Clear Sky Science · it
Modello di machine learning termodinamicamente consistente per l’energia libera di Gibbs in eccesso
Perché questo è importante per la chimica di tutti i giorni
La vita moderna si basa su miscele liquide, dai carburanti e refrigeranti ai farmaci e solventi ecocompatibili. Progettare queste miscele in modo sicuro ed efficiente richiede di conoscere come le loro molecole interagiscono. Tuttavia misurare tali interazioni per ogni possibile combinazione è impossibile. Questo articolo presenta un nuovo strumento di apprendimento automatico, chiamato HANNA, che apprende il comportamento delle miscele liquide direttamente dai dati rispettando al contempo le leggi fondamentali della termodinamica. Promette previsioni più rapide, estese e affidabili per guidare la progettazione di processi chimici e la scoperta di materiali.
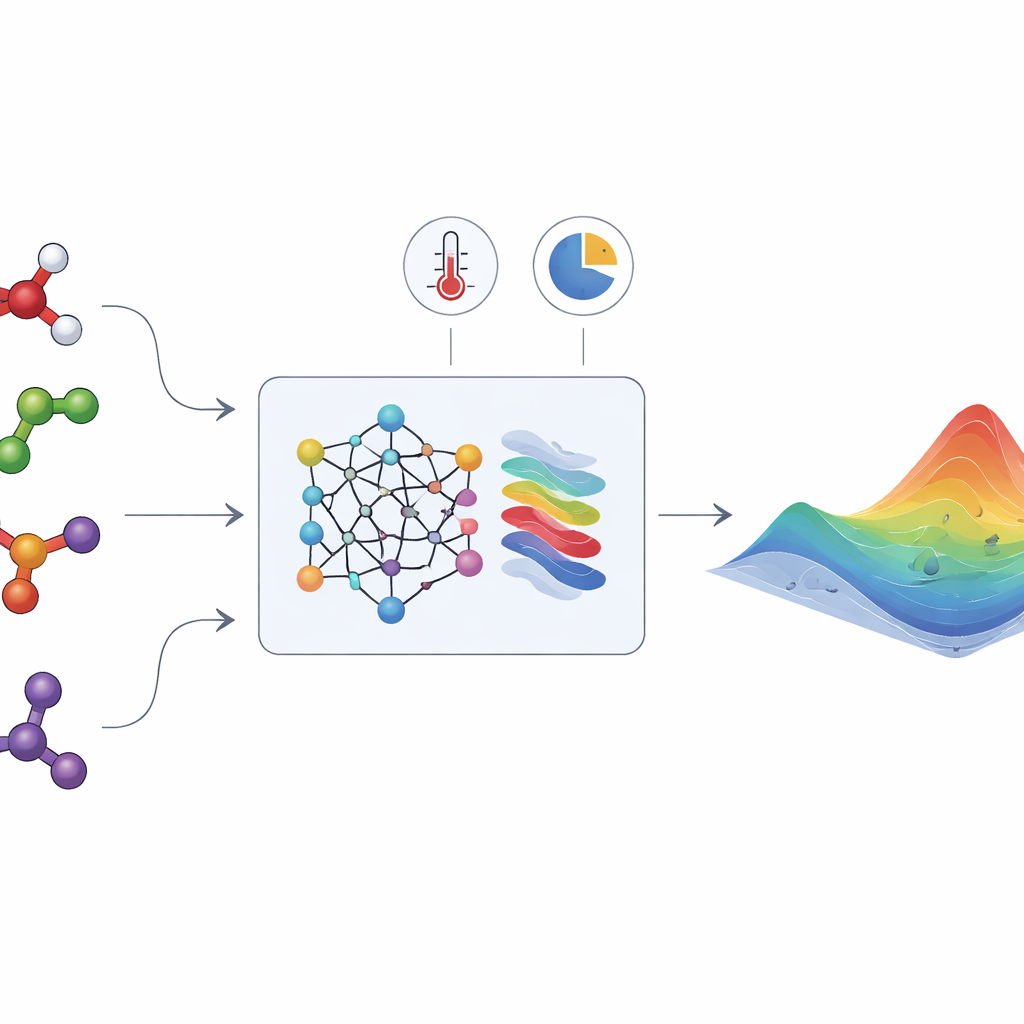
L’energia nascosta che plasma le miscele liquide
Quando vengono mescolati liquidi diversi, le loro molecole si attraggono o si respingono in modi spesso sottili. Questi effetti sono catturati da una quantità chiamata “energia libera di Gibbs in eccesso”, che indica quanto la miscela si discosta dal comportamento ideale. Da questa singola funzione gli ingegneri possono ricavare proprietà chiave come i coefficienti di attività, che a loro volta determinano se una miscela forma un’unica fase liquida o si separa in due, se vapore e liquido coesistono e come i componenti si distribuiscono tra di essi. Sfortunatamente, l’energia libera di Gibbs in eccesso non può essere misurata direttamente. Deve essere inferita da esperimenti meticolosi su equilibri vapore–liquido e liquido–liquido o da misure termiche, e solo una frazione minuscola di tutte le miscele rilevanti è mai stata studiata.
Limiti degli strumenti di previsione tradizionali
Per decenni gli ingegneri si sono affidati a modelli come NRTL, UNIQUAC e la famiglia UNIFAC per stimare il comportamento delle miscele. Questi metodi approssimano le interazioni tramite parametri adattati ai dati sperimentali, spesso su base binaria. Pur essendo potenti, presentano limiti importanti: per prevedere una nuova miscela è quasi sempre necessario disporre dei parametri per ogni sottosistema binario presente, che potrebbero non esistere per composti nuovi. Anche gli approcci basati sui gruppi come UNIFAC, che scompongono le molecole in blocchi costitutivi, sono limitati a un catalogo fisso di gruppi e possono avere difficoltà con specie complesse come gli ionic liquids. Inoltre molti modelli classici faticano a descrivere contemporaneamente con accuratezza equilibri vapore–liquido e liquido–liquido usando un unico insieme di parametri.
Una rete neurale che osserva le leggi fisiche
HANNA affronta queste sfide combinando reti neurali moderne con regole termodinamiche integrate a livello architetturale. Come input richiede soltanto le strutture molecolari dei componenti (codificate come stringhe SMILES), la temperatura e la composizione della miscela. Un modello di linguaggio chimico (ChemBERTa-2) converte prima ogni molecola in una impronta numerica. Queste impronte alimentano un’architettura di rete specializzata costruita per rispettare requisiti di coerenza fondamentali: osserva la relazione di Gibbs–Duhem, si comporta correttamente quando un componente diventa puro o infinitamente diluito e restituisce lo stesso risultato indipendentemente dall’ordine dei componenti. Da questi vincoli HANNA predice l’energia libera di Gibbs in eccesso per ogni coppia binaria nella miscela e poi usa uno schema di proiezione geometrica per estendere tali previsioni a miscele multicomponente, senza introdurre parametri di adattamento aggiuntivi.
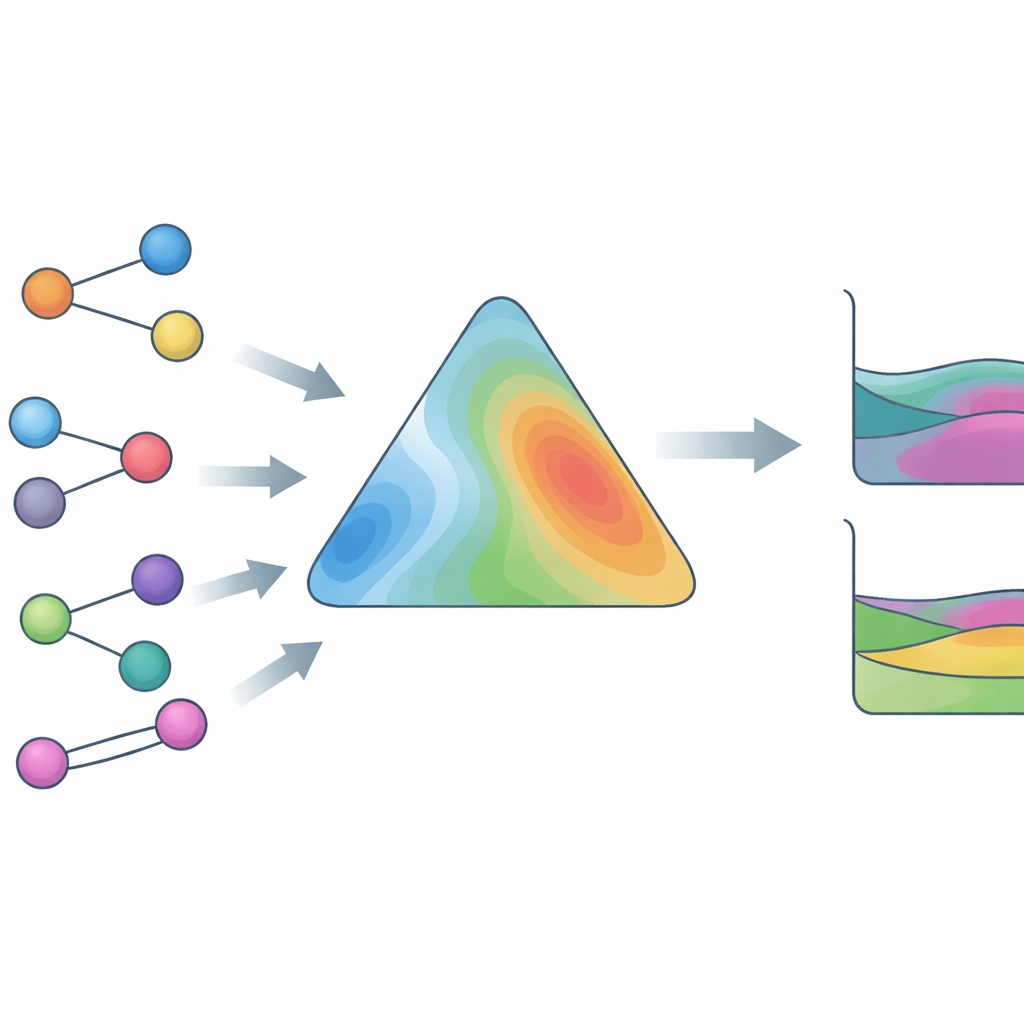
Addestrata su dati reali, non solo equazioni
Per rendere HANNA ampiamente utile, gli autori l’hanno addestrata su un database sperimentale eccezionalmente ampio e vario. Esso include dati vapore–liquido con composizioni di fase complete, dati vapore–liquido con solo pressioni totali, separazioni liquido–liquido, coefficienti di attività a diluizione infinita ed entalpie in eccesso, coprendo più di 800.000 punti dati e oltre 4.000 composti distinti, inclusi ionic liquids e altre specie difficili. Un’innovazione chiave è un risolutore surrogato che emula un algoritmo termodinamico robusto per rilevare e localizzare separazioni liquido–liquido. Questo surrogato è differenziabile, così HANNA può essere addestrata “end-to-end” contro composizioni di fase misurate senza ricorrere a calcoli iterativi lenti all’interno del ciclo di apprendimento. Termini di perdita aggiuntivi incoraggiano HANNA a riconoscere la curvatura associata alla separazione di fase e a produrre previsioni lisce che si comportano in modo sensato anche al di fuori dell’intervallo di addestramento.
Come si confronta il nuovo modello
Una volta addestrata, HANNA è stata testata solo su sistemi tenuti fuori dall’addestramento e le sue prestazioni sono state confrontate con i principali modelli classici e di machine learning. Per miscele binarie ha previsto in modo più accurato e coerente coefficienti di attività, composizioni di fase ed entalpie in eccesso rispetto al largamente usato metodo modified UNIFAC (Dortmund), identificando inoltre più affidabilmente i gap di miscibilità liquido–liquido. Per miscele ternarie e persino quaternarie, che non aveva mai visto durante l’addestramento, HANNA è rimasta competitiva o superiore, nonostante si basi unicamente su dati binari più la proiezione geometrica. Ha anche sovraperformato diverse recenti reti neurali basate su grafi che o mancavano di rigida coerenza termodinamica o erano limitate a condizioni speciali come la temperatura ambiente o la diluizione infinita.
Cosa significa per la scienza e l’industria
Per un non specialista il messaggio centrale è che HANNA agisce come un “oracolo” altamente informato e radicato fisicamente per le miscele liquide. Date soltanto le formule chimiche, può prevedere se due o più liquidi si mescoleranno, si separeranno in strati o presenteranno comportamenti di fase complessi, e lo fa in un ampio intervallo di temperature. Fondamentalmente, lo fa rispettando le regole termodinamiche sottostanti, riducendo il rischio di risultati non fisici che possono affliggere modelli di machine learning non vincolati. Poiché il modello completo e il codice sono rilasciati apertamente e accessibili tramite un’interfaccia web, gli ingegneri possono iniziare a usare HANNA direttamente in simulazioni di processo e screening di solventi. Pur riconoscendo limiti ancora presenti — come prestazioni non testate molto al di fuori dell’intervallo di temperatura di addestramento e per elettroliti forti — il lavoro segna un passo importante verso una progettazione di processi chimici guidata dai dati e coerente dal punto di vista termodinamico.
Citazione: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Parole chiave: miscele liquide, termodinamica, machine learning, energia libera di Gibbs in eccesso, equilibri di fase