Clear Sky Science · pt
Modelo de aprendizado de máquina termodinamicamente consistente para energia livre de Gibbs excessiva
Por que isso importa para a química cotidiana
A vida moderna depende de misturas de líquidos, desde combustíveis e refrigerantes até produtos farmacêuticos e solventes verdes. Projetar essas misturas com segurança e eficiência depende de conhecer como suas moléculas interagem. Ainda assim, medir essas interações para todas as combinações possíveis é impossível. Este artigo apresenta uma nova ferramenta de aprendizado de máquina, chamada HANNA, que aprende o comportamento de misturas líquidas diretamente a partir de dados enquanto respeita as leis básicas da termodinâmica. Ela promete previsões mais rápidas, abrangentes e confiáveis para orientar o projeto de processos químicos e a descoberta de materiais.
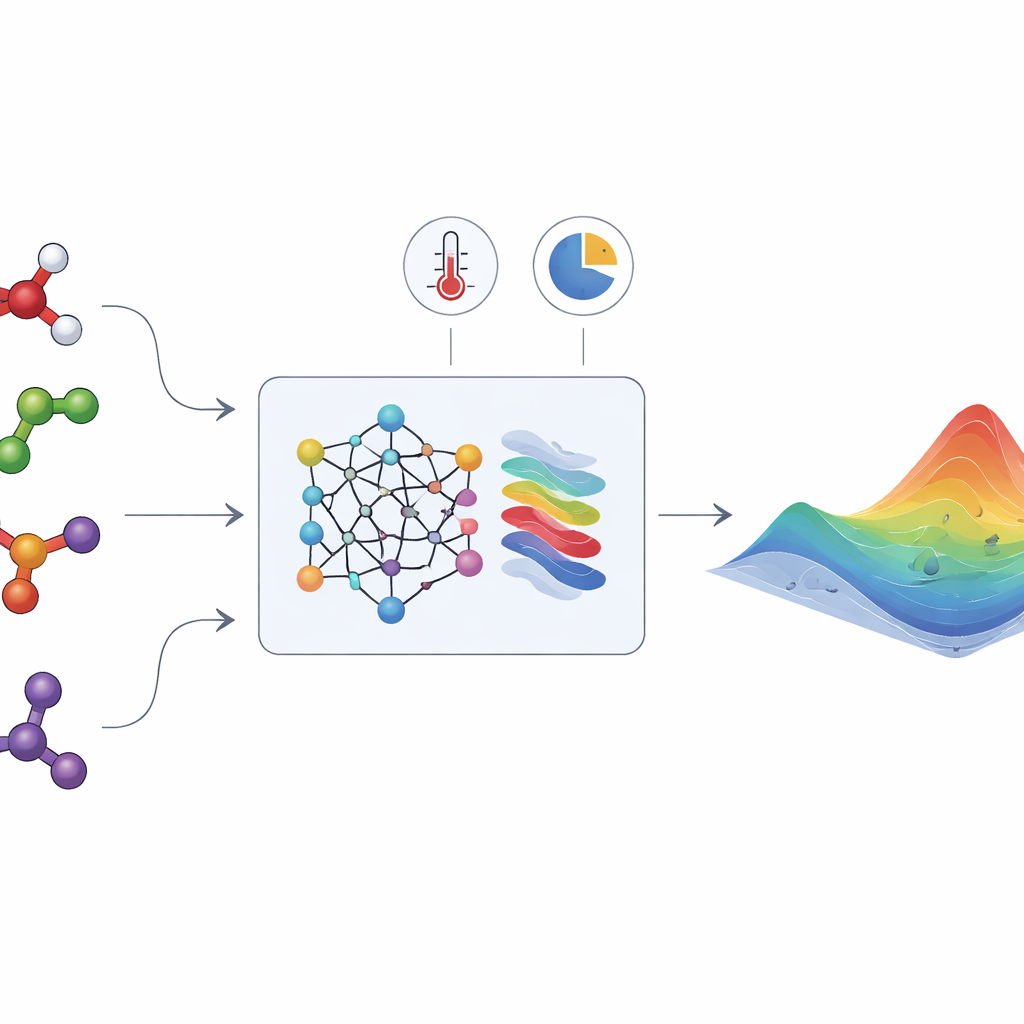
A energia oculta que molda as misturas líquidas
Quando diferentes líquidos são misturados, suas moléculas se atraem ou se repelem de maneiras que podem ser bastante sutis. Esses efeitos são capturados em uma grandeza chamada “energia livre de Gibbs excessiva”, que indica quanto a mistura se afasta do comportamento ideal. A partir dessa única função, engenheiros podem derivar propriedades-chave, como os coeficientes de atividade, que por sua vez determinam se uma mistura forma uma única fase líquida ou se separa em duas, se vapor e líquido coexistem e como os componentes se distribuem entre elas. Infelizmente, a energia livre de Gibbs excessiva não pode ser medida diretamente. Ela precisa ser inferida a partir de experimentos minuciosos sobre equilíbrios vapor–líquido e líquido–líquido ou efeitos térmicos, e apenas uma pequena fração de todas as misturas relevantes já foi estudada.
Limites das ferramentas de previsão tradicionais
Por décadas, engenheiros confiaram em modelos como NRTL, UNIQUAC e a família UNIFAC para estimar o comportamento de misturas. Esses métodos aproximam as interações por meio de parâmetros ajustados a dados experimentais, frequentemente em base par a par. Embora poderosos, têm limitações importantes: para prever uma nova mistura, normalmente é necessário ter parâmetros para cada subsistema binário que nela aparece, e esses podem não existir para compostos inéditos. Mesmo abordagens baseadas em grupos, como o UNIFAC, que decompõem moléculas em blocos construtivos, ficam confinadas a um catálogo fixo de grupos e podem ter dificuldades com espécies complexas, como líquidos iônicos. Além disso, muitos modelos clássicos acham difícil descrever com precisão equilíbrios vapor–líquido e líquido–líquido ao mesmo tempo usando um único conjunto de parâmetros.
Uma rede neural que obedece às leis físicas
HANNA enfrenta esses desafios combinando redes neurais modernas com regras termodinâmicas embutidas. Como entrada, ela precisa apenas das estruturas moleculares dos componentes (codificadas como strings SMILES), da temperatura e da composição da mistura. Um modelo de linguagem química (ChemBERTa-2) primeiro converte cada molécula em uma impressão digital numérica. Essas impressões alimentam uma arquitetura de rede especializada que foi construída para obedecer a requisitos de consistência chave: respeita a relação de Gibbs–Duhem, comporta-se corretamente quando um componente se torna puro ou infinitamente diluído e dá a mesma resposta independentemente da ordem dos componentes. A partir dessas restrições, HANNA prevê a energia livre de Gibbs excessiva para cada par binário em uma mistura e então usa um esquema de projeção geométrica para estender essas previsões a misturas com muitos componentes, sem introduzir parâmetros adicionais de ajuste.
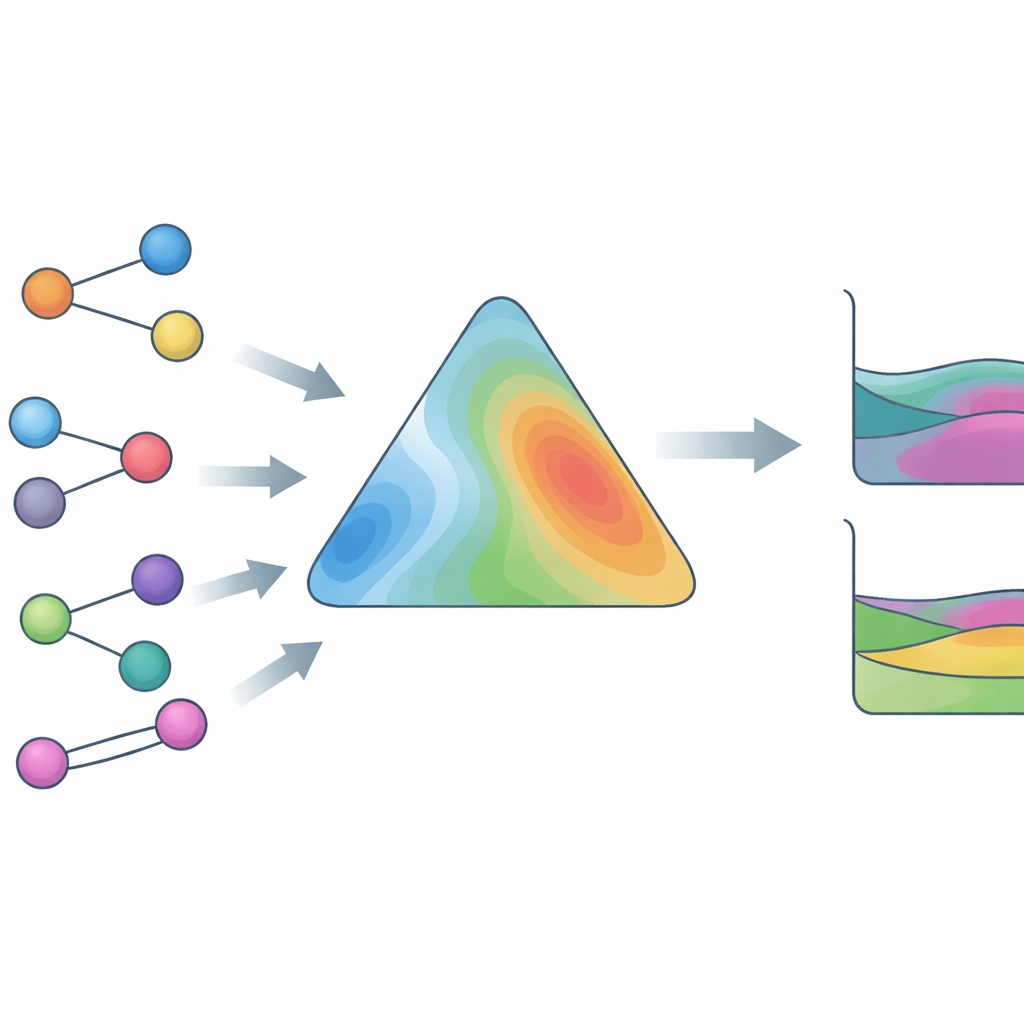
Treinamento com dados reais, não apenas equações
Para tornar HANNA amplamente útil, os autores a treinaram em um banco de dados experimental excepcionalmente grande e diverso. Isso inclui dados vapor–líquido com composições de fase completas, dados vapor–líquido com apenas pressões totais, separações de fases líquido–líquido, coeficientes de atividade em diluição infinita e entalpias excessivas, cobrindo mais de 800.000 pontos de dados e mais de 4.000 compostos distintos, incluindo líquidos iônicos e outras espécies desafiadoras. Uma inovação-chave é um solucionador substituto que emula um algoritmo termodinâmico robusto para detectar e localizar separações líquido–líquido. Esse substituto é diferenciável, de modo que HANNA pode ser treinada “end-to-end” contra composições de fase medidas sem recorrer a cálculos iterativos lentos dentro do ciclo de aprendizado. Termos de perda adicionais incentivam HANNA a reconhecer a curvatura associada à separação de fases e a produzir previsões suaves que se comportam de forma sensata mesmo além da faixa de treinamento.
Como o novo modelo se sai
Uma vez treinada, HANNA foi testada apenas em sistemas que haviam sido retidos durante o treinamento, e seu desempenho foi comparado com modelos clássicos e de aprendizado de máquina líderes. Para misturas binárias, previu consistentemente coeficientes de atividade, composições de fase e entalpias excessivas com mais precisão do que o método UNIFAC modificado amplamente usado (Dortmund), além de identificar lacunas de miscibilidade líquido–líquido com maior confiabilidade. Para misturas ternárias e até quaternárias, que nunca tinha visto durante o treinamento, HANNA se manteve competitiva ou superior, apesar de confiar unicamente em dados binários mais a projeção geométrica. Também superou várias redes neurais recentes baseadas em grafos que ou não tinham consistência termodinâmica estrita ou estavam limitadas a condições especiais, como temperatura ambiente ou diluição infinita.
O que isso significa para a ciência e a indústria
Para um não especialista, a mensagem central é que HANNA funciona como um “oráculo” altamente informado e fundamentado fisicamente para misturas líquidas. Dadas apenas as fórmulas químicas, ela pode prever se dois ou mais líquidos irão se misturar, separar em camadas ou formar comportamento de fase complexo, e faz isso em uma ampla faixa de temperaturas. Crucialmente, faz isso respeitando as regras termodinâmicas subjacentes, reduzindo o risco de resultados não físicos que podem afetar modelos de aprendizado de máquina sem restrições. Como o modelo completo e o código são disponibilizados abertamente e são acessíveis por meio de uma interface web, engenheiros podem começar a usar HANNA diretamente em simulação de processos e triagem de solventes. Embora os autores apontem limitações remanescentes — como desempenho não testado muito além da faixa de temperatura de treinamento e para eletrólitos fortes — o trabalho marca um grande avanço rumo ao projeto orientado por dados e termodinamicamente consistente de processos químicos.
Citação: Hoffmann, M., Specht, T., Göttl, Q. et al. Thermodynamically consistent machine learning model for excess Gibbs energy. Nat Commun 17, 3485 (2026). https://doi.org/10.1038/s41467-026-71430-y
Palavras-chave: misturas líquidas, termodinâmica, aprendizado de máquina, energia livre de Gibbs excessiva, equilíbrios de fases