Clear Sky Science · fr
Cartographie efficace basée sur un super-réseau des applications d’apprentissage profond vers du matériel en précision mixte via l’adaptation du modèle
Pourquoi des puces IA plus intelligentes sont importantes
L’intelligence artificielle moderne alimente tout, des assistants vocaux à l’analyse d’images médicales, mais les ordinateurs qui font tourner ces systèmes peinent sous la charge. À mesure que les modèles grandissent, ils exigent davantage d’énergie, de mémoire et de temps pour produire des prédictions. Cet article explore une nouvelle façon d’adapter les logiciels d’IA au matériel spécialisé afin que les systèmes puissent fonctionner plus vite et avec moins d’énergie tout en préservant leur précision. Il se concentre sur la combinaison de deux types de calcul — analogique et numérique — et sur la décision automatique des parties du réseau neuronal devant utiliser l’un ou l’autre.
Deux types de « cerveau » pour une même machine
Les puces IA actuelles commencent à mélanger des unités numériques traditionnelles avec des moteurs analogiques « in‑memory » capables d’effectuer de grandes opérations mathématiques directement dans la mémoire. Les unités analogiques sont extrêmement rapides et économes en énergie, mais elles sont aussi bruyantes et moins précises. Les unités numériques, en revanche, sont plus lentes et moins efficaces mais très fiables. Un défi central consiste à décider, couche par couche, où exécuter un réseau neuronal en analogique et où le maintenir en numérique pour que l’ensemble du système fonctionne bien. Si trop de couches tournent en analogique, la précision chute ; si trop restent numériques, les gains d’énergie et de vitesse disparaissent en grande partie.
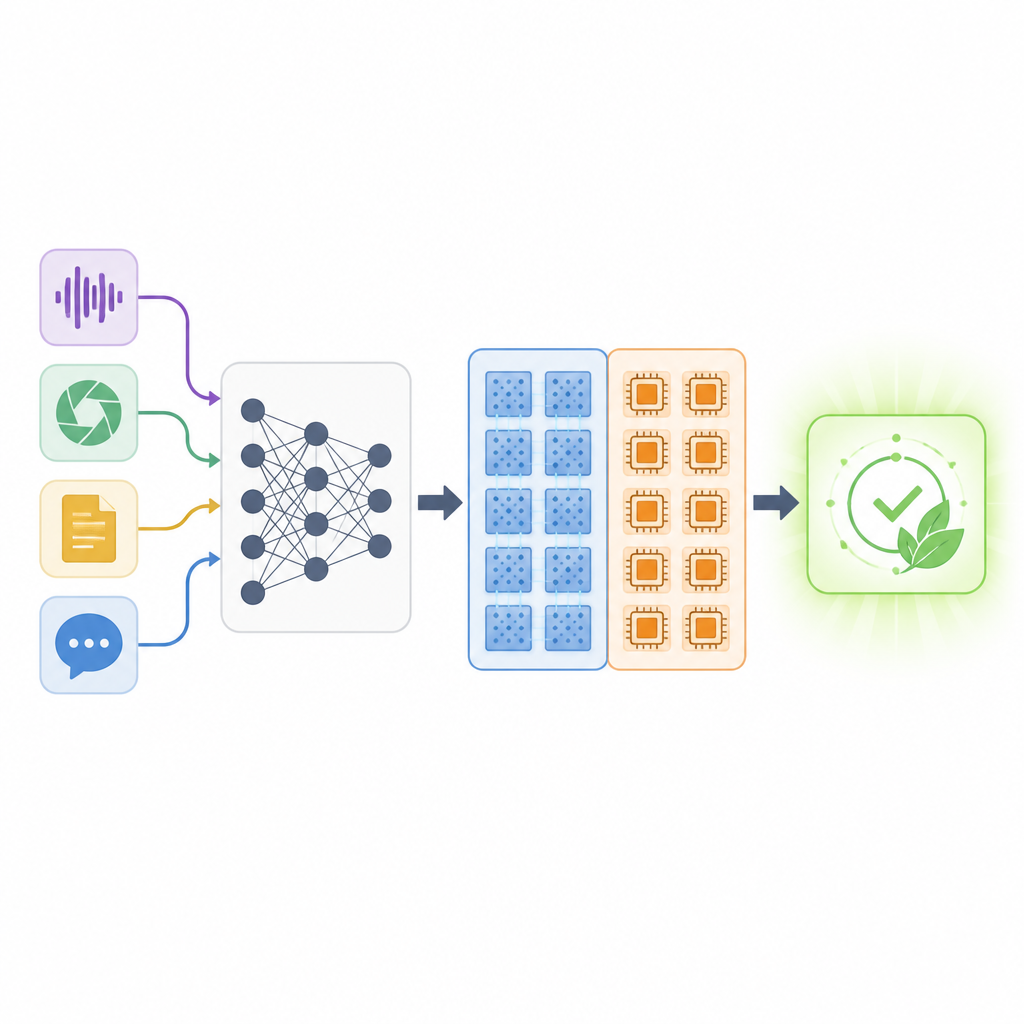
Une carte de nombreuses architectures possibles
Les auteurs introduisent le Super‑réseau en précision mixte, un grand modèle englobant qui contient simultanément de nombreuses versions possibles du même réseau neuronal. Pour chaque couche, ce super‑réseau inclut plusieurs options : une version numérique à différentes précisions en bits, une version analogique intégrant un bruit réaliste, et même la possibilité de sauter ou de remodeler des couches. Pendant l’entraînement, le système apprend non seulement les poids habituels du réseau, mais aussi la qualité de chaque choix matériel pour chaque couche. Une méthode de classement spéciale parcourt ensuite cet espace d’options pour trouver des « mappages » couche par couche qui équilibrent trois objectifs simultanément : la précision de la tâche, la part de calcul effectuée en analogique, et la mémoire numérique requise.
Apprendre au modèle à s’adapter au matériel
Au‑delà du choix entre analogique et numérique, le cadre peut ajuster légèrement la forme du réseau pour qu’il s’adapte plus naturellement au matériel. Par exemple, il peut élargir certaines couches internes d’un transformeur ou d’un bloc convolutionnel pour remplir plus complètement une tuile analogique, en utilisant davantage de lignes et de colonnes disponibles sans ajouter de latence. Ces adaptations conscientes du matériel augmentent le nombre de paramètres de certaines couches, mais comme elles sont placées là où le matériel analogique est efficace, le coût énergétique global reste faible. Le système s’entraîne par étapes : d’abord il traite tous les chemins de manière équitable, puis il introduit progressivement la quantification réelle et le bruit analogique, et enfin il affine les choix pour conserver les meilleurs compromis entre précision et efficacité.
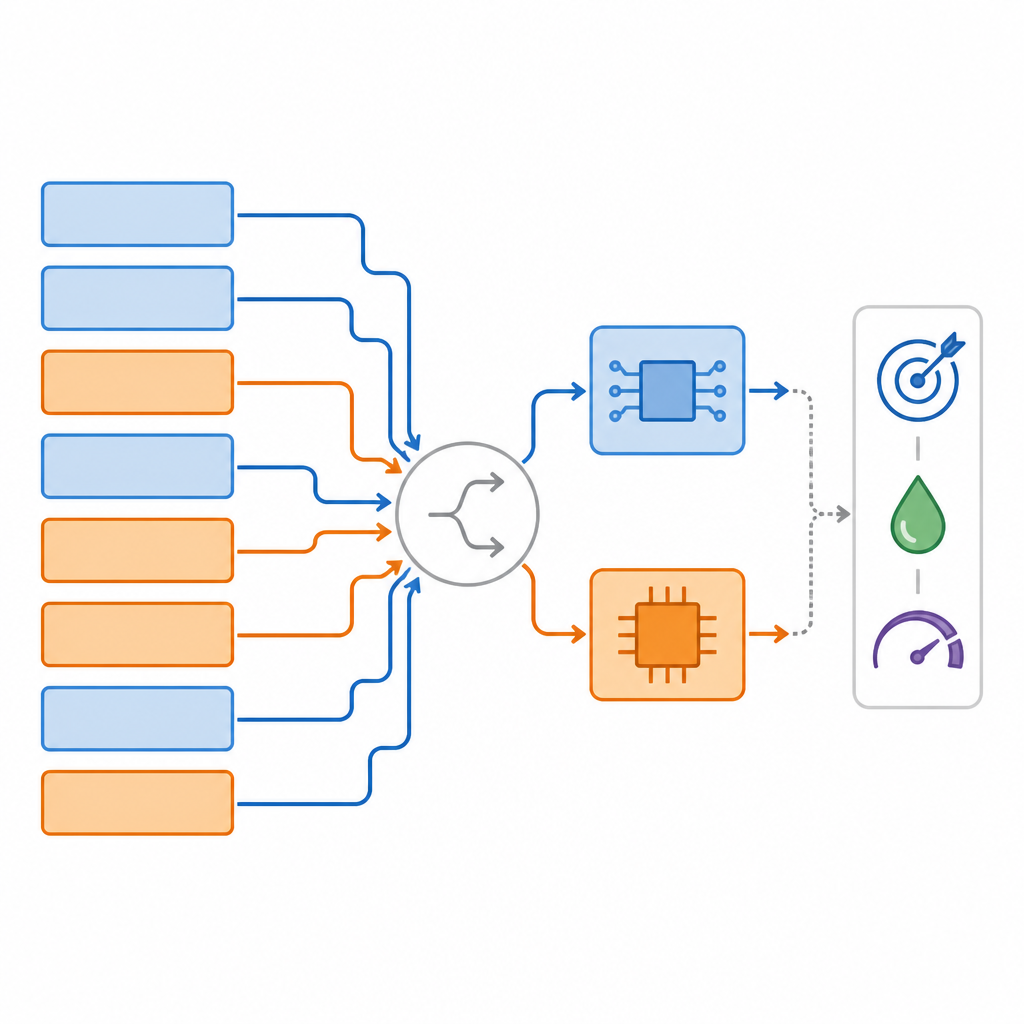
Recherches plus rapides et meilleurs compromis
L’équipe a testé son approche sur plusieurs tâches standards : classification d’images sur CIFAR‑10, segmentation d’objets sur le jeu de données COCO et question‑réponse sur SQuAD. Sur ces tests, leurs méthodes, appelées MPS et la version plus avancée MPAAS, ont systématiquement trouvé des mappages utilisant une forte fraction d’opérations analogiques tout en conservant ou en améliorant légèrement la précision par rapport aux références courantes. En moyenne, leurs mappages ont été découverts environ 2,2 fois plus rapidement que les méthodes concurrentes et ont offert environ 3,4 % d’amélioration des performances sur la tâche comparé à une conception entièrement analogique. Les simulations matérielles ont montré que les conceptions obtenues pouvaient réduire la latence jusqu’à environ 2,4 fois et l’énergie par prédiction d’environ 2,6 fois par rapport à des systèmes numériques en pleine précision.
Ce que cela signifie pour le matériel IA futur
Pour les non‑experts, le message principal est que la façon dont un modèle d’IA est disposé sur une puce compte presque autant que le modèle lui‑même. Ce travail montre qu’un « planificateur » automatique et conscient du matériel peut décider quelles parties d’un réseau doivent s’exécuter sur du matériel analogique rapide mais bruyant et lesquelles doivent rester sur des unités numériques précises, en remodelant parfois le modèle pour mieux l’adapter à la puce. Le résultat est une IA capable d’offrir une précision comparable tout en utilisant beaucoup moins d’énergie et de temps, une étape importante pour rendre les modèles puissants pratiques sur des appareils comme les téléphones, les voitures et les serveurs en périphérie plutôt que uniquement dans de grands centres de données.
Citation: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Mots-clés: matériel en précision mixte, calcul analogique en mémoire, cartographie de réseau neuronal, IA consciente du matériel, inférence économe en énergie