, hinting that there is a balance between richness and over-complication in training data design.
What this means for future carbon storage
In plain terms, this work provides a high-quality "practice field" for algorithms that will one day help design and monitor underground CO2 storage projects. By offering many detailed examples of how CO2 and water weave through realistic pore networks, the dataset helps machine learning tools learn the rules of the game rather than memorizing a few plays. The main takeaway is that embracing the messy variability of real rocks in training data leads to better average predictions of how injected CO2 will move and be trapped. That, in turn, can support more reliable and efficient decisions about where and how to store carbon safely beneath our feet.
Citation: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Keywords: carbon storage, porous rocks, machine learning, pore-scale flow, CO2 injection