Clear Sky Science · he
מודל למידת מכונה העקבי תרמודינמית עבור אנרגיית גיבס העודפת
מדוע זה חשוב לכימיה של היומיום
החיים המודרניים נשענים על תערובות נוזלים — מדלקים ומקררים ועד לתרופות וממסים ירוקים. תכנון תערובות אלה בצורה בטוחה ויעילה תלוי בהבנה של האינטראקציות בין המולקולות. אולם מדידת האינטראקציות לכל שילוב אפשרי היא בלתי אפשרית מבחינה מעשית. מאמר זה מציג כלי למידת מכונה חדש, בשם HANNA, שלומד את התנהגות התערובות הנוזליות ישירות מהנתונים ובה בעת מציית לחוקי היסוד של התרמודינמיקה. הכלי מבטיח חיזויים מהירים, רחבים ומהימנים יותר להנחיית תכנון תהליכים כימיים וגילוי חומרים.
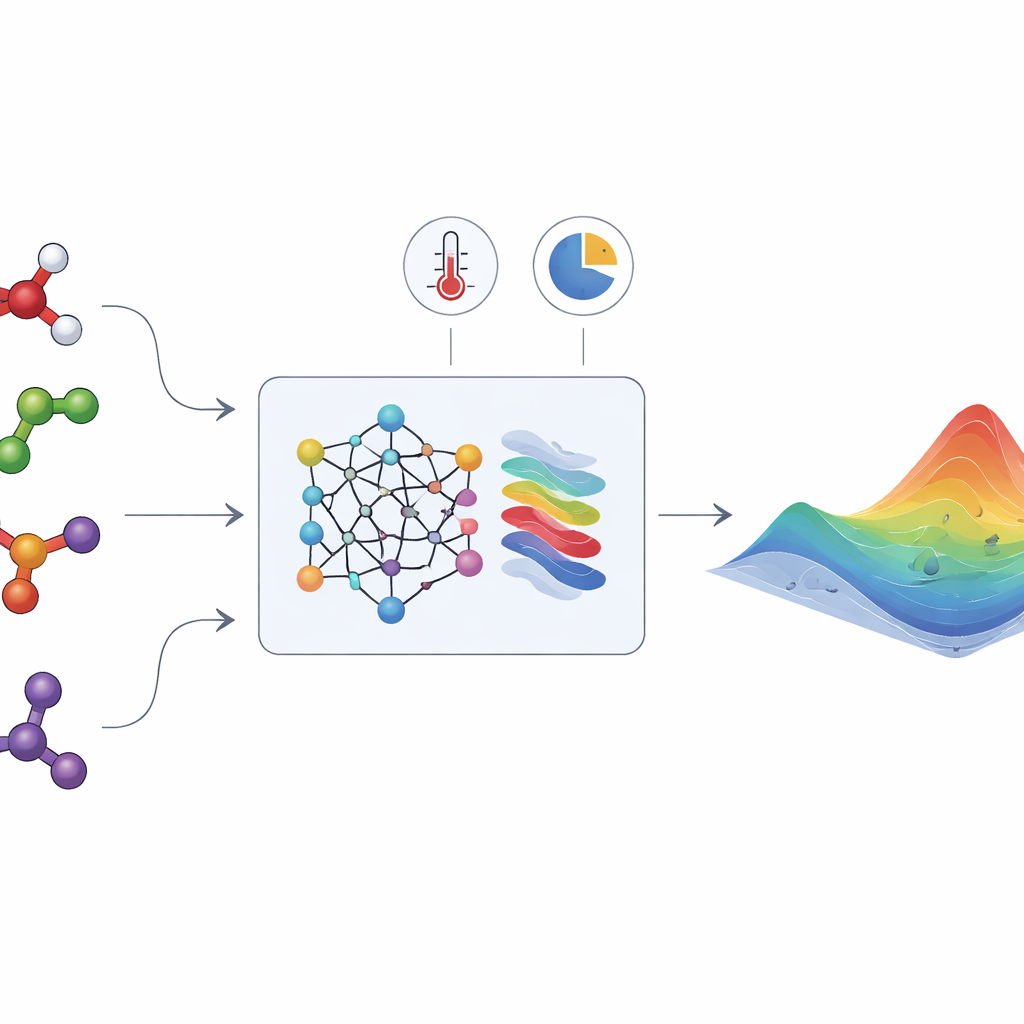
האנרגיה הסמויה שעוצבת תערובות נוזליות
כאשר מפזרים נוזלים שונים, המולקולות שלהן נמשכות או דוחקות זו מזו בדרכים שעלולות להיות עדינות למדי. ההשפעות האלה מתוארות בכמות שנקראת «אנרגיית גיבס עודפת», שמציגה עד כמה התערובת סוטה מהתנהגות אידיאלית. מפונקציה בודדת זו יכולים מהנדסים לגזור תכונות מפתח כמו מקדמי פעילות, שמכתיבים האם תערובת יוצרת פאזה נוזלית אחת או מתפלגת לשתיים, האם קיום קווין בין ואקום לנוזל יתכן, וכיצד מרכיבים מתחלקים ביניהן. לצערנו, אנרגיית הגיבס העודפת אינה ניתנת למדידה ישירה. יש לאסוף אותה מתוך ניסויים מפרכים על שוויוני קיטור–נוזל ושוויוני נוזל–נוזל או מתוך השפעות חום, ורק חלק קטן מכלל התערובות הרלוונטיות נחקר אי פעם.
מגבלות הכלים החזויים המסורתיים
במשך עשרות שנים הסתמכו מהנדסים על מודלים כמו NRTL, UNIQUAC ומשפחת UNIFAC לשם הערכת התנהגות תערובות. שיטות אלה מקורבות אינטראקציות באמצעות פרמטרים המותאמים לנתונים ניסיוניים, לעתים באופן בזוגות בינאריים. למרות כוחן, קיימות להן מגבלות חשובות: כדי לחזות תערובת חדשה יש בדרך כלל צורך בפרמטרים לכל תת-מערכת בינארית שמופיעה בה, ופרמטרים אלה עשויים לא להיות זמינים עבור תרכובות חדשניות. גם גישות המבוססות על קבוצות כמו UNIFAC, המפרקות מולקולות לחסימות בנייה, מוגבלות לקטלוג קבוצות קבוע ויכולות להתקשות בסוגים מורכבים כגון נוזלים יוניים. יתר על כן, מודלים קלאסיים רבים מתקשים לתאר במדויק גם שוויוני קיטור–נוזל וגם שוויוני נוזל–נוזל בעזרת אותו סט פרמטרים.
רשת עצבית השומרת על חוקים פיזיקליים
HANNA מתמודדת עם אתגרים אלה על ידי שילוב של רשתות עצביות מודרניות עם חוקים תרמודינמיים מוטבעים בחומרה (hard-wired). כתשומה, היא צריכה רק את המבנים המולקולריים של המרכיבים (מקודדים כמחרוזות SMILES), את הטמפרטורה ואת הרכב התערובת. מודל לשון כימית (ChemBERTa-2) ממיר תחילה כל מולקולה לטביעת אצבע מספרית. טביעות אלו מוזנות לארכיטקטורת רשת מיוחדת שנבנתה כדי לקיים דרישות עקביות חשובות: היא מכבדת את יחס Gibbs–Duhem, מתנהגת נכון כאשר מרכיב הופך לטהור או לדילול אינסופי, ומחזירה את אותה תשובה ללא תלות בסדר המרכיבים. מהגבלות אלה חוזה HANNA את אנרגיית הגיבס העודפת לכל זוג בינארי בתערובת ואז משתמשת בסכמת השלכה גאומטרית כדי להרחיב את החיזויים לתערובות עם מרכיבים רבים, ללא הצגת פרמטרי התאמה נוספים.
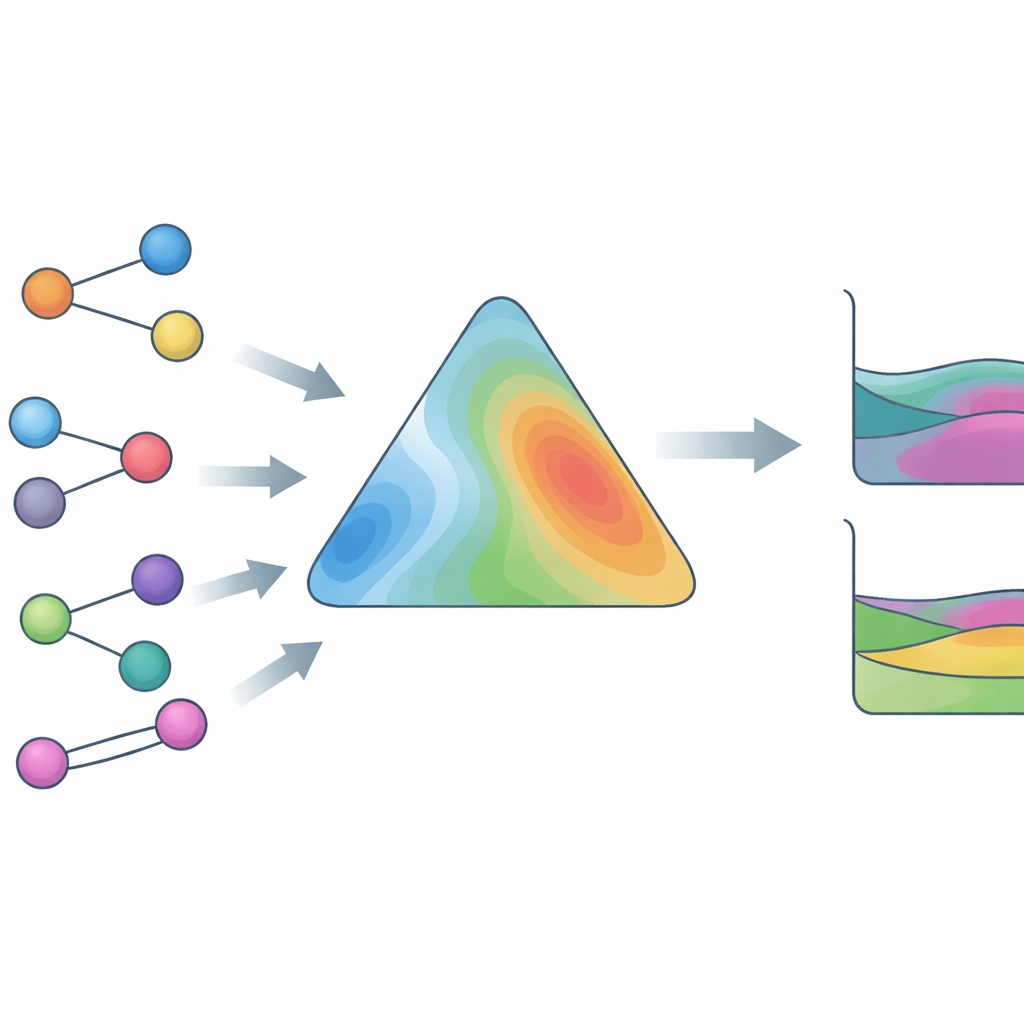
אימון על נתונים אמיתיים, לא רק על משוואות
כדי ש-HANNA תהיה שימושית בהיקף רחב, החוקרים אימנו אותה על מסד נתונים ניסיוני יוצא דופן בגודלו ובגיוון שלו. זה כולל נתוני קיטור–נוזל עם הרכבי פאזה מלאים, נתוני קיטור–נוזל עם לחצי כוללים בלבד, התפלגויות פאזה נוזל–נוזל, מקדמי פעילות בדילול אינסופי ואנתלפיות עודפות, הכול על יותר מ‑800,000 נקודות נתונים ולמעלה מ‑4,000 תרכובות מובחנות, כולל נוזלים יוניים וסוגים מאתגרים נוספים. חידוש מרכזי הוא פותר-תחליף (surrogate solver) החיקוי אלגוריתם תרמודינמי איתן לאיתור ומיקום התפלגויות נוזל–נוזל. פותר זה ניתן לדריכות, כך ש-HANNA ניתנת לאימון «מקצה-לקצה» מול הרכבי פאזה מדודים ללא צורך בחישובים איטרטיביים איטיים בתוך הלולאת הלמידה. מונחי אובדן נוספים מעודדים את HANNA לזהות את העקמומיות הקשורה לפירוד פאזה ולייצר חיזויים חלקים שמתנהגים באופן סביר גם מעבר לתחום האימון.
כיצד המודל החדש מתמודד
לאחר האימון, HANNA נבדקה אך ורק על מערכות שהוסתרו במהלך האימון, וביצועיה הושוו מול מודלים קלאסיים ומודלי למידת מכונה מובילים. עבור תערובות בינאריות היא חזה בעקביות את מקדמי הפעילות, הרכבי הפאזה והאנתלפיות העודפות בדיוק רב יותר מהשיטה המורכבת UNIFAC (Dortmund) הנפוצה, ובאותו זמן זיהתה מרווחי תמוססות נוזלי–נוזל באופן אמין יותר. עבור תערובות תי-אריות ואף ארבע-רכיביות, שלא נחשפו לה במהלך האימון, HANNA נותרה תחרותית או עליונה, למרות שהיא מסתמכת אך ורק על נתונים בינאריים בתוספת ההשלכה הגאומטרית. היא גם עלתה על מספר רשתות עצביות גרפיות שפותחו לאחרונה, אשר חסרו עקביות תרמודינמית קפדנית או הוגבלו לתנאים מיוחדים כגון טמפרטורת חדר או דילול אינסופי.
מה זה אומר למדע ולתעשייה
ללא־מומחה, המסר המרכזי הוא ש-HANNA מתפקדת כמו «אורקל» בעל ידע רב ומושתת על עקרונות פיזיקליים לתחום תערובות נוזלים. בהינתן רק את הנוסחאות הכימיות, היא יכולה לחזות האם שני נוזלים או יותר יימסו זה בזה, יתפלגו לשכבות או ייצרו התנהגות פאזה מורכבת — והיא עושה זאת בטווח רחב של טמפרטורות. בעקרון חשוב, היא עושה זאת תוך שמירה על כללי התרמודינמיקה הבסיסיים, מה שמפחית את הסיכון לתוצאות לא-פיזיקליות שיכולות להופיע במודלי למידת מכונה לא-מובנים. מכיוון שהמודל והקוד המלאים משוחררים באופן פתוח ונגישים דרך ממשק אינטרנטי, מהנדסים יכולים להתחיל להשתמש ב-HANNA ישירות בסימולציית תהליכים ובסינון ממסים. בעוד המחברים מציינים מגבלות שנותרו — כגון ביצועים לא נבדקו רחוק מעבר לטווח טמפרטורות האימון ובמקרים של אלקטרוליטים חזקים — העבודה מסמנת צעד משמעותי לעבר תכנון מבוסס-נתונים ועקבי תרמודינמית של תהליכים כימיים.
ציטוט: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
מילות מפתח: תמיסות נוזליות, תרמודינמיקה, למידת מכונה, אנרגיית גיבס עודפת, שוויוני פאזה