Clear Sky Science · de
Thermodynamisch konsistentes Machine-Learning-Modell für die exzessive Gibbs-Energie
Warum das für die Alltagschemie wichtig ist
Das moderne Leben beruht auf Gemischen aus Flüssigkeiten – von Treibstoffen und Kältemitteln bis hin zu Arzneimitteln und grünen Lösungsmitteln. Diese Gemische sicher und effizient zu entwerfen, setzt voraus, dass man weiß, wie ihre Moleküle miteinander interagieren. Alle möglichen Kombinationen experimentell zu messen, ist jedoch unmöglich. Dieser Artikel stellt ein neues Machine-Learning-Tool namens HANNA vor, das das Verhalten von Flüssigkeitsgemischen direkt aus Daten erlernt und dabei gleichzeitig die grundlegenden Gesetze der Thermodynamik respektiert. Es verspricht schnellere, breitere und zuverlässigere Vorhersagen zur Unterstützung von Prozessdesign und Materialentdeckung.
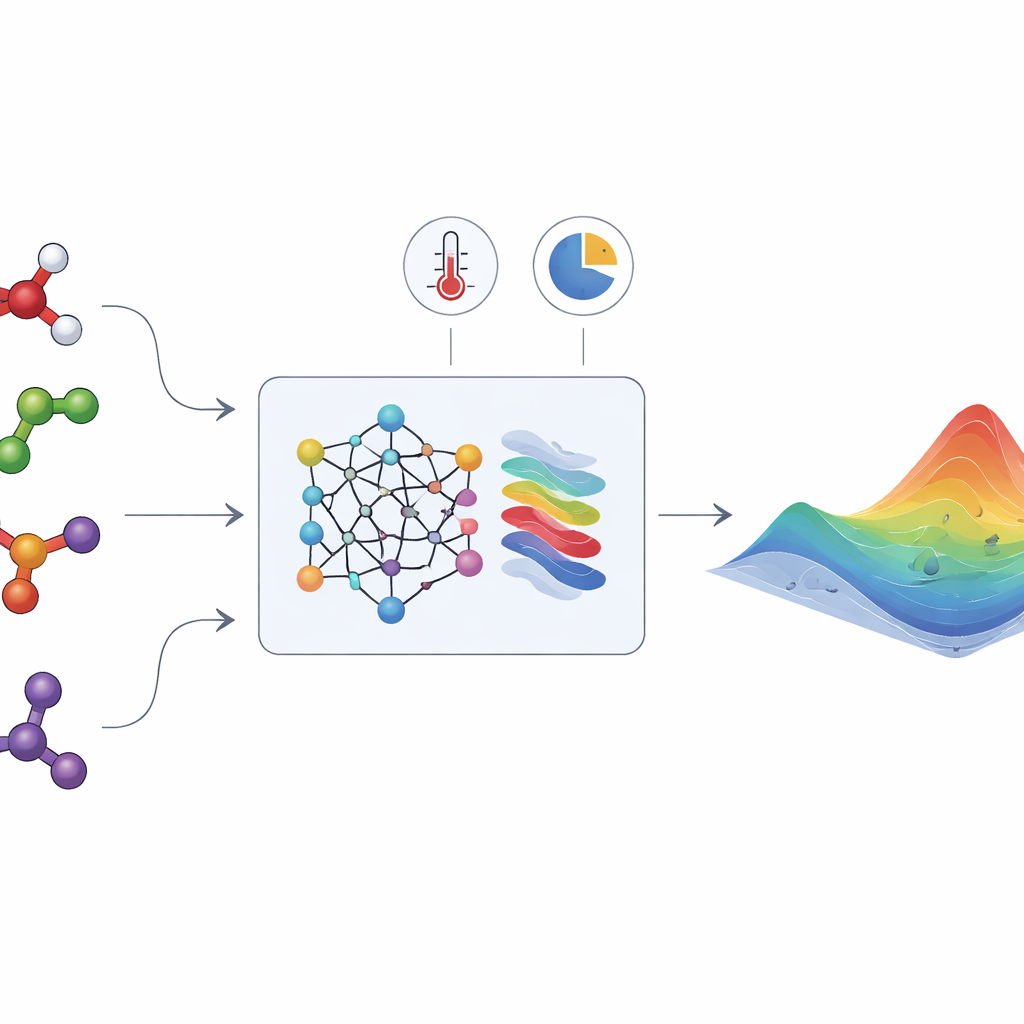
Die verborgene Energie, die Flüssigkeitsgemische formt
Wenn verschiedene Flüssigkeiten gemischt werden, ziehen sich ihre Moleküle an oder stoßen sich ab – oft auf subtile Weise. Diese Effekte werden in einer Größe namens „exzessive Gibbs-Energie“ erfasst, die angibt, wie sehr sich das Gemisch vom idealen Verhalten unterscheidet. Aus dieser einzigen Funktion können Ingenieure wichtige Eigenschaften ableiten, wie Aktivitätskoeffizienten, die wiederum bestimmen, ob ein Gemisch eine einzige Flüssigphase bildet oder sich in zwei aufspaltet, ob Dampf und Flüssigkeit koexistieren und wie Komponenten zwischen ihnen verteilt sind. Leider lässt sich die exzessive Gibbs-Energie nicht direkt messen. Sie muss aus mühsamen Experimenten zu Dampf–Flüssig- und Flüssig–Flüssig-Gleichgewichten oder Wärmeeffekten erschlossen werden, und nur ein winziger Bruchteil aller relevanten Gemische wurde jemals untersucht.
Beschränkungen traditioneller Vorhersagewerkzeuge
Jahrzehntelang vertrauten Ingenieure auf Modelle wie NRTL, UNIQUAC und die UNIFAC-Familie zur Abschätzung des Gemischverhaltens. Diese Methoden nähern Wechselwirkungen über Parameter an, die an experimentelle Daten angepasst werden, oft paarweise. Zwar sind sie leistungsfähig, haben aber wichtige Einschränkungen: Für die Vorhersage eines neuen Gemisches benötigt man in der Regel Parameter für jedes binäre Teilsystem, das darin vorkommt, und solche Parameter existieren möglicherweise nicht für neuartige Verbindungen. Selbst gruppenbasierte Ansätze wie UNIFAC, die Moleküle in Bausteine zerlegen, sind auf einen festen Katalog von Gruppen beschränkt und tun sich mit komplexen Spezies wie ionischen Flüssigkeiten schwer. Außerdem fällt es vielen klassischen Modellen schwer, sowohl Dampf–Flüssig- als auch Flüssig–Flüssig-Gleichgewichte mit einem einzigen Parametersatz genau zu beschreiben.
Ein neuronales Netzwerk, das physikalische Gesetze befolgt
HANNA begegnet diesen Herausforderungen, indem es moderne neuronale Netze mit fest verdrahteten thermodynamischen Regeln kombiniert. Als Eingabe benötigt es nur die molekularen Strukturen der Komponenten (kodiert als SMILES-Strings), die Temperatur und die Gemischzusammensetzung. Ein chemischer Sprachmodell-Encoder (ChemBERTa-2) wandelt zunächst jedes Molekül in einen numerischen Fingerabdruck um. Diese Fingerabdrücke fließen in eine spezialisierte Netzwerkarchitektur, die so konstruiert ist, dass sie wesentliche Konsistenzanforderungen erfüllt: Sie respektiert die Gibbs–Duhem-Relation, verhält sich korrekt, wenn eine Komponente rein oder unendlich verdünnt wird, und liefert dieselbe Antwort unabhängig von der Reihenfolge der Komponenten. Aus diesen Zwängen sagt HANNA die exzessive Gibbs-Energie für jedes binäre Paar in einem Gemisch voraus und nutzt dann ein geometrisches Projektschema, um diese Vorhersagen auf Gemische mit vielen Komponenten zu erweitern, ohne zusätzliche Anpassungsparameter einzuführen.
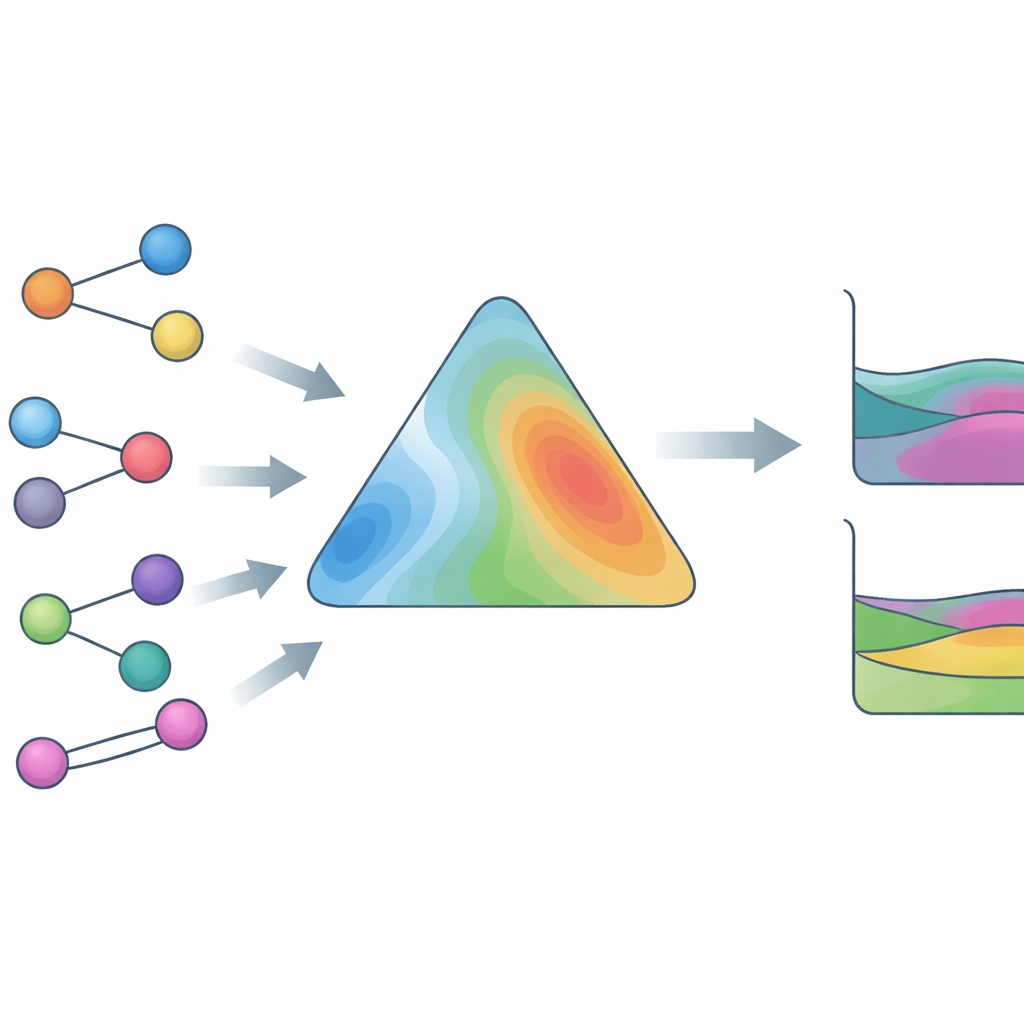
Training mit realen Daten, nicht nur Gleichungen
Um HANNA breit einsetzbar zu machen, trainierten die Autoren das Modell an einer außergewöhnlich großen und vielfältigen experimentellen Datenbank. Diese enthält Dampf–Flüssig-Daten mit vollständigen Phasenzusammensetzungen, Dampf–Flüssig-Daten mit nur Gesamtdrücken, Flüssig–Flüssig-Phasentrennungen, Aktivitätskoeffizienten bei unendlicher Verdünnung und exzessive Enthalpien und umfasst mehr als 800.000 Datenpunkte und über 4.000 verschiedene Verbindungen, darunter ionische Flüssigkeiten und andere herausfordernde Spezies. Eine wichtige Innovation ist ein Surrogat-Solver, der einen robusten thermodynamischen Algorithmus zur Erkennung und Lokalisierung von Flüssig–Flüssig-Trennungen nachahmt. Dieses Surrogat ist differenzierbar, sodass HANNA „end-to-end“ gegen gemessene Phasenzusammensetzungen trainiert werden kann, ohne langsame iterative Berechnungen in die Lernschleife einzubauen. Zusätzliche Verlustterme bringen HANNA bei, die Krümmung im Zusammenhang mit Phasentrennungen zu erkennen und glatte Vorhersagen zu liefern, die sich auch außerhalb des Trainingsbereichs sinnvoll verhalten.
Wie sich das neue Modell schlägt
Nach dem Training wurde HANNA nur an Systemen getestet, die während des Trainings zurückgehalten wurden, und seine Leistung mit führenden klassischen und Machine-Learning-Modellen verglichen. Für binäre Gemische sagte es konsistent Aktivitätskoeffizienten, Phasenzusammensetzungen und exzessive Enthalpien genauer voraus als die weithin verwendete modifizierte UNIFAC-(Dortmund)-Methode und identifizierte gleichzeitig Flüssig–Flüssig-Unverträglichkeitsbereiche zuverlässiger. Für ternäre und sogar quaternäre Gemische, die es während des Trainings nie gesehen hatte, blieb HANNA trotz der ausschließlichen Nutzung binärer Daten plus der geometrischen Projektion wettbewerbsfähig oder überlegen. Es übertraf auch mehrere neuere graphbasierte neuronale Netze, denen entweder strikte thermodynamische Konsistenz fehlte oder die auf Spezialbedingungen wie Raumtemperatur oder unendliche Verdünnung beschränkt waren.
Was das für Wissenschaft und Industrie bedeutet
Für Nicht-Spezialisten ist die zentrale Aussage: HANNA fungiert wie ein gut informiertes, physikalisch fundiertes „Orakel“ für Flüssigkeitsgemische. Ausgehend nur von den chemischen Formeln kann es vorhersagen, ob sich zwei oder mehrere Flüssigkeiten mischen, in Schichten aufspalten oder komplexes Phasenverhalten zeigen, und das über einen weiten Temperaturbereich. Entscheidend ist, dass es dies unter Wahrung der zugrunde liegenden thermodynamischen Regeln tut und so das Risiko unphysikalischer Ergebnisse verringert, die bei unbeschränkten Machine-Learning-Modellen auftreten können. Da das vollständige Modell und der Code offen veröffentlicht und über eine Weboberfläche zugänglich sind, können Ingenieure HANNA direkt in Prozesssimulationen und bei der Lösungsmittelauswahl einsetzen. Zwar weisen die Autoren auf verbleibende Einschränkungen hin – etwa ungetestete Leistungen weit außerhalb des Trainings-Temperaturbereichs und bei starken Elektrolyten – doch stellt die Arbeit einen wichtigen Schritt hin zu datengetriebener, thermodynamisch konsistenter Gestaltung chemischer Prozesse dar.
Zitation: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Schlüsselwörter: Flüssigkeitsgemische, Thermodynamik, Machine Learning, exzessive Gibbs-Energie, Phasengleichgewichte