Clear Sky Science · nl
Een benchmarkdataset voor machine-learning-surrogates van CO2-waterinteractie op poriënschaal
Waarom koolstofopslag ondergronds betere beelden nodig heeft
Als we het hebben over de strijd tegen klimaatverandering, is een belangrijk idee om koolstofdioxide (CO2) af te vangen bij schoorstenen en diep onder de grond op te slaan. Ondergrondse gesteenten zijn echter geen gladde tanks — ze lijken meer op ingewikkelde sponzen vol kleine kronkels waar water en CO2 om ruimte wedijveren. Dit artikel presenteert een nieuwe, gedetailleerde digitale "film" van hoe CO2 water door deze kleine poriën verdringt, en biedt onderzoekers het ruwe materiaal dat nodig is om snellere computermodellen te bouwen die kunnen voorspellen of ondergrondse opslag CO2 daadwerkelijk veilig kan vasthouden.
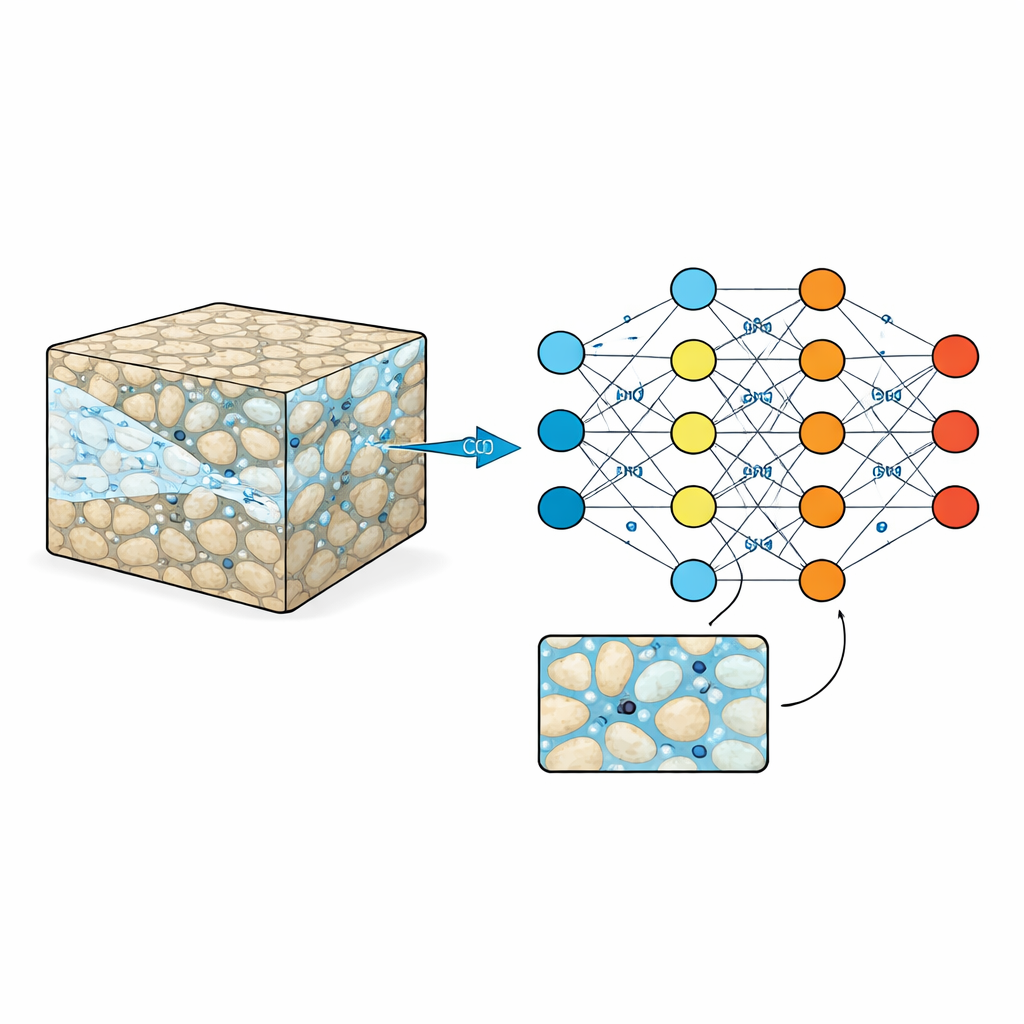
In de spons van het gesteente kijken
Ondergrondse reservoirgesteenten zoals zandsteen of vulkanisch gesteente zijn doorkruist door microscopische poriën gevuld met water. Wanneer CO2 wordt geïnjecteerd, moet het zich een weg banen door dit doolhof, soms snelt het vooruit in kanalen en soms blijft het vastzitten in doodlopende eindjes. Deze fijnmazige patronen bepalen hoeveel CO2 kan worden opgeslagen en hoe veilig die opslag is over decennia tot eeuwen. Traditionele laboratoriumexperimenten en beeldvorming geven een glimp van wat er in een paar kleine monsters gebeurt, terwijl hoogprecisie computermodellen elk detail kunnen volgen — maar tegen hoge kosten in tijd en rekenkracht. Daardoor vertrouwen ingenieurs vaak op vereenvoudigde formules die het rommelige kleinschalige beeld vervagen, en die belangrijke gedragingen kunnen missen.
Waarom slimme surrogates rijke trainingsdata nodig hebben
Machine-learningmodellen beloven een kortere weg: eenmaal getraind kunnen ze voorspellen hoe CO2 zich door gesteente beweegt veel sneller dan volledige fysicagebaseerde simulaties. Maar zoals elke leerling zijn deze modellen slechts zo goed als de voorbeelden die ze zien. Veel bestaande datasets zijn te klein, beslaan alleen eenvoudige gesteentepatronen of registreren slechts het eindresultaat van een injectie, niet hoe het proces in de tijd verloopt. Dat bemoeilijkt het voor algoritmen om de veranderende vormen van CO2-pluimen, drukopbouw of hoe subtiele veranderingen in de structuur van het gesteente de stroming beïnvloeden, te leren. Zonder rijkere trainingsmaterialen lopen slimme surrogates het risico overtuigende maar onbetrouwbare voorspellingen te doen wanneer ze worden geconfronteerd met nieuwe, complexere gesteentevormen.
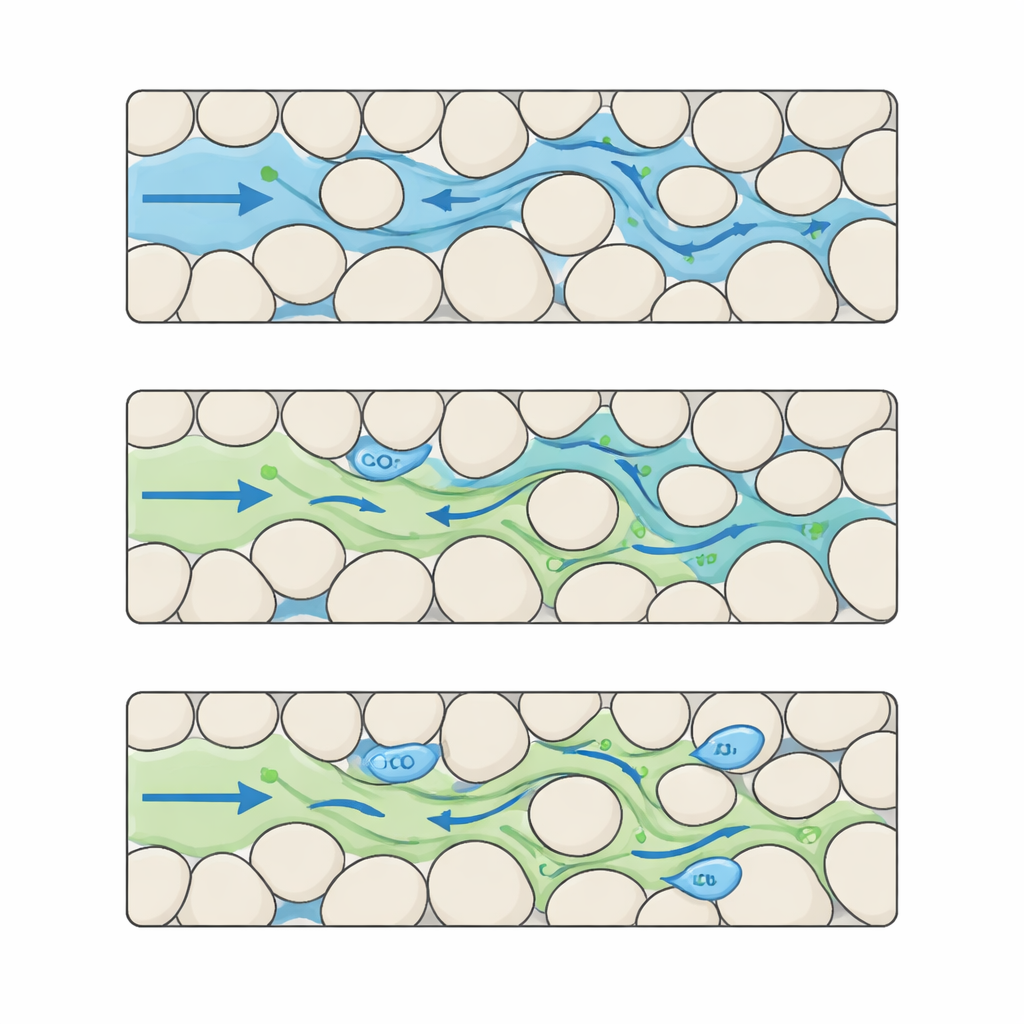
Een gedetailleerde film van CO2 en water in complexe poriën opbouwen
De auteurs vullen deze leemte door een benchmarkdataset samen te stellen die de interactie tussen CO2 en water op een zeer fijn detailniveau vastlegt. Ze beginnen met het creëren van veel synthetische "gesteenten" als pixelgebaseerde kaarten waarop vaste korrels en open poriën in verschillende patronen zijn gelegd. Door korrelgrootte en onderlinge afstand zorgvuldig te variëren, genereren ze vijf onderscheidende niveaus van structurele complexiteit, van goed geordend tot sterk onregelmatig. Voor elk van deze digitale gesteenten voeren ze geavanceerde simulaties uit waarbij CO2 vanaf één zijde binnenkomt en water uit de porieruimte verdringt. Elke run levert 100 gelijkmatig verdeelde tijdsopnamen op een raster van 512 × 512 pixels met micrometerschaal resolutie, waarin wordt gevolgd waar CO2 en water zich bevinden, hoe de druk verandert en hoe de vloeistofsnelheden door het doolhof variëren.
Wat de dataset bevat en hoe die kan worden gebruikt
De resulterende verzameling omvat 624 unieke poriestructuren, elk gekoppeld aan een volledige tijdreeks van vloeistofgedrag. Voor elk monster levert de dataset afbeeldingen van het gesteenteskelet, de fractie van elke pixel gevuld met water, evenals druk- en snelheidsvelden in zowel horizontale als verticale richtingen. Extra tabellen vermelden bulk-eigenschappen zoals porositeit (hoeveel lege ruimte het gesteente heeft) en permeabiliteit (hoe gemakkelijk vloeistoffen kunnen bewegen), samen met grootheden die ingenieurs gebruiken om stromingsweerstand te beschrijven. Alles is opgeslagen in standaard wetenschappelijke bestandsformaten, waardoor het voor onderzoekers eenvoudig is om de data in hun eigen code te pluggen. Deze opzet stelt machine-learningmodellen in staat niet alleen eindresultaten te raden, maar ook stap voor stap in de tijd vooruit te voorspellen — hoe een CO2-pluim zich van het ene moment naar het volgende ontwikkelt.
Testen of variëteit het leren verbetert
Om te laten zien waarom deze diversiteit ertoe doet, trainen de auteurs drie versies van een populair beeldgebaseerd neuraal netwerk op verschillende delen van de dataset. Één versie ziet alle vijf niveaus van gesteentecomplexiteit, een andere ziet er slechts vier en een derde ziet slechts het enkelste, meest eenvoudige niveau. Wanneer van deze modellen wordt gevraagd CO2-patronen in de meest complexe gesteenten te voorspellen, presteert degene die op de rijkste variëteit is getraind gemiddeld het beste en reproduceert de gesimuleerde pluimvormen trouw over veel tijdstappen. De modellen die aan beperktere trainingsvoorbeelden werden blootgesteld, maken grotere fouten, vooral naarmate voorspellingen verder de toekomst in worden geduwd. Tegelijkertijd vinden de auteurs dat meer variëteit niet voor elk afzonderlijk geval verbetering garandeert, wat suggereert dat er een balans is tussen rijkdom en overcomplicatie bij het ontwerpen van trainingsdata.
Wat dit betekent voor toekomstige koolstofopslag
In eenvoudige bewoordingen biedt dit werk een hoogwaardige "oefenruimte" voor algoritmen die op een dag zullen helpen bij het ontwerpen en monitoren van ondergrondse CO2-opslagprojecten. Door veel gedetailleerde voorbeelden te bieden van hoe CO2 en water zich door realistische porienetwerken bewegen, helpt de dataset machine-learningtools de spelregels te leren in plaats van een paar plays uit het hoofd te leren. De belangrijkste conclusie is dat het omarmen van de rommelige variabiliteit van echte gesteenten in trainingsdata leidt tot betere gemiddelde voorspellingen van hoe geïnjecteerde CO2 zich zal verplaatsen en worden gevangen. Dat kan op zijn beurt betrouwbaardere en efficiëntere beslissingen ondersteunen over waar en hoe koolstof veilig onder onze voeten kan worden opgeslagen.
Bronvermelding: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Trefwoorden: koolstofopslag, porieuze gesteenten, machine learning, stroming op poriënschaal, CO2-injectie