Clear Sky Science · de
Supernetzwerk-basierte effiziente Zuordnung tief lernender Anwendungen zu Mixed‑Precision‑Hardware durch Modellanpassung
Warum klügere KI‑Chips wichtig sind
Moderne Künstliche Intelligenz treibt alles an, von Sprachassistenten bis zur medizinischen Bildanalyse, doch die Rechner, die diese Systeme ausführen, stoßen an ihre Grenzen. Mit wachsender Modellgröße steigen Energiebedarf, Speicherbedarf und Vorhersagezeiten. Diese Arbeit untersucht einen neuen Weg, KI‑Software an spezialisierte Hardware anzupassen, sodass Systeme schneller und energieärmer laufen können, ohne die Genauigkeit einzubüßen. Der Fokus liegt auf der Kombination zweier Rechenarten — analog und digital — sowie auf der automatischen Entscheidung, welche Teile eines neuronalen Netzes welche Art verwenden sollten.
Zwei Arten ‚Gehirn‘ für eine Maschine
Die heutigen KI‑Chips mischen zunehmend traditionelle digitale Einheiten mit analogen In‑Memory‑Beschleunigern, die große Rechenblöcke direkt im Speicher ausführen können. Analoge Einheiten sind äußerst schnell und energieeffizient, bringen jedoch Rauschen und geringere Präzision mit sich. Digitale Einheiten sind dagegen langsamer und weniger effizient, aber sehr zuverlässig. Eine zentrale Herausforderung besteht darin, schichtweise zu entscheiden, welche Teile eines neuronalen Netzes analog und welche digital laufen sollen, damit das Gesamtsystem gut funktioniert. Laufen zu viele Schichten analog, leidet die Genauigkeit; bleiben zu viele digital, gehen Energie‑ und Geschwindigkeitsvorteile weitgehend verloren.
Eine Karte vieler möglicher Netze
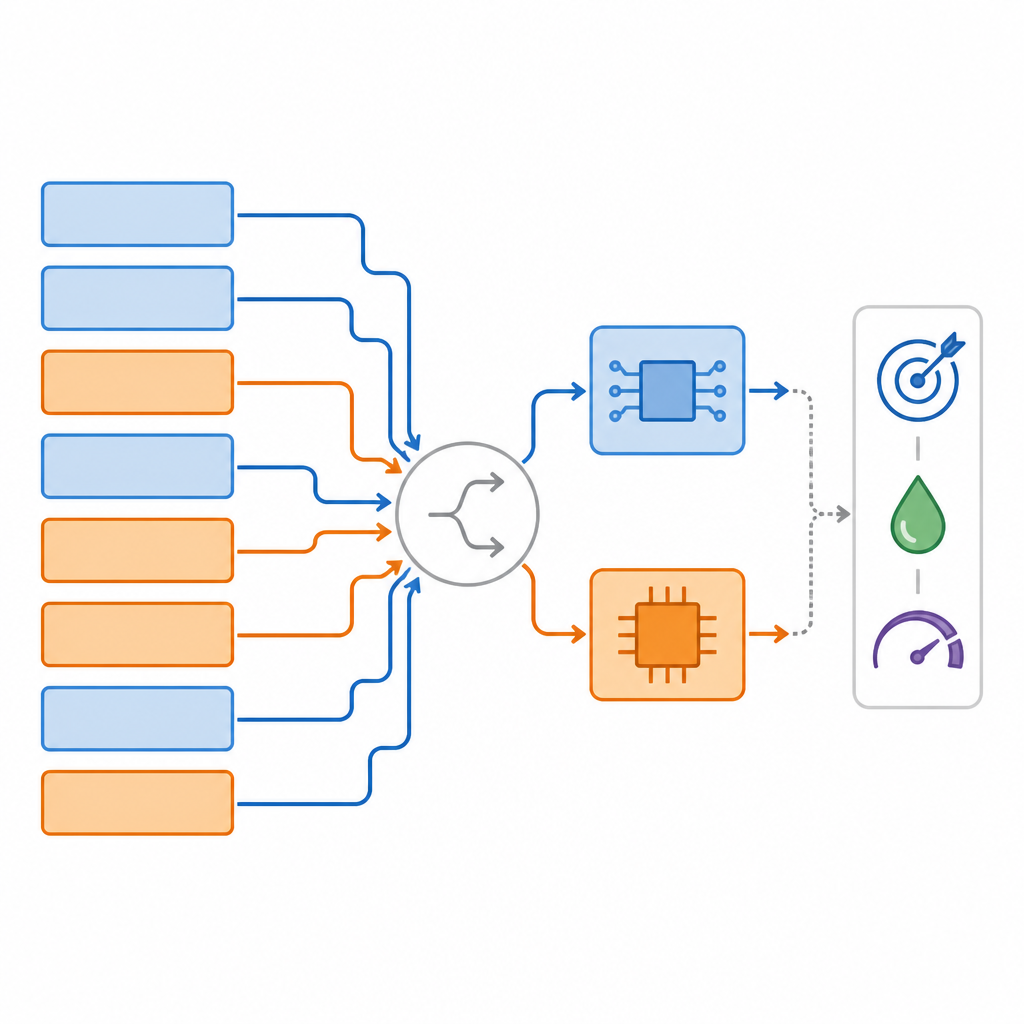
Die Autorinnen und Autoren führen das Mixed‑Precision‑Supernetzwerk ein, ein großes Modell, das gleichzeitig viele mögliche Versionen desselben neuronalen Netzes enthält. Für jede Schicht umfasst dieses Supernetz mehrere Optionen: eine digitale Variante mit unterschiedlicher Bit‑Präzision, eine analoge Variante mit realistischem Rauschen und sogar die Möglichkeit, Schichten zu überspringen oder umzustrukturieren. Während des Trainings lernt das System nicht nur die üblichen Gewichtungen, sondern auch, wie gut jede Hardware‑Option für jede Schicht ist. Eine spezielle Ranking‑Methode durchsucht dann diesen Optionsraum, um schichtweise Zuordnungen zu finden, die drei Ziele gleichzeitig ausbalancieren: Aufgaben‑Genauigkeit, der Anteil der Arbeit auf analoger Hardware und der benötigte digitale Speicher.
Das Modell an die Hardware anpassen
Über die Wahl zwischen analog und digital hinaus kann das Framework das Netz behutsam umformen, damit es besser zur Hardware passt. Es kann zum Beispiel bestimmte innere Schichten eines Transformers oder Faltungsblocks verbreitern, sodass sie eine analoge Tile vollständiger ausfüllen, mehr der verfügbaren Reihen und Spalten nutzen, ohne zusätzliche Latenz einzuführen. Diese hardware‑bewussten Anpassungen erhöhen die Anzahl der Parameter in einigen Schichten, doch da sie dort vorgenommen werden, wo die analoge Hardware effizient ist, bleibt die Gesamtenergiekosten niedrig. Das System trainiert in Phasen: Zuerst behandelt es alle Pfade gleichberechtigt, dann führt es schrittweise echte Quantisierung und analoges Rauschen ein und finalisiert die Feinabstimmung, um die besten Genauigkeits‑Effizienz‑Kompromisse zu erhalten.
Schnellere Suche und bessere Kompromisse
Das Team testete seinen Ansatz an mehreren Standardaufgaben: Bildklassifikation auf CIFAR‑10, Objeksegmentierung im COCO‑Datensatz und Fragebeantwortung auf SQuAD. In diesen Tests fanden ihre Methoden, genannt MPS und das fortgeschrittenere MPAAS, konsistent Zuordnungen, die einen hohen Anteil analoger Operationen nutzten und dabei die Genauigkeit im Vergleich zu gängigen Baselines hielten oder sogar leicht verbesserten. Im Mittel wurden die Zuordnungen etwa 2,2‑mal schneller gefunden als bei konkurrierenden Methoden, und die Aufgabenleistung stieg um rund 3,4 Prozent gegenüber einem reinen Analog‑Design. Hardware‑Simulationen zeigten, dass die resultierenden Designs die Latenz um bis zu etwa 2,4‑mal und die Energie pro Vorhersage um etwa 2,6‑mal gegenüber vollpräzisen digitalen Systemen senken konnten.
Was das für künftige KI‑Hardware bedeutet
Für Nicht‑Expertinnen und Nicht‑Experten lautet die Kernbotschaft: Die Art und Weise, wie ein KI‑Modell auf einem Chip angeordnet ist, ist fast genauso wichtig wie das Modell selbst. Diese Arbeit zeigt, dass ein automatischer, hardware‑bewusster „Planer“ entscheiden kann, welche Teile eines Netzes auf schneller, aber verrauschter analoger Hardware laufen und welche auf präzisen digitalen Einheiten verbleiben sollten — und das Modell dabei gelegentlich so umgestalten kann, dass es besser auf den Chip passt. Das Ergebnis ist KI, die ähnliche Genauigkeit liefert, dabei aber deutlich weniger Energie und Zeit benötigt — ein wichtiger Schritt, damit leistungsfähige Modelle in Geräten wie Handys, Autos und Edge‑Servern praktikabel werden und nicht nur in großen Rechenzentren.
Zitation: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Schlüsselwörter: Mixed‑Precision‑Hardware, analoge In‑Memory‑Rechnung, Abbildung neuronaler Netze, hardware‑bewusste KI, energieeffiziente Inferenz