Clear Sky Science · nl
Thermodynamisch consistente machine-learningmodel voor excessieve Gibbsenergie
Waarom dit van belang is voor alledaagse scheikunde
Het moderne leven steunt op mengsels van vloeistoffen, van brandstoffen en koudemiddelen tot geneesmiddelen en groene oplosmiddelen. Het veilig en efficiënt ontwerpen van deze mengsels vereist inzicht in hoe hun moleculen op elkaar inwerken. Het is echter onmogelijk om die interacties voor elke mogelijke combinatie te meten. Dit artikel presenteert een nieuw machine-learninginstrument, HANNA genaamd, dat het gedrag van vloeistofmengsels rechtstreeks uit data leert, terwijl het toch de basale wetten van de thermodynamica respecteert. Het belooft snellere, bredere en betrouwbaardere voorspellingen om het ontwerp van chemische processen en de ontdekking van materialen te sturen.
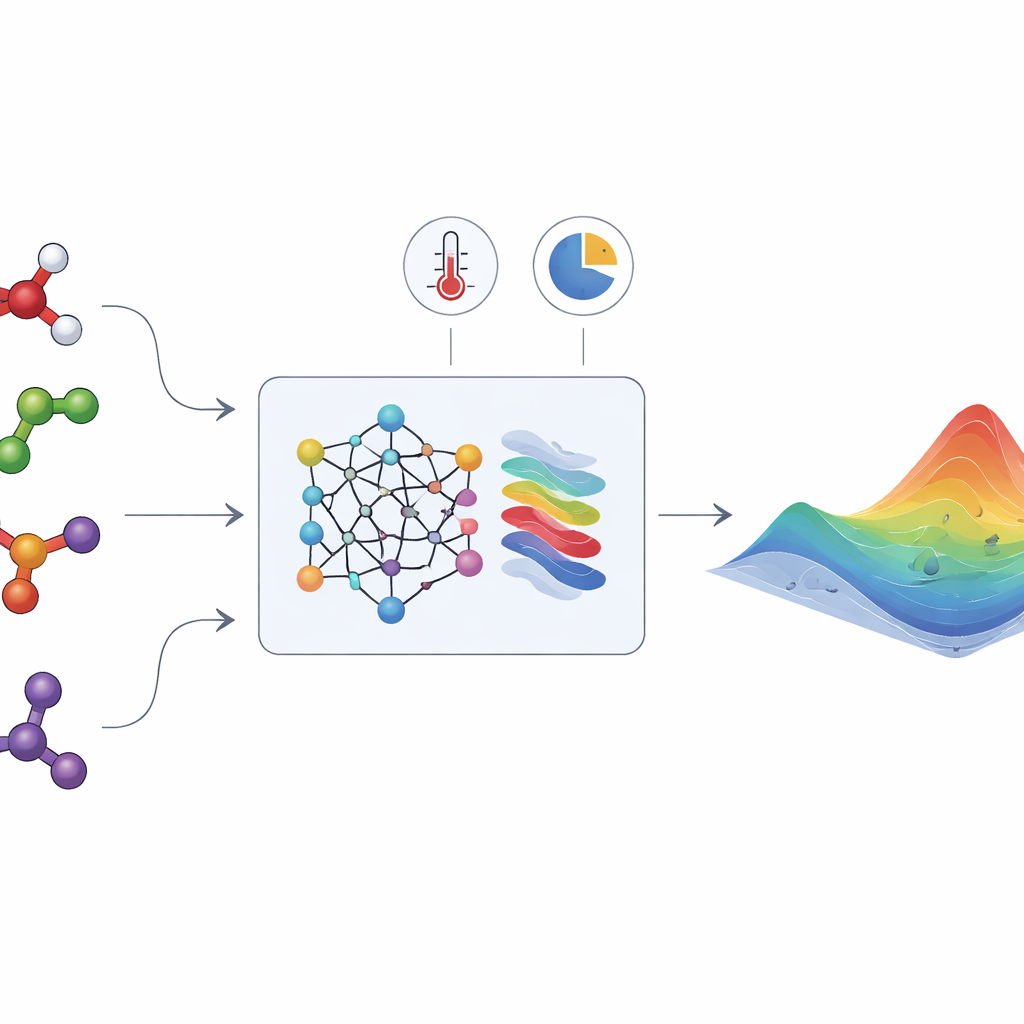
De verborgen energie die vloeistofmengsels vormt
Wanneer verschillende vloeistoffen worden gemengd, trekken of stoten hun moleculen elkaar op vaak subtiele manieren af. Deze effecten worden vastgelegd in een grootheid die de "excessieve Gibbsenergie" wordt genoemd, en die aangeeft hoe sterk het mengsel afwijkt van ideaal gedrag. Vanuit deze enkele functie kunnen ingenieurs sleutelgrootheden afleiden zoals activiteitscoëfficiënten, die op hun beurt bepalen of een mengsel één vloeistoffase vormt of in tweeën splitst, of damp en vloeistof naast elkaar bestaan, en hoe componenten zich daartussen verdelen. Helaas is de excessieve Gibbsenergie niet direct meetbaar. Ze moet worden afgeleid uit moeizame experimenten aan damp–vloeistof- en vloeistof–vloeistof-evenwichten of warmte-effecten, en slechts een klein deel van alle relevante mengsels is ooit bestudeerd.
Beperkingen van traditionele voorspellingsmethoden
Decennialang vertrouwden ingenieurs op modellen zoals NRTL, UNIQUAC en de UNIFAC-familie om het gedrag van mengsels te schatten. Deze methoden benaderen interacties met parameters die passen bij experimentele gegevens, vaak op paarbasis. Hoewel krachtig, hebben ze belangrijke beperkingen: om een nieuw mengsel te voorspellen heb je doorgaans parameters nodig voor elk binair subsysteem dat erin voorkomt, en die bestaan mogelijk niet voor nieuwe verbindingen. Zelfs groepsgebaseerde benaderingen zoals UNIFAC, die moleculen in bouwstenen ontleden, zijn gebonden aan een vast catalogus van groepen en kunnen moeite hebben met complexe soorten zoals ionische vloeistoffen. Bovendien vinden veel klassieke modellen het lastig om zowel damp–vloeistof- als vloeistof–vloeistof-evenwichten nauwkeurig te beschrijven met één set parameters.
Een neurale netwerk dat zich aan natuurwetten houdt
HANNA pakt deze uitdagingen aan door moderne neurale netwerken te combineren met ingebakken thermodynamische regels. Als invoer heeft het alleen de moleculaire structuren van de componenten nodig (gecodeerd als SMILES-strings), de temperatuur en de mengselcompositie. Een chemisch taalmodel (ChemBERTa-2) zet eerst elk molecuul om in een numerieke vingerafdruk. Deze vingerafdrukken voeden een gespecialiseerde netwerkarchitectuur die is ontworpen om aan belangrijke consistentie-eisen te voldoen: het respecteert de Gibbs–Duhem-relatie, gedraagt zich correct wanneer een component zuiver wordt of oneindig verdund raakt, en geeft hetzelfde antwoord ongeacht de ordening van de componenten. Vanuit deze randvoorwaarden voorspelt HANNA de excessieve Gibbsenergie voor elk binair paar in een mengsel en gebruikt vervolgens een geometrisch projectieschema om die voorspellingen uit te breiden naar mengsels met veel componenten, zonder extra afstemmingsparameters toe te voegen.
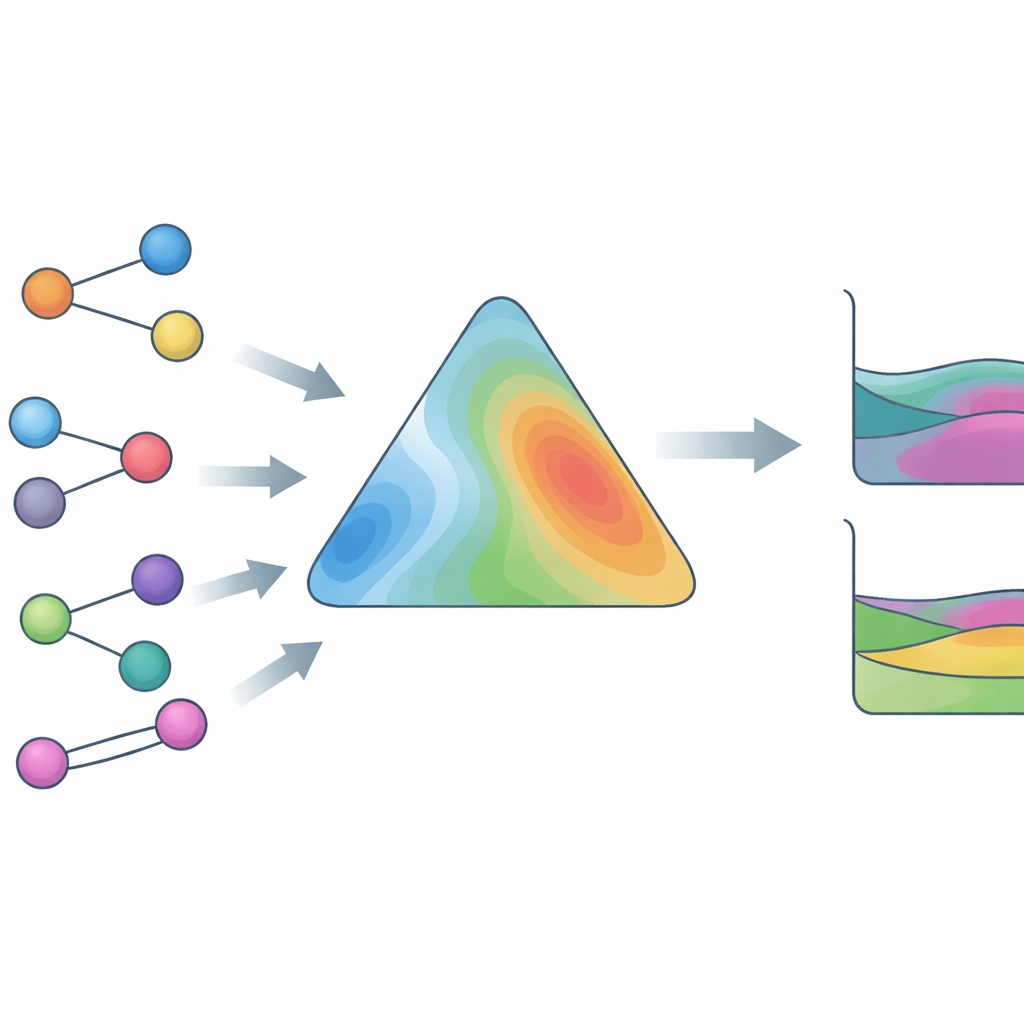
Getraind op echte data, niet alleen vergelijkingen
Om HANNA breed inzetbaar te maken, hebben de auteurs het getraind op een uitzonderlijk grote en diverse experimentele database. Die bevat damp–vloeistofgegevens met volledige fasecomposities, damp–vloeistofgegevens met alleen totale drukken, vloeistof–vloeistof-fasesplitsingen, activiteitscoëfficiënten bij oneindige verdunning en excessieve enthalpieën, in totaal meer dan 800.000 datapunten en meer dan 4.000 verschillende verbindingen, inclusief ionische vloeistoffen en andere uitdagende soorten. Een belangrijke innovatie is een surrogaatsolver die een robuust thermodynamisch algoritme nabootst voor het detecteren en lokaliseren van vloeistof–vloeistof-splitsingen. Deze surrogaatsolver is differentieerbaar, zodat HANNA "end-to-end" kan worden getraind tegen gemeten fasecomposities zonder gebruik te maken van trage iteratieve berekeningen in de leerlus. Extra verlies-termen stimuleren HANNA om de kromming geassocieerd met fasescheiding te herkennen en om vloeiende voorspellingen te produceren die zich zinvol gedragen zelfs buiten het trainingsbereik.
Hoe het nieuwe model presteert
Eens getraind werd HANNA alleen getest op systemen die tijdens de training waren weggelaten, en werd de prestatie vergeleken met toonaangevende klassieke en machine-learningmodellen. Voor binaire mengsels voorspelde het consequent activiteitscoëfficiënten, fasecomposities en excessieve enthalpieën nauwkeuriger dan de veelgebruikte gemodificeerde UNIFAC (Dortmund)-methode, en identificeerde het ook vloeistof–vloeistof-mengbaarheidszones betrouwbaarder. Voor tertiaire en zelfs quaternaire mengsels, die het nooit tijdens training had gezien, bleef HANNA concurrerend of superieur, ondanks dat het uitsluitend op binaire data plus de geometrische projectie steunde. Het overtrof ook verschillende recente grafgebaseerde neurale netwerken die ofwel strikte thermodynamische consistentie misten of beperkt waren tot speciale condities zoals kamertemperatuur of oneindige verdunning.
Wat dit betekent voor wetenschap en industrie
Voor niet-specialisten is de kernboodschap dat HANNA functioneert als een sterk geïnformeerde, fysisch gefundeerde "orakel" voor vloeistofmengsels. Alleen aan de hand van de chemische formules kan het voorspellen of twee of meer vloeistoffen zullen mengen, in lagen zullen splitsen of complex fasegedrag zullen vertonen, en dat over een breed temperatuurbereik. Cruciaal is dat het dit doet terwijl het de onderliggende thermodynamische regels eerbiedigt, waardoor het risico op niet-fysische resultaten dat ongebonden machine-learningmodellen kan teisteren, wordt verminderd. Omdat het volledige model en de code open zijn vrijgegeven en toegankelijk via een webinterface, kunnen ingenieurs HANNA direct gebruiken in proces-simulatie en oplosmiddelselectie. Hoewel de auteurs nog bestaande beperkingen opmerken — zoals ongeteste prestaties ver buiten het trainings-temperatuurbereik en bij sterke elektrolyten — markeert dit werk een belangrijke stap richting datagedreven, thermodynamisch consistente ontwerp van chemische processen.
Bronvermelding: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Trefwoorden: vloeistofmengsels, thermodynamica, machine learning, excessieve Gibbsenergie, fase-evenwichten