Clear Sky Science · pt
Mapeamento eficiente baseado em superrede de aplicações de aprendizado profundo para hardware de precisão mista usando adaptação do modelo
Por que chips de IA mais inteligentes importam
A inteligência artificial moderna alimenta tudo, desde assistentes de voz até análise de imagens médicas, mas os computadores que executam esses sistemas estão sobrecarregados. À medida que os modelos crescem, eles exigem mais energia, memória e tempo para fazer previsões. Este artigo explora uma nova forma de casar o software de IA com hardware especializado, para que os sistemas possam rodar mais rápido e com menos consumo de energia, mantendo a precisão. O foco é combinar dois tipos de computação, analógica e digital, e decidir automaticamente quais partes de uma rede neural devem usar cada um.
Dois tipos de “cérebro” para uma máquina
Os chips de IA atuais começam a misturar unidades digitais tradicionais com motores analógicos “em‑memória” que podem executar grandes blocos de cálculo dentro da própria memória. Unidades analógicas são extremamente rápidas e eficientes em energia, mas também são ruidosas e menos precisas. Unidades digitais, em contraste, são mais lentas e menos eficientes, mas altamente confiáveis. Um desafio central é decidir, camada por camada, onde uma rede neural deve rodar em analógico e onde deve permanecer digital para que o sistema como um todo funcione bem. Se muitas camadas rodarem em analógico, a precisão cai; se muitas permanecerem digitais, as economias de energia e os ganhos de velocidade desaparecem em grande parte.
Um mapa de muitas redes possíveis
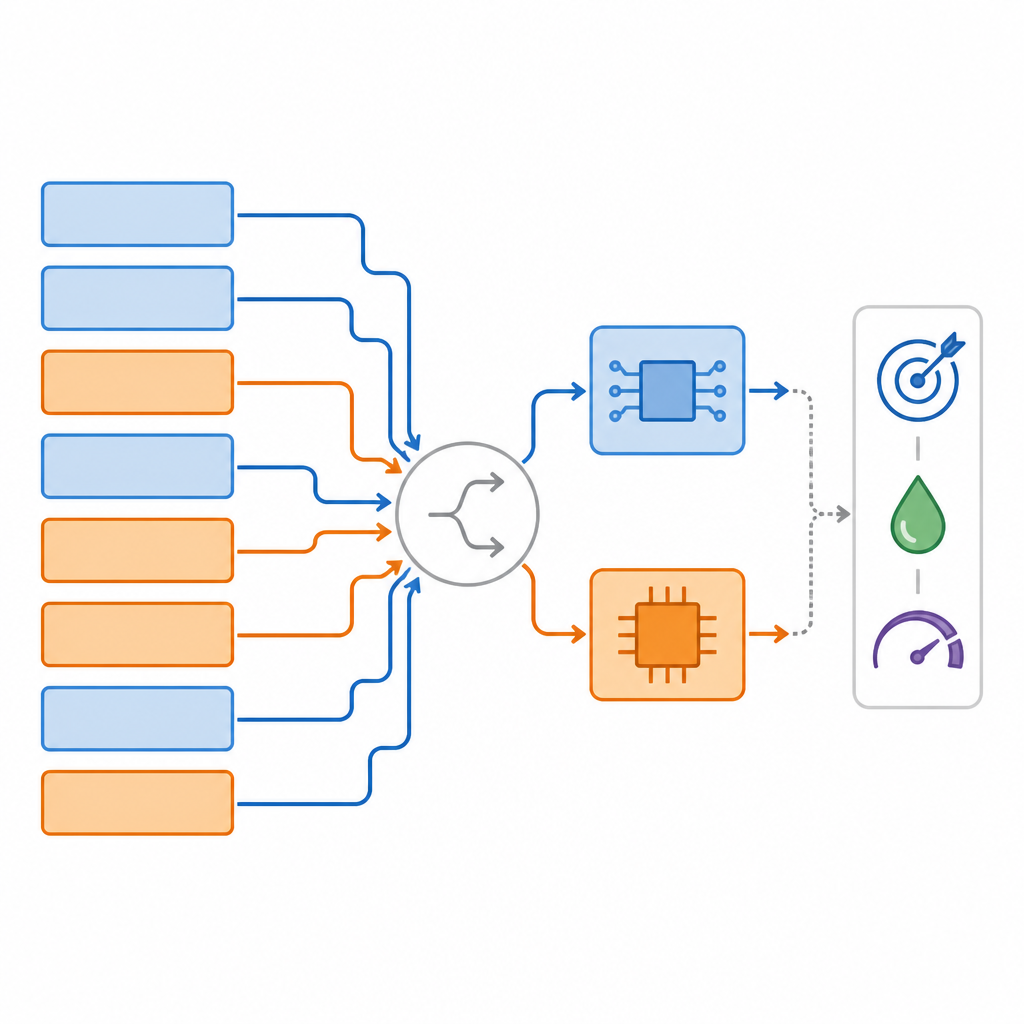
Os autores apresentam a Superrede de Precisão Mista, um grande modelo guarda‑chuva que contém muitas versões possíveis da mesma rede neural ao mesmo tempo. Para cada camada, essa superrede inclui várias opções: uma versão digital em diferentes precisões de bits, uma versão analógica que incorpora ruído realista e até a possibilidade de pular ou remodelar camadas. Durante o treinamento, o sistema aprende não apenas os pesos usuais da rede, mas também quão boa cada escolha de hardware é para cada camada. Um método especial de ranqueamento então explora esse espaço de opções para encontrar mapeamentos específicos camada a camada que equilibram três objetivos ao mesmo tempo: precisão na tarefa, quanto trabalho é feito em hardware analógico e quanta memória digital é necessária.
Ensinando o modelo a se ajustar ao hardware
Além de escolher entre analógico e digital, a estrutura pode suavemente remodelar a rede para que ela se ajuste ao hardware de forma mais natural. Por exemplo, pode alargar certas camadas internas de um transformador ou de um bloco convolucional para que preencham um tile analógico mais completamente, usando mais das linhas e colunas disponíveis sem adicionar latência. Essas adaptações conscientes do hardware aumentam o número de parâmetros em algumas camadas, mas como são colocadas onde o hardware analógico é eficiente, o custo energético global permanece baixo. O sistema treina em estágios: primeiro trata todos os caminhos de forma equitativa, depois introduz gradualmente a quantização real e o ruído analógico, e finalmente ajusta finamente as escolhas para manter os melhores trade‑offs entre precisão e eficiência.
Buscas mais rápidas e melhores trade‑offs
A equipe testou sua abordagem em várias tarefas padrão: classificação de imagens no CIFAR‑10, segmentação de objetos no conjunto de dados COCO e resposta a perguntas no SQuAD. Nesses testes, seus métodos, chamados MPS e o mais avançado MPAAS, encontraram consistentemente mapeamentos que utilizavam uma alta fração de operações analógicas mantendo ou até melhorando levemente a precisão em comparação com as linhas de base comuns. Em média, seus mapeamentos foram descobertos cerca de 2,2 vezes mais rápido que métodos concorrentes e proporcionaram aproximadamente 3,4% de ganho no desempenho da tarefa em comparação com um projeto totalmente analógico. Simulações de hardware mostraram que os projetos resultantes poderiam reduzir a latência em até cerca de 2,4 vezes e a energia por previsão em aproximadamente 2,6 vezes em relação a sistemas digitais de precisão total.
O que isso significa para o futuro do hardware de IA
Para leigos, a mensagem principal é que a forma como um modelo de IA é disposto em um chip importa quase tanto quanto o próprio modelo. Este trabalho mostra que um “planejador” automático e consciente do hardware pode decidir quais partes de uma rede devem rodar em hardware analógico rápido, porém ruidoso, e quais devem permanecer em unidades digitais precisas, às vezes remodelando o modelo para encaixá‑lo melhor no chip. O resultado é uma IA que pode entregar precisão similar enquanto usa muito menos energia e tempo — um passo importante para tornar modelos poderosos práticos em dispositivos como telefones, carros e servidores na borda, em vez de apenas em grandes centros de dados.
Citação: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Palavras-chave: hardware de precisão mista, computação analógica em memória, mapeamento de rede neural, IA consciente do hardware, inferência energeticamente eficiente