Clear Sky Science · sv
Effektiv kartläggning av djupinlärningsapplikationer till mixed‑precision‑hårdvara med supernätverk och modellanpassning
Varför smartare AI‑chip spelar roll
Modern artificiell intelligens driver allt från röstassistenter till medicinsk bildanalys, men de datorer som kör dessa system pressas hårt. När modeller växer kräver de mer energi, minne och tid för att göra prediktioner. Denna artikel utforskar ett nytt sätt att matcha AI‑mjukvara med specialiserad hårdvara så att systemen kan köras snabbare och med lägre energiförbrukning samtidigt som noggrannheten behålls. Fokus ligger på att kombinera två typer av beräkning — analog och digital — och på att automatiskt avgöra vilka delar av ett neuralt nätverk som bör använda vilken typ.
Två slags hjärnor i en maskin
Dagens AI‑chip börjar blanda traditionella digitala enheter med analoga ”in‑memory”‑motorer som kan utföra stora matematiska block inne i själva minnet. Analoga enheter är extremt snabba och energieffektiva, men också brusiga och mindre precisa. Digitala enheter är däremot långsammare och mindre effektiva men mycket tillförlitliga. En central utmaning är att bestämma, lager för lager, var ett neuralt nätverk ska köras i analog form och var det ska förbli digitalt så att hela systemet fungerar väl. Om för många lager körs analogt minskar noggrannheten; om för många förblir digitala försvinner i stor utsträckning energivinsterna och hastighetsförbättringarna.
Karta över många möjliga nätverk
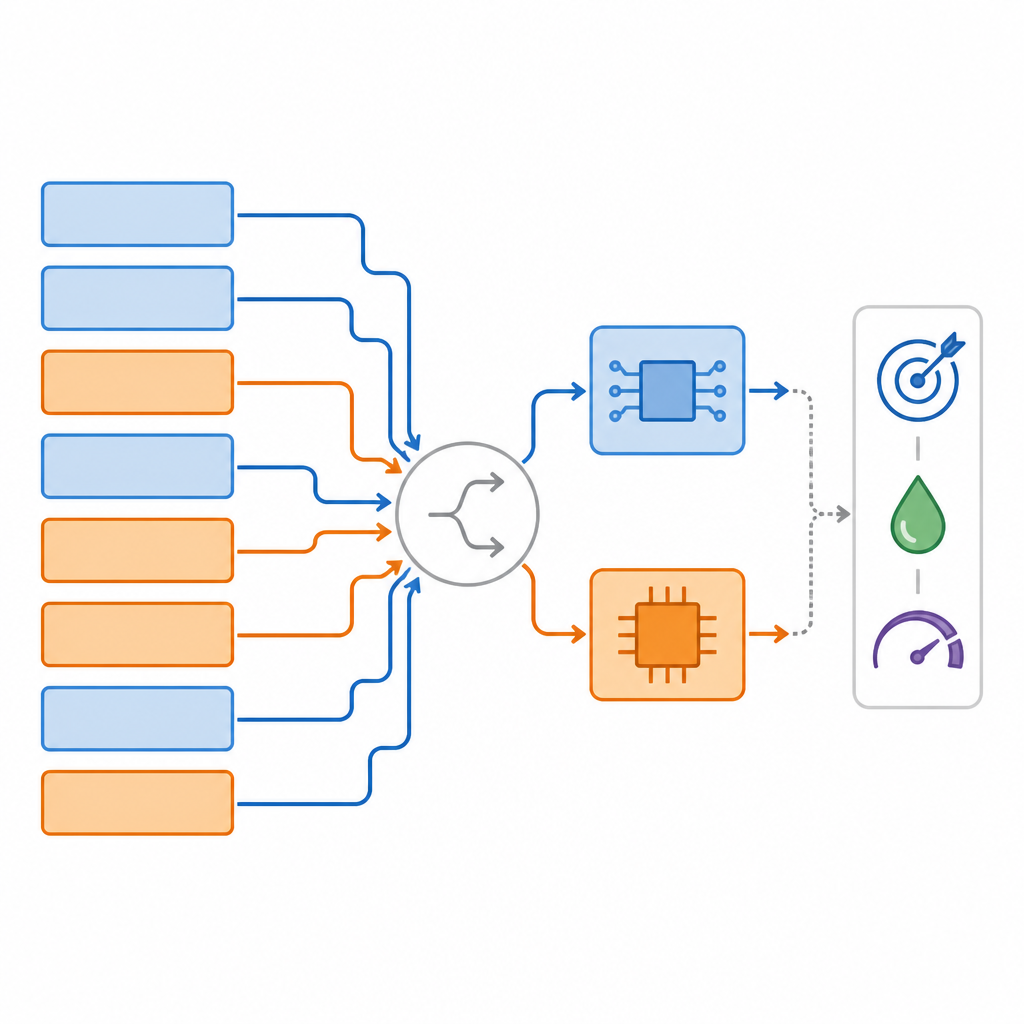
Författarna presenterar Mixed‑Precision Supernetwork, en stor övertäckande modell som innehåller många möjliga versioner av samma neurala nätverk samtidigt. För varje lager inkluderar detta supernätverk flera alternativ: en digital version i olika bit‑precisioner, en analog version med realistiskt brus och till och med möjligheten att hoppa över eller omforma lager. Under träningen lär sig systemet inte bara de vanliga nätverksvikterna utan också hur bra varje hårdvaruval är för varje lager. En särskild rankningsmetod söker sedan igenom detta alternativutrymme för att hitta specifika lager‑för‑lager‑"kartläggningar" som balanserar tre mål samtidigt: uppgiftens noggrannhet, hur mycket arbete som utförs på analog hårdvara och hur mycket digitalt minne som krävs.
Lära modellen att passa hårdvaran
Förutom valet mellan analogt och digitalt kan ramen mjukt omforma nätverket så att det passar hårdvaran mer naturligt. Till exempel kan den vidga vissa inre lager i en transformer eller konvolutionsblock så att de fyller en analog platta mer fullständigt, genom att använda fler av de tillgängliga raderna och kolumnerna utan att lägga till fördröjning. Dessa hårdvarumedvetna anpassningar ökar antalet parametrar i vissa lager, men eftersom de placeras där analog hårdvara är effektiv förblir den totala energikostnaden låg. Systemet tränas i etapper: först behandlas alla vägar rättvist, sedan introduceras gradvis verklig kvantisering och analogt brus, och slutligen finjusteras valen för att behålla de bästa avvägningarna mellan noggrannhet och effektivitet.
Schnellare sökningar och bättre avvägningar
Teamet testade sitt tillvägagångssätt på flera standarduppgifter: bildklassificering på CIFAR‑10, objektssegmentering på COCO‑datasetet och frågesvar på SQuAD. I dessa tester hittade deras metoder, kallade MPS och den mer avancerade MPAAS, konsekvent kartläggningar som använde en hög andel analoga operationer samtidigt som de bibehöll eller till och med förbättrade noggrannheten jämfört med vanliga referenser. I genomsnitt upptäcktes deras kartläggningar ungefär 2,2 gånger snabbare än konkurrerande metoder och gav kring 3,4 procent bättre uppgiftsprestanda jämfört med en hel‑analog design. Hårdvarusimuleringar visade att de resulterande designerna kunde minska latenstiden med upp till cirka 2,4 gånger och energin per prediktion med ungefär 2,6 gånger i förhållande till digitala system med full precision.
Vad detta betyder för framtidens AI‑hårdvara
För icke‑experter är huvudbudskapet att hur en AI‑modell läggs ut på ett chip spelar nästan lika stor roll som modellen i sig. Detta arbete visar att en automatisk, hårdvarumedveten ”planerare” kan avgöra vilka delar av ett nätverk som bör köras på snabb men brusig analog hårdvara och vilka som bör förbli på precisa digitala enheter, ibland genom att omforma modellen för att passa chipet tätare. Resultatet är AI som kan leverera liknande noggrannhet samtidigt som den använder betydligt mindre energi och tid — ett viktigt steg mot att göra kraftfulla modeller praktiska i enheter som telefoner, bilar och edge‑servrar i stället för endast i stora datacenter.
Citering: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Nyckelord: mixed precision‑hårdvara, analog in‑memory‑beräkning, kartläggning av neurala nätverk, hårdvarumedveten AI, energieffektiv inferens