Clear Sky Science · sv
Termodynamiskt konsekvent maskininlärningsmodell för överskjutande Gibbs-energi
Varför detta är viktigt för vardagskemin
Det moderna livet bygger på blandningar av vätskor, från bränslen och köldmedier till läkemedel och gröna lösningsmedel. Att utforma dessa blandningar säkert och effektivt kräver kunskap om hur deras molekyler interagerar. Att mäta dessa interaktioner för varje möjlig kombination är dock omöjligt. Denna artikel presenterar ett nytt maskininlärningsverktyg, kallat HANNA, som lär sig beteendet hos flytande blandningar direkt från data samtidigt som det respekterar grundläggande termodynamiska lagar. Det lovar snabbare, bredare och mer tillförlitliga förutsägelser för att vägleda processdesign och materialupptäckt.
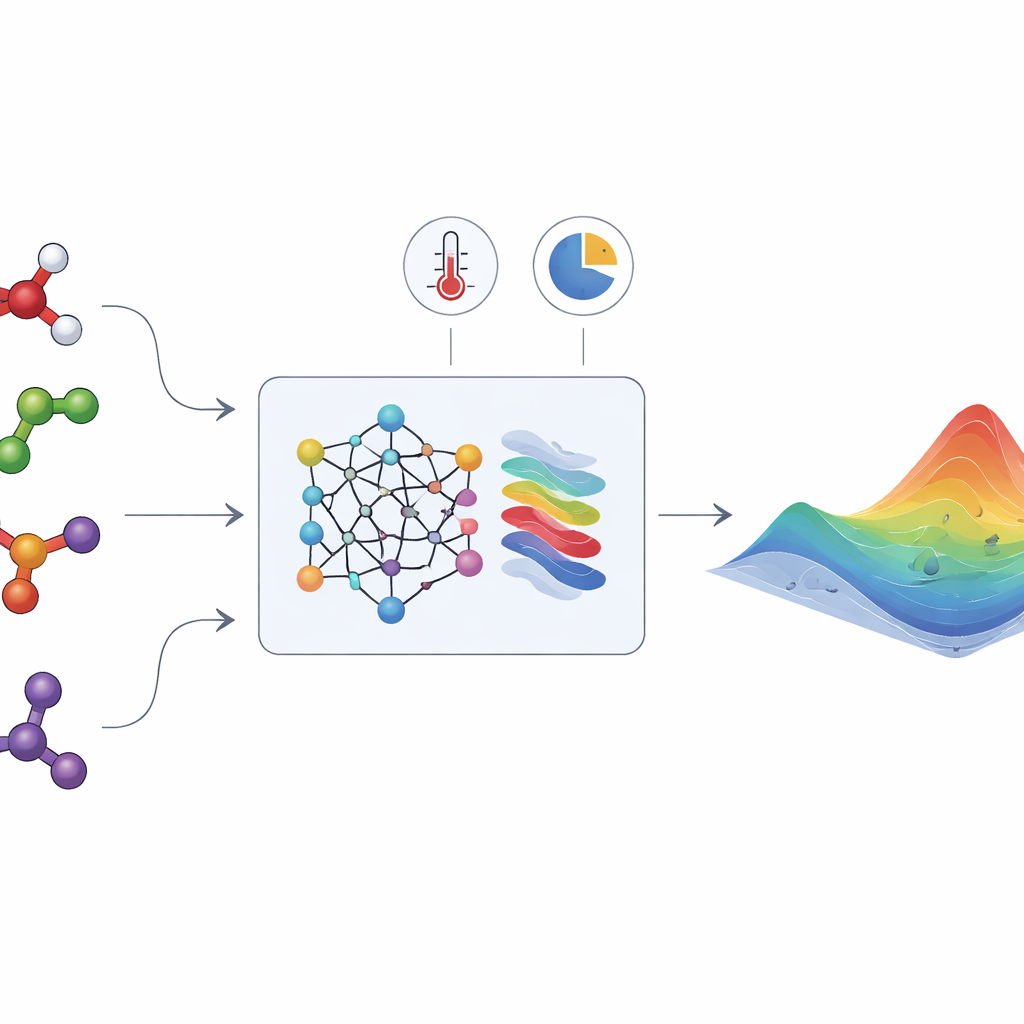
Den dolda energin som formar flytande blandningar
När olika vätskor blandas attraherar eller repellerar deras molekyler varandra på sätt som kan vara ganska subtila. Dessa effekter fångas i en storhet som kallas ”överskjutande Gibbs-energi”, vilken anger hur mycket blandningen avviker från idealiskt beteende. Från denna enda funktion kan ingenjörer härleda nyckelstorheter såsom aktivitetskoefficienter, vilka i sin tur avgör om en blandning bildar en homogen vätskefas eller delar upp sig i två, om ånga och vätska kan samexistera, och hur komponenter fördelar sig mellan dessa faser. Tyvärr kan överskjutande Gibbs-energi inte mätas direkt. Den måste härledas från mödosamma experiment på ång–vätske- och vätske–vätskejämvikter eller värmeeffekter, och endast en liten bråkdel av alla relevanta blandningar har någonsin studerats.
Begränsningar i traditionella förutsägningsverktyg
I årtionden har ingenjörer förlitat sig på modeller som NRTL, UNIQUAC och UNIFAC-familjen för att uppskatta blandningsbeteende. Dessa metoder approximerar interaktioner genom parametrar som anpassas till experimentdata, ofta på parvis (binär) basis. Trots att de är kraftfulla har de viktiga begränsningar: för att förutsäga en ny blandning behövs vanligtvis parametrar för varje binärt delsystem som ingår, och sådana parametervärden kanske saknas för nya föreningar. Även gruppbaserade angreppssätt som UNIFAC, som dekomponerar molekyler i byggstenar, är bundna till en fast katalog av grupper och kan få svårigheter med komplexa ämnen som joniska vätskor. Dessutom har många klassiska modeller svårt att samtidigt beskriva ång–vätske- och vätske–vätskejämvikter korrekt med en enda parametersättning.
Ett neuralt nätverk som följer fysikens lagar
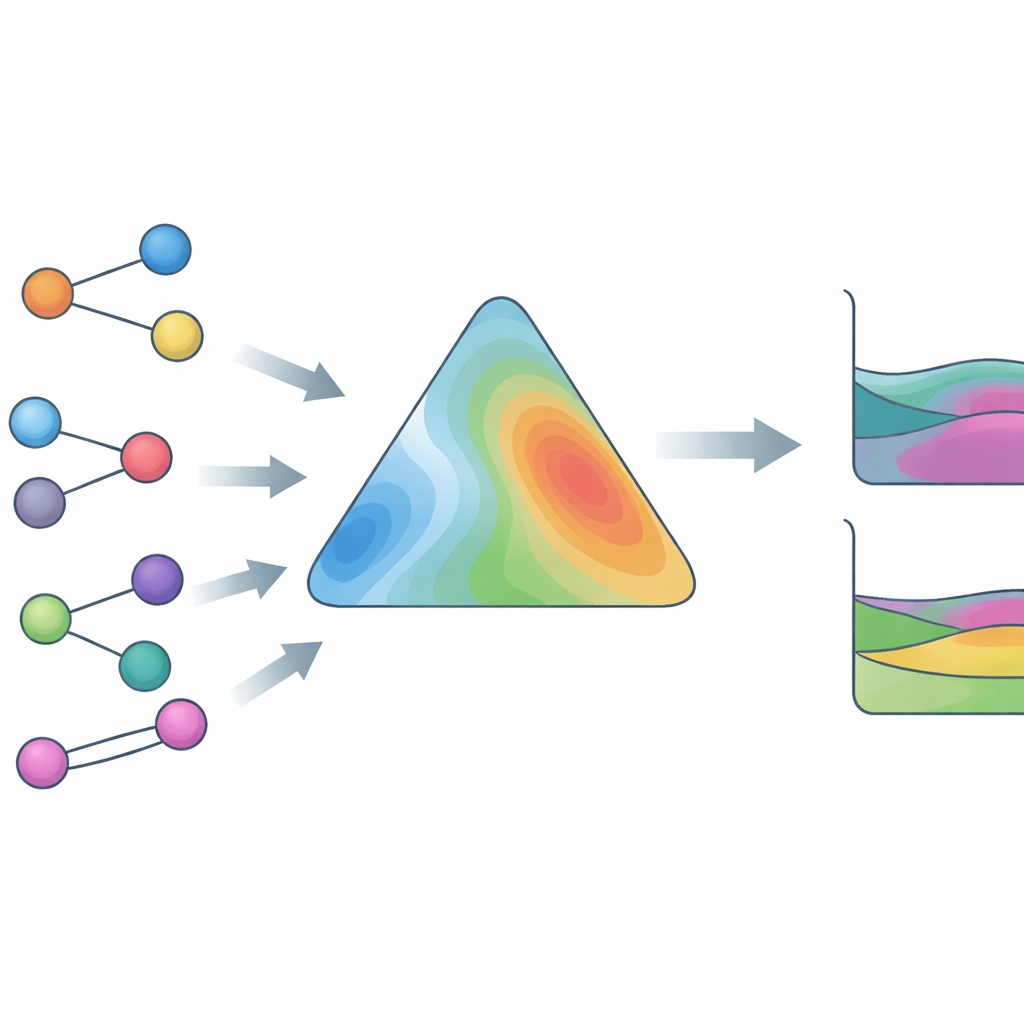
HANNA tar sig an dessa utmaningar genom att kombinera moderna neurala nätverk med hårdkodade termodynamiska regler. Som indata krävs endast komponenternas molekylstrukturer (kodade som SMILES-strängar), temperaturen och blandningssammansättningen. En kemisk språkmodell (ChemBERTa-2) omvandlar först varje molekyl till ett numeriskt fingeravtryck. Dessa fingeravtryck matas in i en specialiserad nätverksarkitektur som är byggd för att uppfylla centrala konsistenskrav: den respekterar Gibbs–Duhem-relationen, beter sig korrekt när en komponent blir ren eller oändligt utspädd, och ger samma svar oavsett i vilken ordning komponenterna listas. Utifrån dessa begränsningar predicerar HANNA den överskjutande Gibbs-energin för varje binärt par i en blandning och använder sedan ett geometriskt projektionstänk för att utvidga dessa prediktioner till flerkomponentsblandningar, utan att införa ytterligare anpassningsparametrar.
Träning på verkliga data, inte bara ekvationer
För att göra HANNA allmänt användbar tränade författarna modellen på en exceptionellt stor och mångsidig experimentell databas. Denna innehåller ång–vätskedata med full fasammansättning, ång–vätskedata med enbart totaltryck, vätske–vätske fasuppdelningar, aktivitetskoefficienter vid oändlig utspädning och överskjutande entalpier, omfattande mer än 800 000 datapunkter och över 4 000 distinkta föreningar, inklusive joniska vätskor och andra utmanande arter. En nyckelinnovation är en surrogatlösare som efterliknar en robust termodynamisk algoritm för att upptäcka och lokalisera vätske–vätskeuppdelningar. Denna surrogat är differentiell, vilket gör att HANNA kan tränas ”end-to-end” mot uppmätta fassammansättningar utan att använda långsamma iterativa beräkningar inne i inlärningsslingan. Ytterligare förlusttermer uppmuntrar HANNA att känna igen den krökning som är förknippad med fasseparation och att producera släta prediktioner som beter sig förnuftigt även utanför träningsintervallet.
Hur den nya modellen står sig
När den var tränad testades HANNA endast på system som hållits tillbaka under träningen, och dess prestanda jämfördes med ledande klassiska och maskininlärningsbaserade modeller. För binära blandningar predicerade den konsekvent aktivitetskoefficienter, fassammansättningar och överskjutande entalpier mer exakt än den allmänt använda modifierade UNIFAC (Dortmund)-metoden, samtidigt som den identifierade vätske–vätske immiscibilitetsgap mer tillförlitligt. För ternära och till och med kvartära blandningar, som den aldrig sett under träning, förblev HANNA konkurrenskraftig eller överlägsen, trots att den enbart förlitade sig på binärdata plus den geometriska projektionen. Den överträffade också flera nyare grafbaserade neurala nätverk som antingen saknade strikt termodynamisk konsekvens eller var begränsade till speciella förhållanden såsom rumstemperatur eller oändlig utspädning.
Vad detta betyder för vetenskap och industri
För en icke-specialist är huvudbudskapet att HANNA fungerar som en starkt informerad, fysiskt grundad ”spåman” för flytande blandningar. Givet endast kemiska formler kan den förutsäga om två eller flera vätskor kommer att blanda sig, dela upp sig i lager eller uppvisa komplex fasbeteende, och den gör det över ett brett temperaturintervall. Avgörande är att den gör detta samtidigt som den hedrar underliggande termodynamiska regler, vilket minskar risken för orealistiska resultat som kan plåga okonstlade maskininlärningsmodeller. Eftersom hela modellen och koden släpps öppet och är åtkomliga via ett webbgränssnitt kan ingenjörer börja använda HANNA direkt i processimulering och lösningsmedelscreening. Även om författarna noterar kvarstående begränsningar — såsom outprövad prestanda långt utanför träningsintervall och för starka elektrolyter — markerar arbetet ett stort steg mot datadriven, termodynamiskt konsekvent utformning av kemiska processer.
Citering: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Nyckelord: flytande blandningar, termodynamik, maskininlärning, överskjutande Gibbs-energi, fasjämvikt