Clear Sky Science · ja
モデル適応を用いた混合精度ハードウェアへの深層学習アプリケーションの効率的なマッピング(スーパーネットワークベース)
なぜ賢いAIチップが重要か
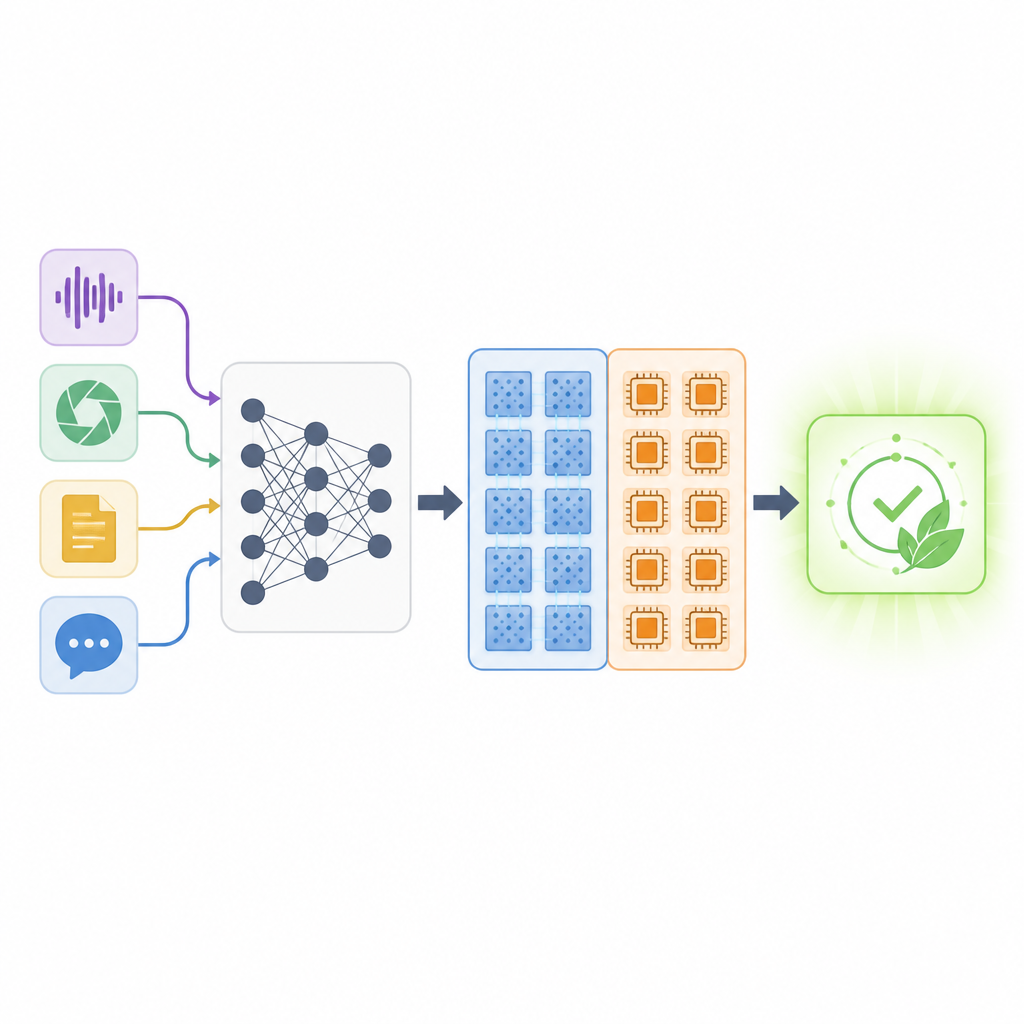
現代の人工知能は音声アシスタントから医用画像解析まで幅広く活用されていますが、これらを動かす計算機は負荷に耐え切れなくなりつつあります。モデルが大規模化するほど、予測に必要なエネルギー、メモリ、時間が増大します。本稿は、AIソフトウェアを専用ハードウェアにうまく対応させる新しい手法を探り、システムがより速く、より少ないエネルギーで動作しつつ精度を維持できるようにすることを目的としています。焦点はアナログとデジタルという二種類の計算を組み合わせることと、ネットワークのどの部分をどちらで実行するかを自動的に決定する点にあります。
一台の機械に二つの「脳」
現在のAIチップは、従来のデジタル演算ユニットと、メモリ内部で大規模な演算を行えるアナログの「インメモリ」エンジンを併用し始めています。アナログユニットは非常に高速かつ省エネルギーですが、ノイズが多く精度は劣ります。一方、デジタルユニットは遅く効率は劣るものの信頼性が高いという特性があります。重要な課題は、層ごとにネットワークをアナログで動かすかデジタルで残すかを決め、全体として性能を保つことです。あまりに多くの層をアナログで動かすと精度が低下しますし、逆に多くをデジタルのままにすると省エネや速度向上の利点は失われます。
多様なネットワークの地図
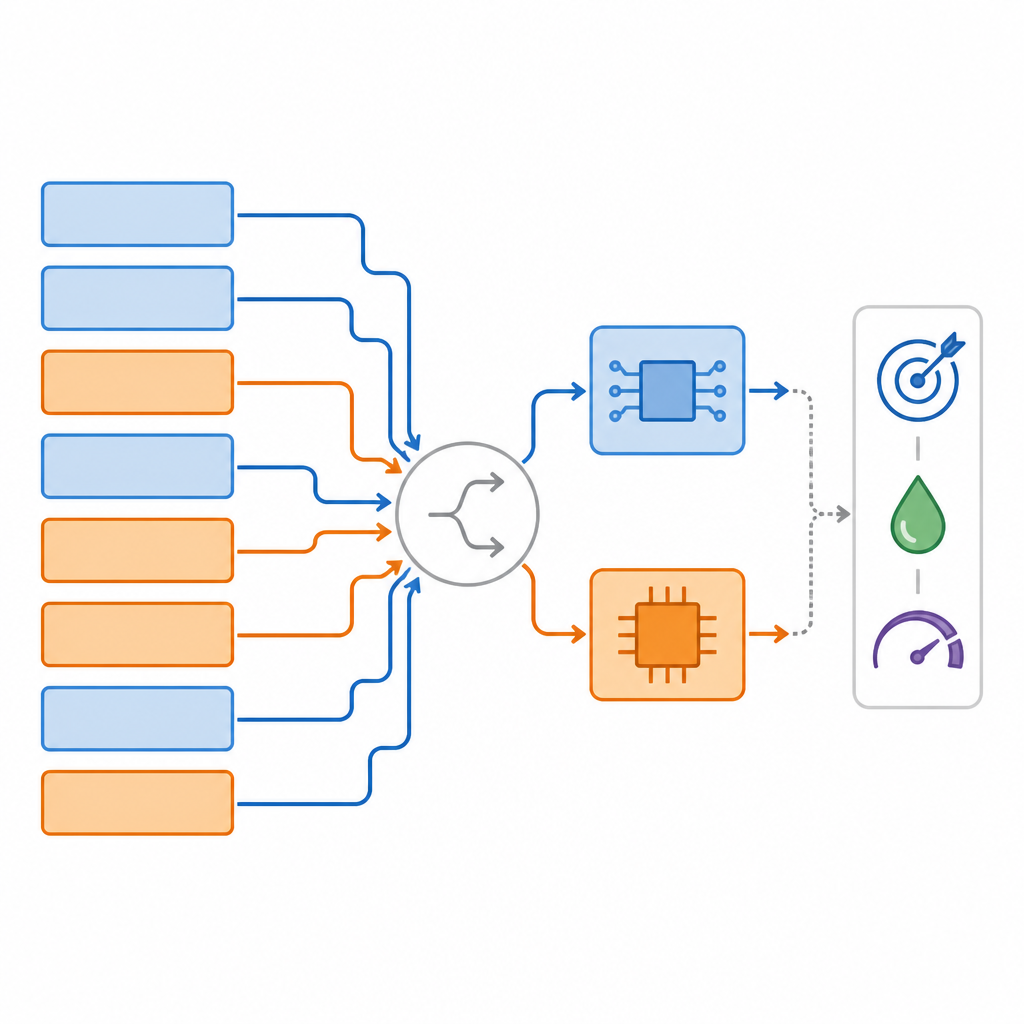
著者らはMixed‑Precision Supernetwork(混合精度スーパーネットワーク)を導入します。これは同一のニューラルネットワークの多くのバージョンを同時に包含する大規模な傘モデルです。各層について、このスーパーネットワークは複数の選択肢を持ちます:異なるビット精度のデジタル版、現実的なノイズを含むアナログ版、さらには層をスキップしたり形状を変えたりする可能性まで。訓練中、システムは単に重みだけでなく各層における各ハードウェア選択の良さも学習します。特別なランキング法がこの選択肢空間を探索し、タスク精度、アナログで処理される割合、必要なデジタルメモリ量という三つの目標を同時にバランスする層ごとの“マッピング”を見つけます。
ハードウェアに合うようにモデルを教える
アナログとデジタルを選ぶだけでなく、このフレームワークはネットワークを穏やかに再形状してハードウェアにより適合させることができます。たとえば、トランスフォーマーや畳み込みブロックの内部のいくつかの層を広げて、アナログタイルの行や列をより完全に埋めるようにし、遅延を増やさずに利用可能なリソースを多く活用することが可能です。これらのハードウェア認識的な適応により一部の層のパラメータ数は増えますが、アナログハードウェアが効率的に機能する場所に配置されるため、全体のエネルギーコストは低いままです。システムは段階的に学習します:まず全ての経路を公平に扱い、次に実際の量子化とアナログノイズを徐々に導入し、最後に精度と効率の最良のトレードオフを保つよう選択を微調整します。
より速い探索と優れたトレードオフ
研究チームはこの手法を複数の標準タスクで検証しました:CIFAR‑10での画像分類、COCOデータセットでの物体セグメンテーション、SQuADでの質問応答です。これらのテストを通じて、MPSおよびより高度なMPAASと呼ばれる手法は、一般的なベースラインと比べて精度を維持またはわずかに改善しつつ、高い割合のアナログ演算を利用するマッピングを一貫して見つけました。平均して、これらのマッピングは競合手法より約2.2倍速く発見され、全アナログ設計と比べてタスク性能で約3.4パーセントの向上を示しました。ハードウェアシミュレーションでは、得られた設計がフル精度のデジタルシステムに対してレイテンシを最大で約2.4倍短縮し、予測あたりのエネルギーを約2.6倍削減できることが示されました。
将来のAIハードウェアにとっての意義
非専門家にとっての主なメッセージは、モデル自体と同じくらいチップ上でのモデルの配置が重要だということです。本研究は、自動でハードウェアを意識した“プランナー”が、ネットワークのどの部分を高速だがノイズのあるアナログハードウェアで実行し、どの部分を精密なデジタルユニットに残すかを決め、場合によってはチップにより適合するようモデルを再形状できることを示しています。その結果、同等の精度を保ちながら大幅にエネルギーと時間を節約でき、強力なモデルを大規模なデータセンターだけでなく、スマートフォン、自動車、エッジサーバーといったデバイス上で実用化するための重要な一歩となります。
引用: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
キーワード: 混合精度ハードウェア, アナログ・インメモリ計算, ニューラルネットワークのマッピング, ハードウェア認識型AI, エネルギー効率の高い推論