Clear Sky Science · ru
Термо́динамически согласованная модель машинного обучения для избытка энергии Гиббса
Почему это важно для повседневной химии
Современная жизнь опирается на смеси жидкостей — от топлив и хладагентов до фармацевтики и «зелёных» растворителей. Безопасная и эффективная разработка таких смесей зависит от знания того, как взаимодействуют их молекулы. Измерить эти взаимодействия для каждой возможной комбинации невозможно. В статье представлен новый инструмент машинного обучения под названием HANNA, который изучает поведение жидких смесей непосредственно по данным, но при этом соблюдает базовые законы термодинамики. Это обещает более быстрые, широкие и надёжные предсказания для проектирования химических процессов и поиска материалов.
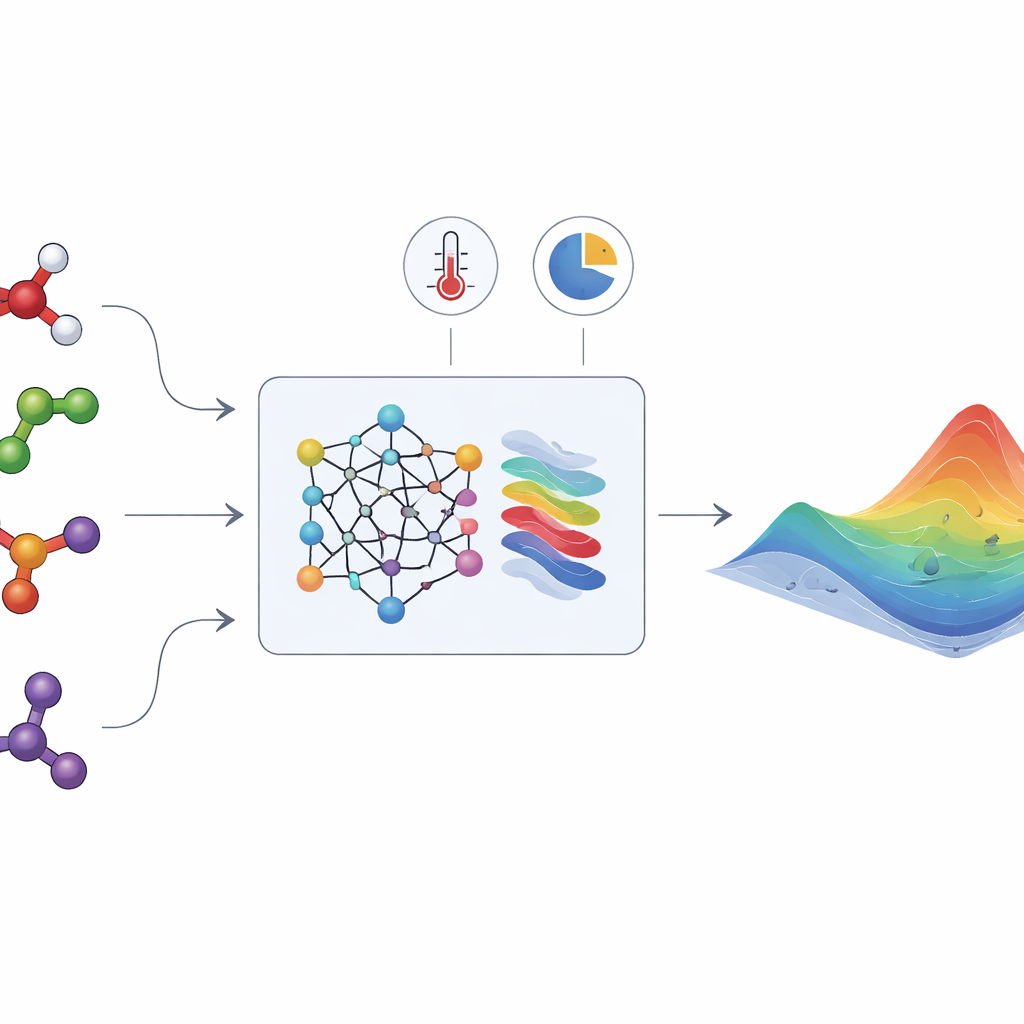
Скрытая энергия, формирующая жидкие смеси
При смешивании разных жидкостей молекулы притягиваются или отталкиваются друг от друга весьма тонкими способами. Эти эффекты описывает величина, называемая «избытком энергии Гиббса», которая показывает, насколько смесь отклоняется от идеального поведения. По этой единственной функции инженеры могут получить ключевые величины, такие как коэффициенты активности, которые, в свою очередь, определяют, образует ли смесь одну жидкую фазу или разделяется на две, сосуществуют ли пар и жидкость и как компоненты распределяются между ними. К сожалению, избыток энергии Гиббса нельзя измерить напрямую. Его приходится выводить из кропотливых экспериментов по паро–жидкостным и жидкостно–жидкостным равновесиям или тепловым эффектам, и изучена лишь мизерная доля всех релевантных смесей.
Ограничения традиционных инструментов предсказания
Десятилетиями инженеры полагались на модели вроде NRTL, UNIQUAC и семейство UNIFAC для оценки поведения смесей. Эти методы аппроксимируют взаимодействия через параметры, подгоняемые под экспериментальные данные, часто для каждой пары компонентов. Несмотря на свою мощь, у них есть важные ограничения: для прогноза новой смеси обычно требуются параметры для каждой бинарной подсистемы в ней, а для новых соединений такие параметры могут отсутствовать. Даже групповые подходы вроде UNIFAC, разлагающие молекулы на строительные блоки, ограничены фиксированным каталогом групп и испытывают трудности с сложными видами, например с ионными жидкостями. Более того, многим классическим моделям трудно одновременно точно описывать паро–жидкостные и жидкостно–жидкостные равновесия одним набором параметров.
Нейросеть, которая подчиняется физическим законам
HANNA решает эти задачи, сочетая современные нейронные сети с жёстко заданными термодинамическими правилами. На вход ей нужны только структуры молекул компонентов (закодированные строками SMILES), температура и состав смеси. Модель химического языка (ChemBERTa-2) сначала преобразует каждую молекулу в числовой отпечаток. Эти отпечатки поступают в специализированную архитектуру сети, построенную так, чтобы удовлетворять ключевым требованиям согласованности: она уважает соотношение Гиббса–Дюгема, ведёт себя корректно при уходе одного компонента в чистое состояние или при бесконечном разведении, и даёт одинаковый ответ независимо от порядка компонентов. Из этих ограничений HANNA предсказывает избыток энергии Гиббса для каждой бинарной пары в смеси, а затем с помощью геометрической проекции расширяет эти предсказания на смеси с множеством компонентов, не вводя дополнительных подгоняемых параметров.
Обучение на реальных данных, а не только на уравнениях
Чтобы HANNA была широко полезна, авторы обучали её на исключительно большой и разнообразной экспериментальной базе данных. Она включает паро–жидкостные данные с полными фазовыми составами, паро–жидкостные данные только с общими давлениями, разделения на жидкостно–жидкостные фазы, коэффициенты активности при бесконечном разведении и избытки энтальпий — более 800 000 точек данных и свыше 4 000 различных соединений, включая ионные жидкости и другие сложные виды. Ключевой инновацией является суррогатный решатель, имитирующий надёжный термодинамический алгоритм для обнаружения и локализации разделений жидкостей. Этот суррогат дифференцируем, поэтому HANNA можно обучать «end-to-end» на измеренных фазовых составах без медленных итерационных расчётов внутри цикла обучения. Дополнительные члены функции потерь стимулируют HANNA распознавать кривизну, связанную с фазовым разделением, и выдавать гладкие предсказания, которые разумно ведут себя даже за пределами диапазона обучения.
Как новая модель показывает себя на практике
После обучения HANNA тестировали только на системах, отложенных во время обучения, и сравнивали её результаты с ведущими классическими и ML-моделями. Для бинарных смесей она последовательно предсказывала коэффициенты активности, фазовые составы и избытки энтальпий точнее, чем широко используемый модифицированный UNIFAC (Dortmund), и при этом надёжнее выявляла зоны несмешиваемости. Для третичных и даже четверичных смесей, которых она никогда не видела при обучении, HANNA оставалась конкурентоспособной или превосходила альтернативы, несмотря на опору исключительно на бинарные данные и геометрическую проекцию. Она также превзошла несколько недавних графовых нейросетей, которые либо не обеспечивали строгой термодинамической согласованности, либо были ограничены особыми условиями, например комнатной температурой или бесконечным разведением.
Что это значит для науки и промышленности
Для неспециалиста главный вывод таков: HANNA работает как глубоко информированное, физически обоснованное «оракул» по жидким смесям.Имея только химические формулы, она может предсказать, смешаются ли две или более жидкостей, разделятся ли они на слои или проявят сложное фазовое поведение, и делает это в широком диапазоне температур. Важно, что модель делает это, соблюдая фундаментальные термодинамические законы, что снижает риск неабсолютно физических результатов, свойственных несвязным моделям машинного обучения. Поскольку полная модель и код опубликованы открыто и доступны через веб‑интерфейс, инженеры могут сразу применять HANNA в моделировании процессов и отборе растворителей. Авторы отмечают оставшиеся ограничения — например, непроверенную работу далеко за пределами температурного диапазона обучения и с сильными электролитами — но работа знаменует важный шаг к основанному на данных, термодинамически согласованному проектированию химических процессов.
Цитирование: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Ключевые слова: жидкие смеси, термодинамика, машинное обучение, избыток энергии Гиббса, фазовые равновесия