Clear Sky Science · es
Modelo de aprendizaje automático termodinámicamente consistente para la energía libre de Gibbs excedente
Por qué esto importa para la química cotidiana
La vida moderna depende de mezclas de líquidos, desde combustibles y refrigerantes hasta productos farmacéuticos y disolventes sostenibles. Diseñar estas mezclas de forma segura y eficiente requiere conocer cómo interactúan sus moléculas. Sin embargo, medir esas interacciones para todas las combinaciones posibles es imposible. Este artículo presenta una nueva herramienta de aprendizaje automático, llamada HANNA, que aprende el comportamiento de las mezclas líquidas directamente a partir de datos al tiempo que respeta las leyes básicas de la termodinámica. Promete predicciones más rápidas, amplias y fiables para orientar el diseño de procesos químicos y el descubrimiento de materiales.
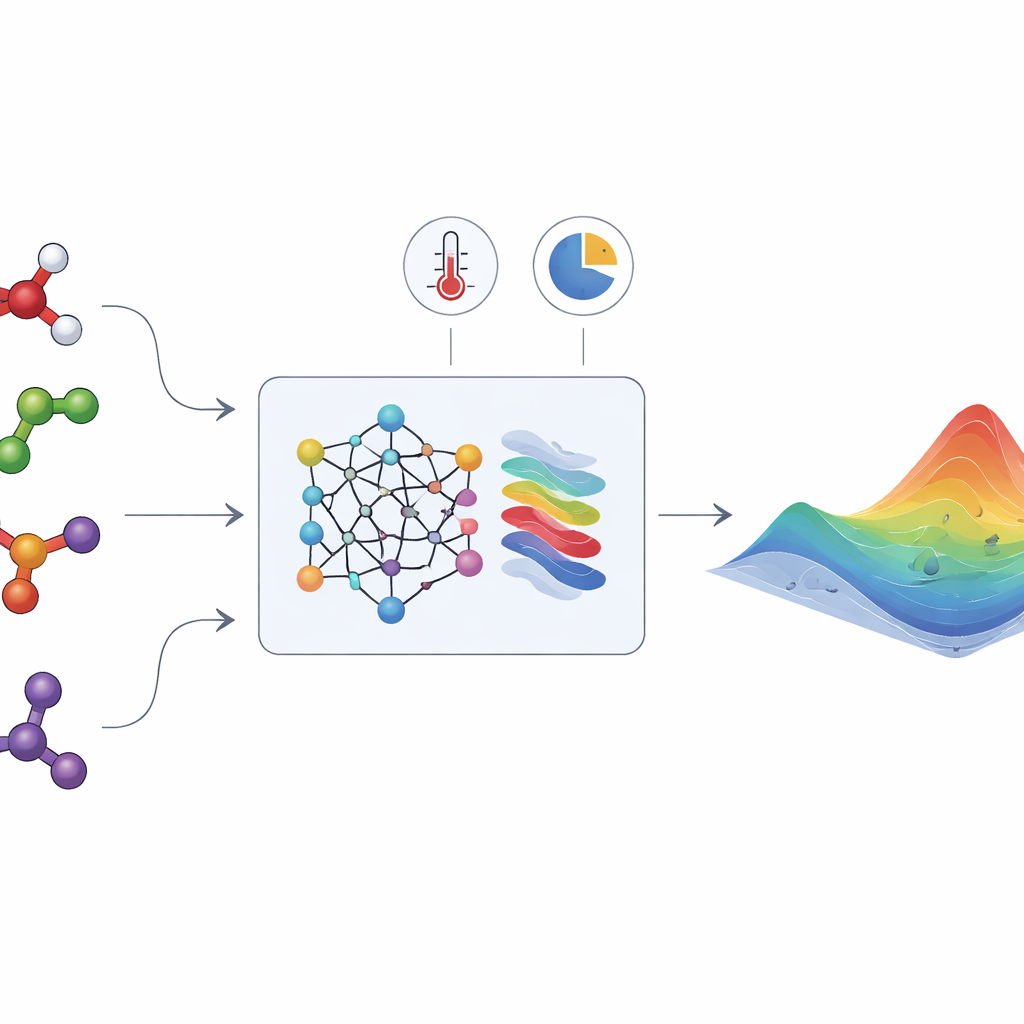
La energía oculta que moldea las mezclas líquidas
Cuando se mezclan diferentes líquidos, sus moléculas se atraen o repelen de formas que pueden ser bastante sutiles. Estos efectos quedan recogidos en una magnitud denominada “energía libre de Gibbs excedente”, que indica cuánto se desvía la mezcla del comportamiento ideal. A partir de esta única función, los ingenieros pueden derivar propiedades clave como los coeficientes de actividad, que a su vez determinan si una mezcla forma una sola fase líquida o se separa en dos, si vapor y líquido coexisten y cómo se distribuyen los componentes entre ellas. Desafortunadamente, la energía libre de Gibbs excedente no puede medirse directamente. Debe inferirse a partir de experimentos meticulosos sobre equilibrios vapor–líquido y líquido–líquido o efectos térmicos, y solo una pequeña fracción de las mezclas relevantes ha sido estudiada.
Límites de las herramientas tradicionales de predicción
Durante décadas, los ingenieros han confiado en modelos como NRTL, UNIQUAC y la familia UNIFAC para estimar el comportamiento de mezclas. Estos métodos aproximan las interacciones mediante parámetros ajustados a datos experimentales, a menudo en base binaria. Aunque potentes, tienen limitaciones importantes: para predecir una mezcla nueva, normalmente se necesitan parámetros para cada subsistema binario que aparece en ella, y esos parámetros pueden no existir para compuestos novedosos. Incluso enfoques basados en grupos como UNIFAC, que descomponen moléculas en bloques, están confinados a un catálogo fijo de grupos y pueden tener dificultades con especies complejas como líquidos iónicos. Además, muchos modelos clásicos encuentran difícil describir con exactitud tanto equilibrios vapor–líquido como líquido–líquido con un solo conjunto de parámetros.
Una red neuronal que obedece las leyes físicas
HANNA aborda estos retos combinando redes neuronales modernas con reglas termodinámicas integradas. Como entrada, solo necesita las estructuras moleculares de los componentes (codificadas como cadenas SMILES), la temperatura y la composición de la mezcla. Un modelo de lenguaje químico (ChemBERTa-2) convierte primero cada molécula en una huella numérica. Estas huellas alimentan una arquitectura de red especializada diseñada para respetar requisitos de consistencia clave: satisface la relación de Gibbs–Duhem, se comporta correctamente cuando un componente se vuelve puro o infinitamente diluido, y da la misma respuesta independientemente del orden de los componentes. A partir de estas restricciones, HANNA predice la energía libre de Gibbs excedente para cada par binario en una mezcla y luego utiliza un esquema de proyección geométrica para extender esas predicciones a mezclas con muchos componentes, sin introducir parámetros de ajuste adicionales.
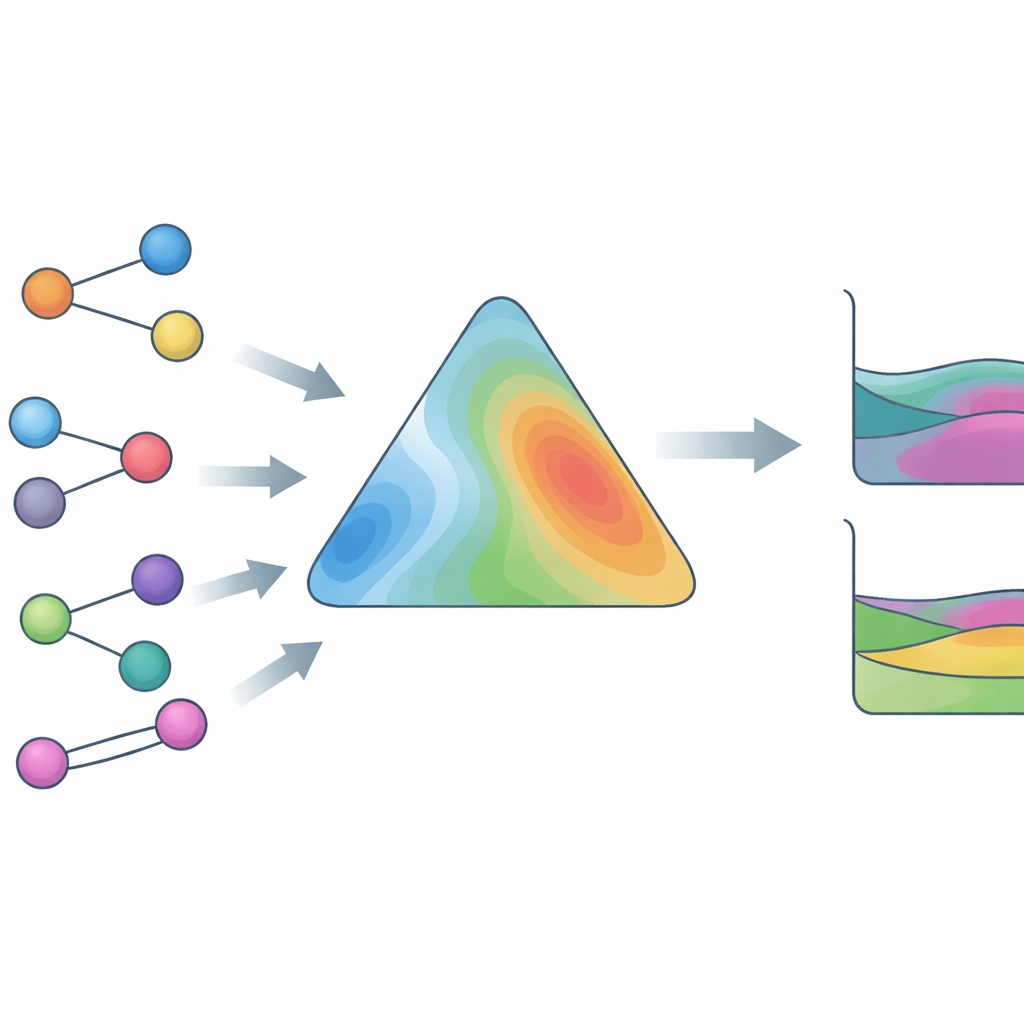
Entrenado con datos reales, no solo ecuaciones
Para que HANNA resulte ampliamente útil, los autores lo entrenaron con una base de datos experimental excepcionalmente grande y diversa. Esto incluye datos vapor–líquido con composiciones de fase completas, datos vapor–líquido solo con presiones totales, separaciones líquido–líquido, coeficientes de actividad en dilución infinita y entalpías de exceso, cubriendo más de 800.000 puntos de datos y más de 4.000 compuestos distintos, incluidos líquidos iónicos y otras especies difíciles. Una innovación clave es un solucionador sustituto que emula un algoritmo termodinámico robusto para detectar y localizar separaciones líquido–líquido. Este sustituto es diferenciable, por lo que HANNA puede entrenarse de forma «end-to-end» contra composiciones de fase medidas sin recurrir a cálculos iterativos lentos dentro del bucle de aprendizaje. Términos de pérdida adicionales fomentan que HANNA reconozca la curvatura asociada a la separación de fases y produzca predicciones suaves que se comporten de forma razonable incluso fuera del rango de entrenamiento.
Cómo se compara el nuevo modelo
Una vez entrenada, HANNA se probó únicamente en sistemas reservados durante el entrenamiento, y su rendimiento se comparó con modelos clásicos y de aprendizaje automático líderes. Para mezclas binarias, predijo de forma consistente los coeficientes de actividad, las composiciones de fase y las entalpías de exceso con mayor precisión que el ampliamente usado UNIFAC modificado (Dortmund), además de identificar con más fiabilidad las brechas de miscibilidad líquido–líquido. Para mezclas ternarias e incluso cuaternarias, que nunca había visto durante el entrenamiento, HANNA siguió siendo competitiva o superior, a pesar de basarse únicamente en datos binarios más la proyección geométrica. También superó a varias redes neuronales recientes basadas en grafos que o bien carecían de estricta consistencia termodinámica o estaban limitadas a condiciones especiales como temperatura ambiente o dilución infinita.
Qué significa esto para la ciencia y la industria
Para un público no especializado, el mensaje central es que HANNA actúa como un «oráculo» muy informado y físicamente fundamentado para mezclas líquidas. Dadas solo las fórmulas químicas, puede predecir si dos o más líquidos se mezclarán, se separarán en capas o exhibirán comportamientos de fase complejos, y lo hace a lo largo de un amplio rango de temperaturas. Crucialmente, lo hace respetando las reglas termodinámicas subyacentes, lo que reduce el riesgo de resultados no físicos que pueden afectar a modelos de aprendizaje automático sin restricciones. Como el modelo y el código completos se publican abiertamente y son accesibles mediante una interfaz web, los ingenieros pueden empezar a usar HANNA directamente en simulación de procesos y cribado de disolventes. Aunque los autores señalan limitaciones pendientes—como el rendimiento no probado muy fuera del rango de temperatura de entrenamiento y para electrólitos fuertes—el trabajo marca un avance importante hacia el diseño dirigido por datos y termodinámicamente consistente de procesos químicos.
Cita: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Palabras clave: mezclas líquidas, termodinámica, aprendizaje automático, energía libre de Gibbs excedente, equilibrios de fases