Clear Sky Science · pt
Um Conjunto de Dados de Referência para Precursores de Aprendizado de Máquina da Interação CO2-Água em Escala de Poros
Por que armazenar carbono no subsolo precisa de imagens melhores
Quando falamos em combater as mudanças climáticas, uma ideia importante é capturar dióxido de carbono (CO2) de chaminés industriais e armazená-lo em profundidade no subsolo. Mas as rochas subterrâneas não são tanques lisos — elas se parecem mais com esponjas intrincadas cheias de curvas minúsculas onde água e CO2 disputam espaço. Este artigo apresenta um novo “filme” digital detalhado de como o CO2 desloca a água através desses poros minúsculos, oferecendo aos pesquisadores o material bruto necessário para construir modelos computacionais mais rápidos que possam prever se o armazenamento subterrâneo realmente manterá o CO2 confinado com segurança.
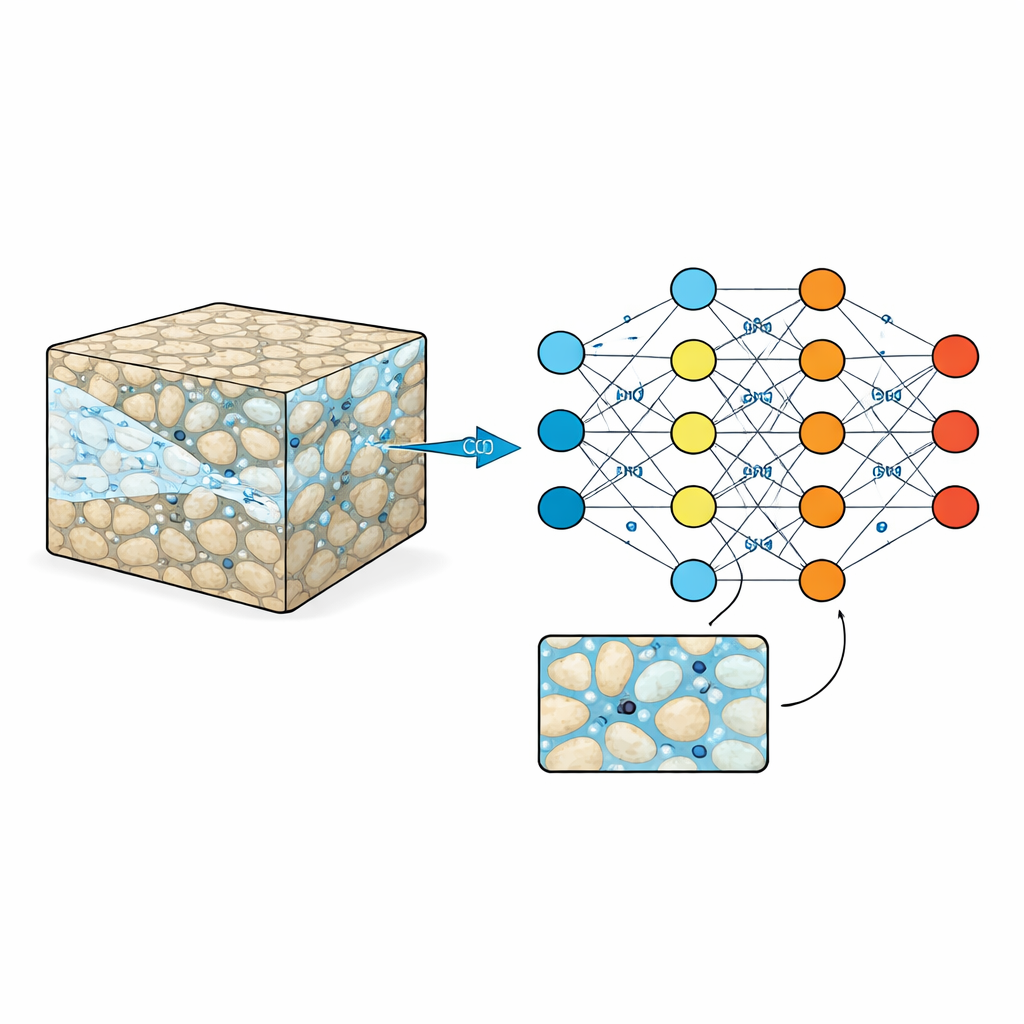
Olhando dentro da esponja de rocha
Reservatórios subterrâneos, como arenito ou rochas vulcânicas, são cruzados por poros microscópicos preenchidos com água. Quando o CO2 é injetado, ele precisa se enredar por esse labirinto, às vezes correndo à frente em canais e outras vezes ficando preso em becos sem saída. Esses padrões em escala fina controlam quanto CO2 pode ser armazenado e quão seguro esse armazenamento será ao longo de décadas a séculos. Experimentos laboratoriais tradicionais e imagens conseguem vislumbrar o que acontece em algumas amostras pequenas, enquanto simulações computacionais de alta precisão acompanham cada detalhe — mas a um alto custo em tempo e poder computacional. Como resultado, engenheiros frequentemente dependem de fórmulas simplificadas que suavizam a imagem complexa em pequena escala, o que pode perder comportamentos importantes.
Por que precursores inteligentes precisam de dados de treinamento ricos
Modelos de aprendizado de máquina prometem um atalho: uma vez treinados, eles podem prever como o CO2 se moverá pela rocha muito mais rápido do que simulações físicas completas. Mas, como qualquer estudante, esses modelos são tão bons quanto os exemplos que recebem. Muitos conjuntos de dados existentes são muito pequenos, cobrem apenas padrões rochosos simples ou registram apenas o resultado final de uma injeção, não como o processo se desenrola ao longo do tempo. Isso dificulta que os algoritmos aprendam as formas mutáveis das plumas de CO2, o acúmulo de pressão ou como mudanças sutis na estrutura da rocha afetam o fluxo. Sem material de treinamento mais rico, precursores inteligentes correm o risco de fazer previsões confiante mas pouco confiáveis quando expostos a formações rochosas novas e mais complexas.
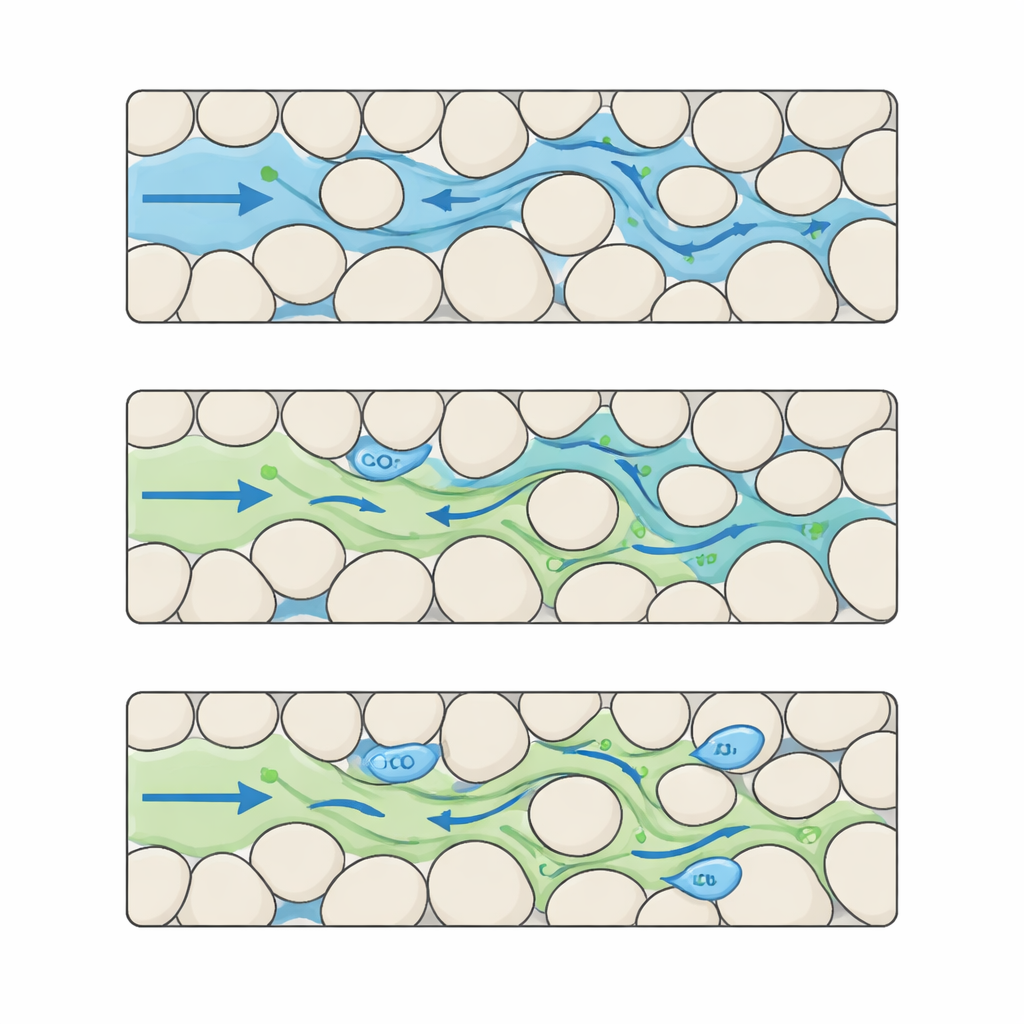
Construindo um filme detalhado de CO2 e água em poros complexos
Os autores enfrentam essa lacuna montando um conjunto de dados de referência que captura a interação CO2–água em nível de detalhe muito fino. Eles começam criando muitas “rochas” sintéticas como mapas baseados em pixels onde grãos sólidos e poros abertos são dispostos em diferentes padrões. Ao mudar cuidadosamente o tamanho e o espaçamento dos grãos, geram cinco níveis distintos de complexidade estrutural, do bem ordenado ao altamente irregular. Para cada uma dessas rochas digitais, executam simulações avançadas nas quais o CO2 entra por um lado e desloca a água através do espaço poroso. Cada execução produz 100 instantâneos temporalmente espaçados de forma uniforme, registrados em uma grade de 512 × 512 pixels com resolução na escala de micrômetros, acompanhando onde estão o CO2 e a água, como a pressão muda e como as velocidades dos fluidos variam por todo o labirinto.
O que o conjunto de dados contém e como pode ser usado
A coleção resultante inclui 624 estruturas de poros únicas, cada uma pareada com uma série temporal completa do comportamento dos fluidos. Para cada amostra, o conjunto de dados fornece imagens do esqueleto rochoso, a fração de cada pixel preenchida com água, bem como campos de pressão e de fluxo nas direções horizontal e vertical. Tabelas adicionais listam propriedades de bloco, como porosidade (quanto espaço vazio a rocha tem) e permeabilidade (com que facilidade os fluidos se movem), junto com medidas que engenheiros usam para descrever a resistência ao fluxo. Tudo é armazenado em formatos de arquivo científicos padrão, facilitando a integração pelos pesquisadores em seus próprios códigos. Essa estrutura permite que modelos de aprendizado de máquina sejam treinados não apenas para prever resultados finais, mas também para avançar no tempo — prevendo como uma pluma de CO2 evolui de um instante para o próximo.
Testando se a variedade melhora o aprendizado
Para mostrar por que essa diversidade importa, os autores treinam três versões de uma rede neural popular baseada em imagens em diferentes fatias do conjunto de dados. Uma versão vê os cinco níveis de complexidade da rocha, outra vê apenas quatro e uma terceira vê um único nível, o mais simples. Quando esses modelos são solicitados a prever padrões de CO2 nas rochas mais complexas, a treinada com a variedade mais rica tem o melhor desempenho em média, reproduzindo as formas das plumas simuladas com mais fidelidade ao longo de muitos passos temporais. Os modelos expostos a exemplos de treinamento mais estreitos cometem erros maiores, especialmente conforme as previsões são projetadas mais para o futuro. Ao mesmo tempo, os autores constatam que mais variedade não garante melhoria em cada caso individual, sugerindo que existe um equilíbrio entre riqueza e excesso de complexidade no desenho de dados de treinamento.
O que isso significa para o futuro do armazenamento de carbono
Em termos simples, este trabalho fornece um “campo de prática” de alta qualidade para algoritmos que um dia ajudarão a projetar e monitorar projetos de armazenamento de CO2 no subsolo. Ao oferecer muitos exemplos detalhados de como CO2 e água se entrelaçam por redes de poros realistas, o conjunto de dados ajuda ferramentas de aprendizado de máquina a aprender as regras do jogo em vez de memorizar poucas jogadas. A principal conclusão é que abraçar a variabilidade desordenada das rochas reais nos dados de treinamento leva a previsões médias melhores de como o CO2 injetado se moverá e será aprisionado. Isso, por sua vez, pode apoiar decisões mais confiáveis e eficientes sobre onde e como armazenar carbono com segurança sob nossos pés.
Citação: Abdellatif, A., Menke, H.P., Maes, J. et al. A Benchmark Dataset for Machine Learning Surrogates of Pore-Scale CO2-Water Interaction. Sci Data 13, 621 (2026). https://doi.org/10.1038/s41597-025-05794-z
Palavras-chave: armazenamento de carbono, rochas porosas, aprendizado de máquina, fluxo em escala de poros, injeção de CO2