Clear Sky Science · ja
余剰ギブズエネルギーのための熱力学的一貫性を備えた機械学習モデル
日常の化学でなぜ重要か
現代の生活は、燃料や冷媒から医薬品やグリーン溶媒に至るまで、さまざまな液体の混合物に依存しています。これらの混合物を安全かつ効率的に設計するには、分子同士がどのように相互作用するかを知る必要があります。しかし、あり得る全ての組み合わせについて相互作用を測定することは不可能です。本稿ではHANNAと呼ばれる新しい機械学習ツールを紹介します。HANNAはデータから直接液体混合物の挙動を学習しつつ、熱力学の基本法則を尊重します。これにより、化学プロセス設計や材料探索を導く予測がより迅速に、広範に、そして信頼性高く行える見込みです。
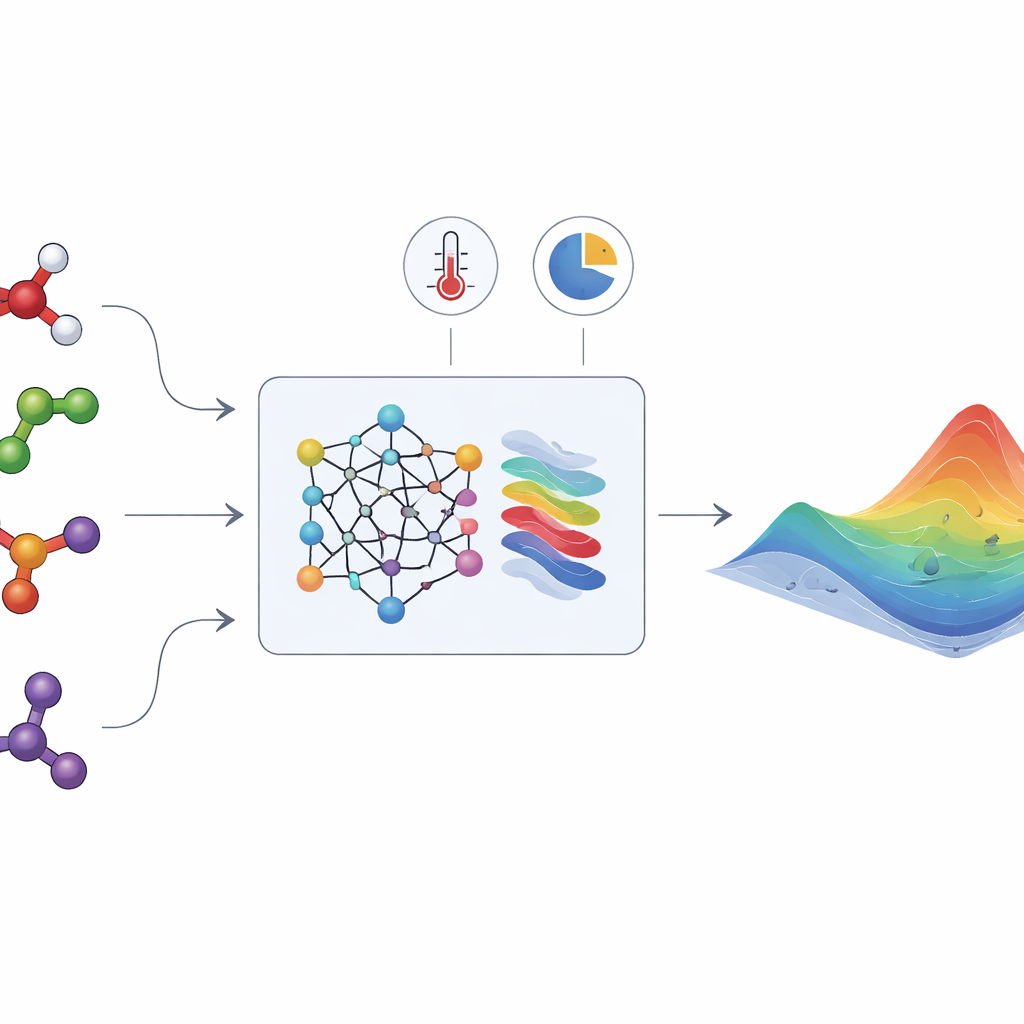
液体混合物を形作る隠れたエネルギー
異なる液体を混合すると、分子同士が引き合ったり反発したりする微妙な挙動が現れます。これらの効果は「余剰ギブズエネルギー」と呼ばれる量で表され、混合物が理想挙動からどれだけ逸脱しているかを示します。この単一の関数から、工学者は活量係数などの重要な物性を導き出せます。これらは混合物が一相を保つか二相に分かれるか、気相と液相が共存するか、成分が各相にどのように分配するかを決定します。残念ながら、余剰ギブズエネルギーは直接測定できません。蒸気–液相や液–液相平衡、熱効果に関する地道な実験から推定する必要があり、関連する混合物のごく一部しか研究されていません。
従来の予測手法の限界
数十年にわたり、工学者はNRTL、UNIQUAC、UNIFAC系列などのモデルを用いて混合物の挙動を推定してきました。これらの手法は実験データに合わせて調整されるパラメータを通じて相互作用を近似し、しばしば二成分ごとの取り扱いをします。強力ではあるものの重要な制約があります:新しい混合物を予測するには通常、その混合物に現れるあらゆる二元部分系のパラメータが必要であり、新規化合物ではそれらが存在しないことがあります。分子を構成要素に分解するUNIFACのようなグループベースの手法でさえ、固定されたグループ目録に制約され、イオン液体のような複雑な種には困難を伴うことがあります。さらに、多くの古典的モデルは、単一のパラメータセットで蒸気–液相と液–液相の両方を正確に記述するのが難しいことが知られています。
物理法則に従うニューラルネットワーク
HANNAは、最新のニューラルネットワークと組み込まれた熱力学ルールを組み合わせることでこれらの課題に取り組みます。入力として必要なのは成分の分子構造(SMILES文字列で符号化)、温度、混合組成だけです。化学言語モデル(ChemBERTa-2)が各分子を数値的なフィンガープリントに変換します。これらのフィンガープリントは、ギブズ–デュヘム関係を満たすこと、ある成分が純物質や無限希釈になる極限で正しく振る舞うこと、成分の順序に依らず同一の答えを返すことといった主要な一貫性要件を満たすように設計された特殊なネットワーク構造に供給されます。これらの制約から、HANNAは混合物中のあらゆる二成分ペアの余剰ギブズエネルギーを予測し、それらの予測を幾何学的射影スキームで多成分混合物へと拡張しますが、追加のフィッティングパラメータは導入しません。
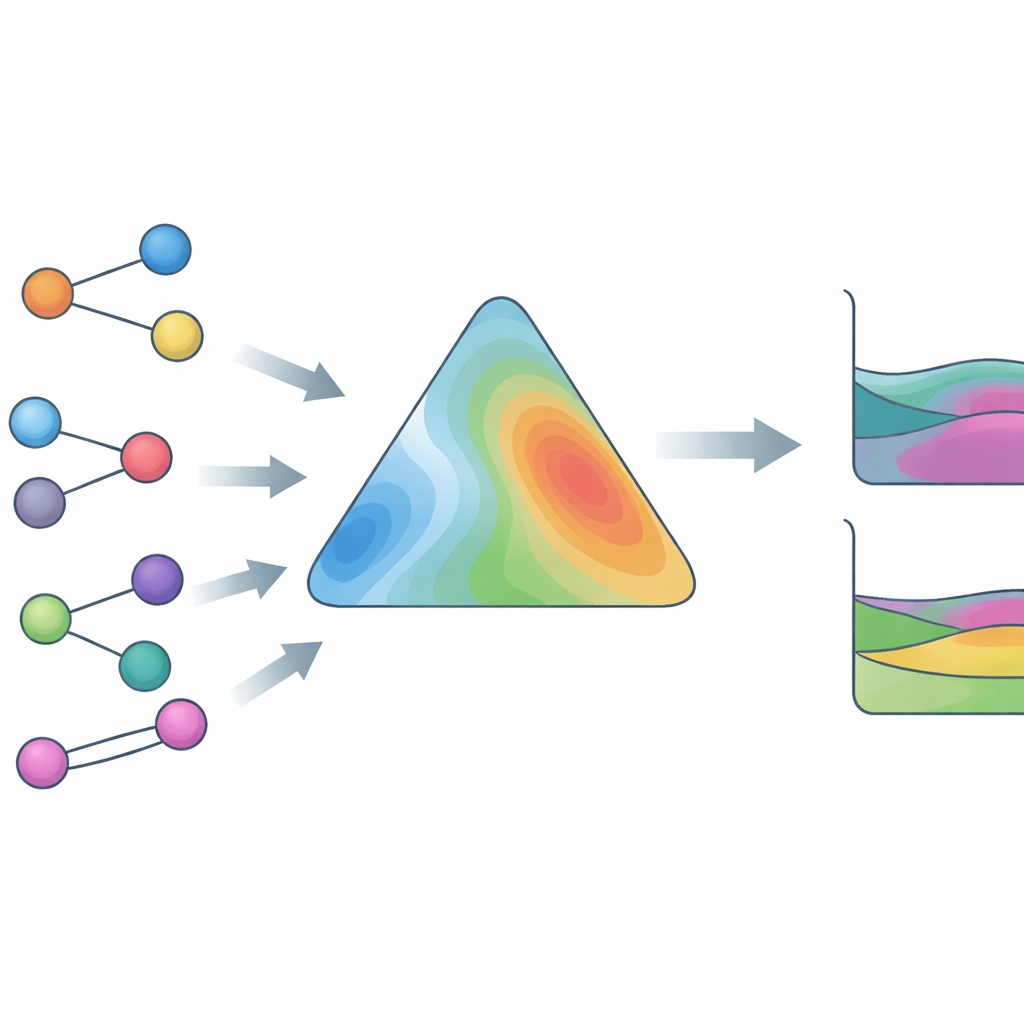
方程式だけでなく実データで学習
HANNAを広く有用にするため、著者らは極めて大規模で多様な実験データベースで訓練しました。これには完全な相組成を含む蒸気–液相データ、全圧のみの蒸気–液相データ、液–液相分離、無限希釈での活量係数、余剰エンタルピーが含まれ、80万点以上のデータポイントと4,000種以上の異なる化合物(イオン液体や他の扱いにくい種を含む)を網羅します。重要な革新は、液–液相分離を検出して位置を特定する堅牢な熱力学アルゴリズムを模倣する代替ソルバーです。この代替ソルバーは微分可能であるため、HANNAは学習ループ内で遅い反復計算に頼ることなく、測定された相組成に対して「エンドツーエンド」で訓練できます。追加の損失項は、相分離に関連する曲率を認識させ、訓練範囲外でも分かりやすく挙動する滑らかな予測を生み出すことを促します。
新モデルの性能はどのようなものか
訓練後、HANNAは訓練時に保持しておいた系でのみテストされ、その性能は主要な古典モデルや機械学習モデルと比較されました。二成分混合物については、HANNAは広く用いられる修正版UNIFAC(ドルトムント法)よりも一貫して活量係数、相組成、余剰エンタルピーを高精度で予測し、液–液混和ギャップの検出もより信頼性が高いことが示されました。三成分や四成分の混合物でも、訓練で見たことのない組み合わせに対してHANNAは二成分データと幾何学的射影のみを用いて競争力ある、あるいはそれを上回る性能を維持しました。また、厳密な熱力学的一貫性を欠くか、常温や無限希釈など特定条件に限られるいくつかの最近のグラフベースニューラルネットワークよりも優れていました。
科学と産業にとっての意味
非専門家にとっての中心的メッセージは、HANNAが液体混合物に関する高度に情報化され物理に根ざした「オラクル」のように振る舞うということです。化学式だけから、二つ以上の液体が混和するか、層に分かれるか、複雑な相挙動を示すかを幅広い温度範囲で予測できます。重要なのは、これを熱力学の基本法則を守りながら行うため、非制約の機械学習モデルに見られる非物理的な結果が生じにくい点です。完全なモデルとコードは公開され、ウェブインターフェースを通じても利用できるため、エンジニアはプロセスシミュレーションや溶媒探索にHANNAを直接活用できます。著者らは訓練温度範囲を大きく外れる場合や強電解質に対する未検証の性能といった残る制限を指摘していますが、本研究はデータ駆動で熱力学的一貫性を備えた化学プロセス設計に向けた重要な一歩を示しています。
引用: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
キーワード: 液体混合物, 熱力学, 機械学習, 余剰ギブズエネルギー, 相平衡