Clear Sky Science · it
Mappatura efficiente basata su supernetwork di applicazioni di deep learning su hardware a precisione mista usando adattamento del modello
Perché i chip AI più intelligenti sono importanti
L’intelligenza artificiale moderna alimenta tutto, dagli assistenti vocali all’analisi di immagini mediche, ma i computer che eseguono questi sistemi sono sotto forte pressione. Man mano che i modelli crescono, richiedono più energia, memoria e tempo per effettuare le predizioni. Questo articolo esplora un nuovo modo di abbinare il software AI a hardware specializzato in modo che i sistemi possano funzionare più velocemente e con meno energia mantenendo comunque l’accuratezza. Si concentra sulla combinazione di due tipi di calcolo, analogico e digitale, e sulla decisione automatica di quali parti di una rete neurale debbano usare quale tipo.
Due tipi di “cervello” per una macchina
I chip AI odierni iniziano a mescolare unità digitali tradizionali con motori analogici “in‑memory” capaci di eseguire grandi blocchi di calcolo direttamente nella memoria. Le unità analogiche sono estremamente veloci e a basso consumo energetico, ma sono anche rumorose e meno precise. Le unità digitali, al contrario, sono più lente e meno efficienti ma altamente affidabili. Una sfida chiave è decidere, livello per livello, dove una rete neurale dovrebbe essere eseguita in analogico e dove dovrebbe rimanere digitale affinché l’intero sistema funzioni bene. Se troppi livelli girano in analogico, l’accuratezza cala; se troppi restano digitali, i risparmi energetici e i guadagni di velocità scompaiono in gran parte.
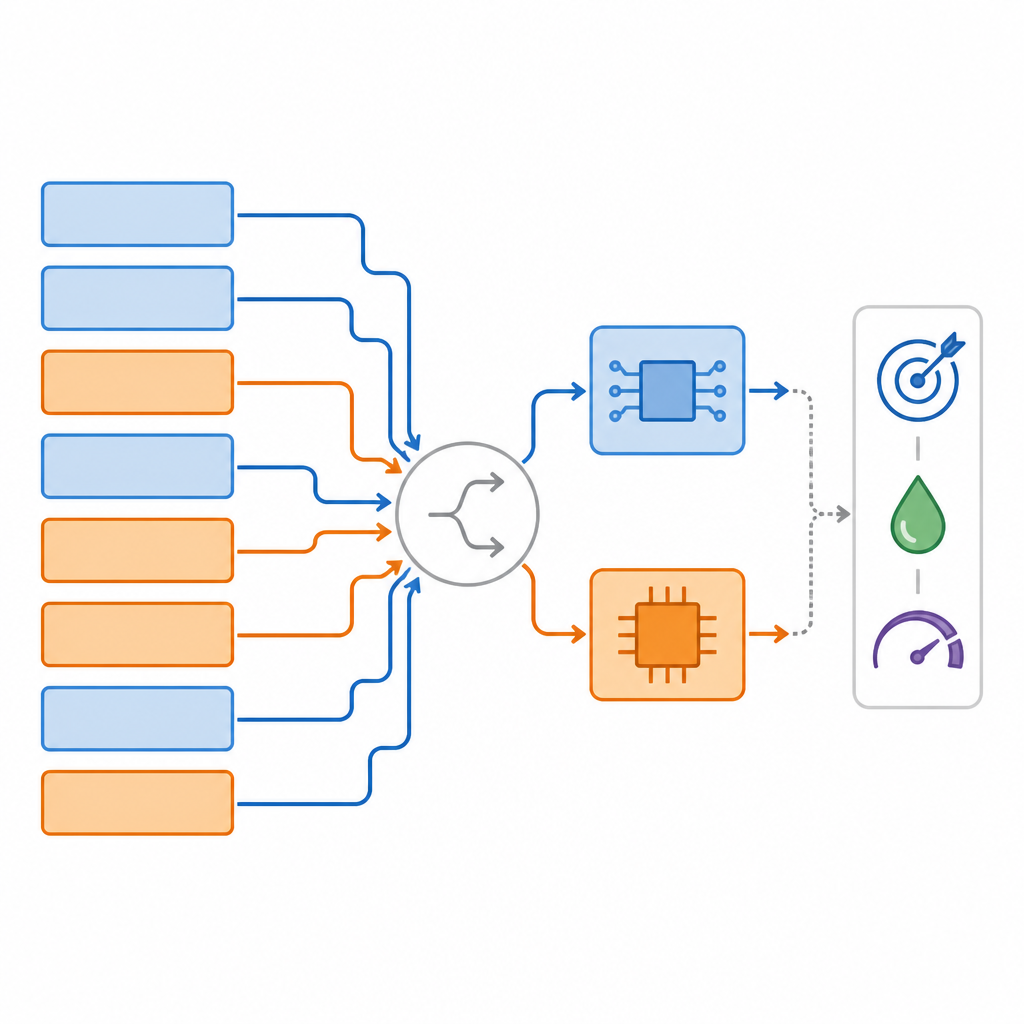
Una mappa di molte reti possibili
Gli autori introducono la Mixed‑Precision Supernetwork, un grande modello ombrello che contiene molte versioni possibili della stessa rete neurale contemporaneamente. Per ogni livello, questa supernetwork include diverse opzioni: una versione digitale a diverse precisioni di bit, una versione analogica che incorpora rumore realistico e persino la possibilità di saltare o rimodellare i livelli. Durante l’addestramento, il sistema impara non solo i pesi usuali della rete, ma anche quanto è buona ogni scelta hardware per ciascun livello. Un metodo di ranking speciale poi esplora questo spazio di opzioni per trovare “mappature” specifiche livello per livello che bilanciano tre obiettivi contemporaneamente: l’accuratezza del compito, quanto lavoro viene eseguito sull’hardware analogico e quanta memoria digitale è richiesta.
Insegnare al modello ad adattarsi all’hardware
Oltre a scegliere tra analogico e digitale, il framework può rimodellare delicatamente la rete in modo che si adatti più naturalmente all’hardware. Per esempio, può allargare certi livelli interni di un trasformatore o di un blocco convoluzionale in modo da riempire più completamente una tile analogica, usando più righe e colonne disponibili senza aggiungere latenza. Queste adattazioni consapevoli dell’hardware aumentano il numero di parametri in alcuni livelli, ma poiché sono posizionate dove l’hardware analogico è efficiente, il costo energetico complessivo resta basso. Il sistema si allena in più fasi: prima tratta tutti i percorsi in modo equo, poi introduce gradualmente la quantizzazione reale e il rumore analogico e infine affina le scelte per mantenere i migliori compromessi tra accuratezza ed efficienza.
Ricerche più veloci e compromessi migliori
Il team ha testato il proprio approccio su diversi compiti standard: classificazione di immagini su CIFAR‑10, segmentazione di oggetti sul dataset COCO e question answering su SQuAD. In questi test, i loro metodi, chiamati MPS e il più avanzato MPAAS, hanno costantemente trovato mappature che usavano una frazione elevata di operazioni analogiche mantenendo o addirittura migliorando leggermente l’accuratezza rispetto ai baseline comuni. In media, le loro mappature sono state scoperte circa 2,2 volte più velocemente rispetto ai metodi concorrenti e hanno fornito circa un aumento del 3,4 percento nelle prestazioni del compito rispetto a un design totalmente analogico. Le simulazioni hardware hanno mostrato che i progetti risultanti potevano ridurre la latenza fino a circa 2,4 volte e l’energia per predizione di circa 2,6 volte rispetto ai sistemi digitali a precisione completa.
Cosa significa per l’hardware AI futuro
Per i non esperti, il messaggio principale è che il modo in cui un modello AI viene disposto su un chip conta quasi tanto quanto il modello stesso. Questo lavoro mostra che un “pianificatore” automatico e consapevole dell’hardware può decidere quali parti di una rete debbano essere eseguite su hardware analogico veloce ma rumoroso e quali debbano restare su unità digitali precise, talvolta rimodellando il modello per adattarlo meglio al chip. Il risultato è un’IA che può offrire un’accuratezza simile usando molta meno energia e tempo, un passo importante per rendere i modelli potenti praticabili in dispositivi come telefoni, auto e server edge anziché solo nei grandi data center.
Citazione: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Parole chiave: hardware a precisione mista, calcolo analogico in memoria, mappatura di reti neurali, IA consapevole dell’hardware, inferenza energeticamente efficiente