Clear Sky Science · ru
Эффективная карта приложений глубокого обучения на смешанно-точном оборудовании на основе суперсети с адаптацией модели
Почему умные чипы для ИИ важны
Современный искусственный интеллект питает все — от голосовых помощников до анализа медицинских изображений, но компьютеры, которые выполняют эти системы, сталкиваются с растущей нагрузкой. По мере увеличения размеров моделей им требуется больше энергии, памяти и времени на прогнозы. В этой статье исследуется новый способ соотнесения ПО ИИ со специализированным оборудованием, чтобы системы работали быстрее и с меньшим энергопотреблением, сохраняя при этом точность. В центре внимания — комбинация двух видов вычислений, аналоговых и цифровых, и автоматическое решение о том, какие части нейронной сети должны работать на каком типе.
Два типа «мозга» в одном устройстве
Современные чипы для ИИ начинают сочетать традиционные цифровые блоки с аналоговыми «в памяти» движками, которые могут выполнять крупные блоки вычислений прямо в памяти. Аналоговые блоки чрезвычайно быстры и энергоэффективны, но они шумны и менее точны. Цифровые блоки, напротив, медленнее и менее эффективны по энергии, но очень надежны. Ключевая задача — решать, слой за слоем, где нейронная сеть должна выполняться в аналоговом виде, а где — в цифровом, чтобы вся система работала хорошо. Если слишком много слоев выполняются в аналоговом виде, точность падает; если слишком много остаются цифровыми, выигрыш в энергии и скорости в значительной степени исчезает.
Карта множества возможных сетей
Авторы вводят Суперсеть со смешанной точностью (Mixed-Precision Supernetwork) — большой «зонтик» модели, который одновременно содержит множество вариантов одной и той же нейронной сети. Для каждого слоя эта суперсеть включает несколько опций: цифровую версию с разной битовой точностью, аналоговую версию с реалистичным шумом и даже возможность пропустить или изменить форму слоя. В процессе обучения система изучает не только обычные веса сети, но и то, насколько хорош каждый аппаратный выбор для каждого слоя. Специальный метод ранжирования затем просматривает это пространство опций, чтобы найти конкретные покомпонентные «отображения», которые одновременно балансируют три цели: точность задачи, долю вычислений на аналоговом оборудовании и требуемый объем цифровой памяти.
Обучение модели под оборудование
Помимо выбора между аналоговым и цифровым, этот подход может мягко изменять структуру сети так, чтобы она естественнее вписывалась в оборудование. Например, он может расширять отдельные внутренние слои трансформера или сверточного блока, чтобы они плотнее заполняли аналоговую плиту, используя больше доступных строк и столбцов без добавления задержки. Такие аппаратно-ориентированные адаптации увеличивают число параметров в некоторых слоях, но поскольку они размещены там, где аналоговое оборудование эффективно, общие энергозатраты остаются низкими. Система обучается по этапам: сначала все пути рассматриваются равноправно, затем постепенно вводится реальная квантизация и аналоговый шум, и в конце производится тонкая настройка выборов, чтобы сохранить лучшие компромиссы между точностью и эффективностью.
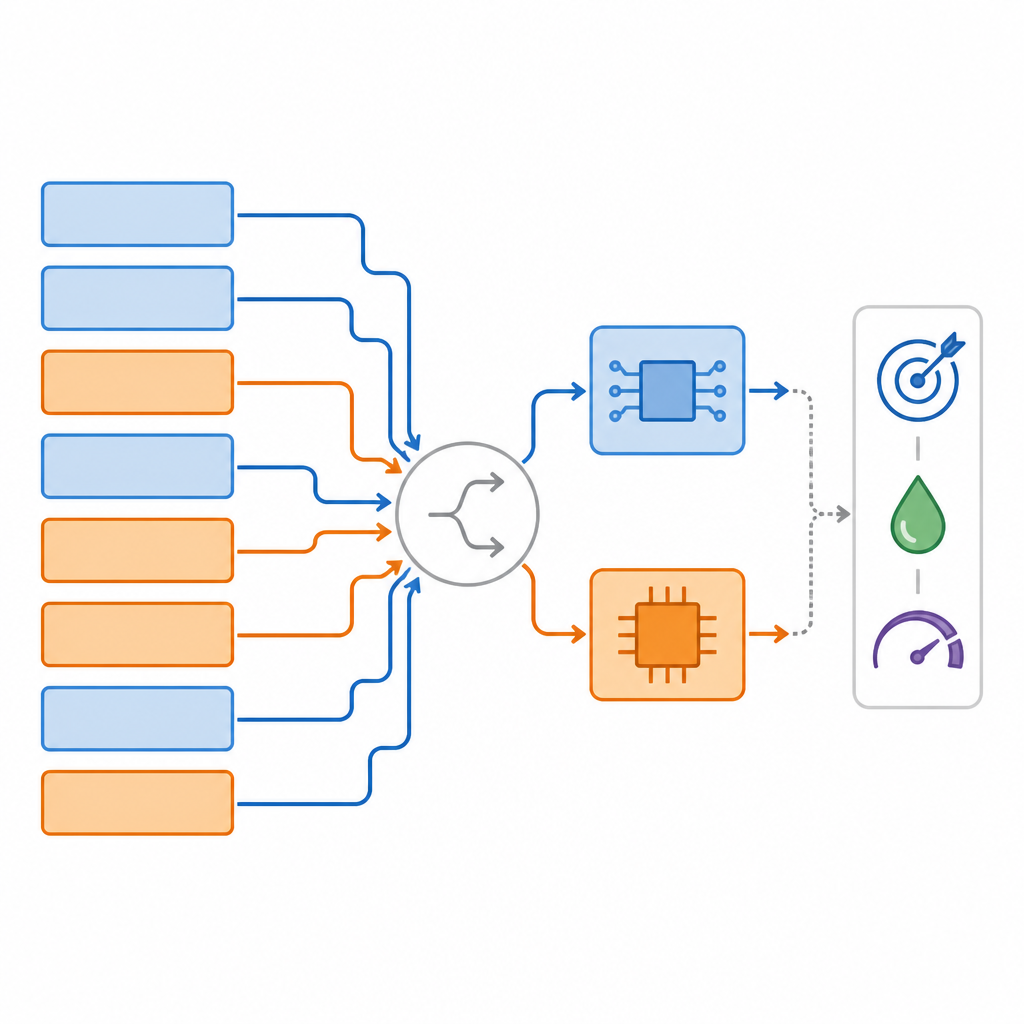
Быстрее поиск и лучшие компромиссы
Команда протестировала подход на нескольких стандартных задачах: классификация изображений на CIFAR-10, сегментация объектов на наборе COCO и ответы на вопросы на SQuAD. Во всех этих проверках их методы, названные MPS и более продвинутый MPAAS, стабильно находили отображения, использующие большую долю аналоговых операций при сохранении или даже небольшом улучшении точности по сравнению с распространенными базовыми подходами. В среднем их отображения обнаруживались примерно в 2,2 раза быстрее, чем у конкурентов, и давали около 3,4% прироста в производительности задач по сравнению с полностью аналоговым дизайном. Аппаратные симуляции показали, что полученные архитектуры могут сократить задержку примерно в 2,4 раза и энергию на предсказание примерно в 2,6 раза по сравнению с цифровыми системами с полной точностью.
Что это значит для будущего аппаратного обеспечения ИИ
Для неспециалистов главный вывод в том, что способ размещения модели ИИ на чипе важен почти так же, как и сама модель. Эта работа показывает, что автоматический аппаратно-ориентированный «планировщик» может решать, какие части сети должны выполняться на быстрых, но шумных аналоговых блоках, а какие — оставаться на точных цифровых узлах, иногда изменяя модель, чтобы она плотнее соответствовала чипу. В результате ИИ может давать сопоставимую точность, используя существенно меньше энергии и времени — важный шаг к тому, чтобы мощные модели стали практичными в таких устройствах, как телефоны, автомобили и периферийные серверы, а не только в крупных дата-центрах.
Цитирование: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Ключевые слова: оборудование со смешанной точностью, аналоговые вычисления в памяти, отображение нейронных сетей, аппаратно-ориентированный ИИ, энергоэффективный инференс