Clear Sky Science · nl
Supernetwerk-gebaseerde efficiënte toewijzing van deep learning-toepassingen aan mixed-precision hardware met modeladaptatie
Waarom slimmer AI-chips ertoe doen
Moderne kunstmatige intelligentie stuurt alles aan, van spraakassistenten tot medische beeldanalyse, maar de computers die deze systemen draaien raken overbelast. Naarmate modellen groter worden, vragen ze meer energie, geheugen en tijd voor voorspellingen. Dit artikel onderzoekt een nieuwe manier om AI-software op gespecialiseerde hardware af te stemmen, zodat systemen sneller en zuiniger kunnen draaien terwijl ze hun nauwkeurigheid behouden. De focus ligt op het combineren van twee rekenvormen — analoog en digitaal — en op het automatisch beslissen welke delen van een neuraal netwerk welke vorm moeten gebruiken.
Twee soorten ‘hersenen’ in één machine
De huidige AI-chips beginnen traditionele digitale eenheden te combineren met analoge "in-memory"-modules die grote blokken rekenwerk binnen het geheugen zelf kunnen uitvoeren. Analoge eenheden zijn extreem snel en energie-efficiënt, maar ze zijn ook ruisachtiger en minder precies. Digitale eenheden daarentegen zijn trager en minder efficiënt maar zeer betrouwbaar. Een belangrijke uitdaging is per laag te beslissen waar een neuraal netwerk analoog moet draaien en waar het digitaal moet blijven, zodat het hele systeem goed functioneert. Draait te veel analoog, dan gaat de nauwkeurigheid omlaag; blijft te veel digitaal, dan verdwijnen de energiebesparingen en snelheidswinst grotendeels.
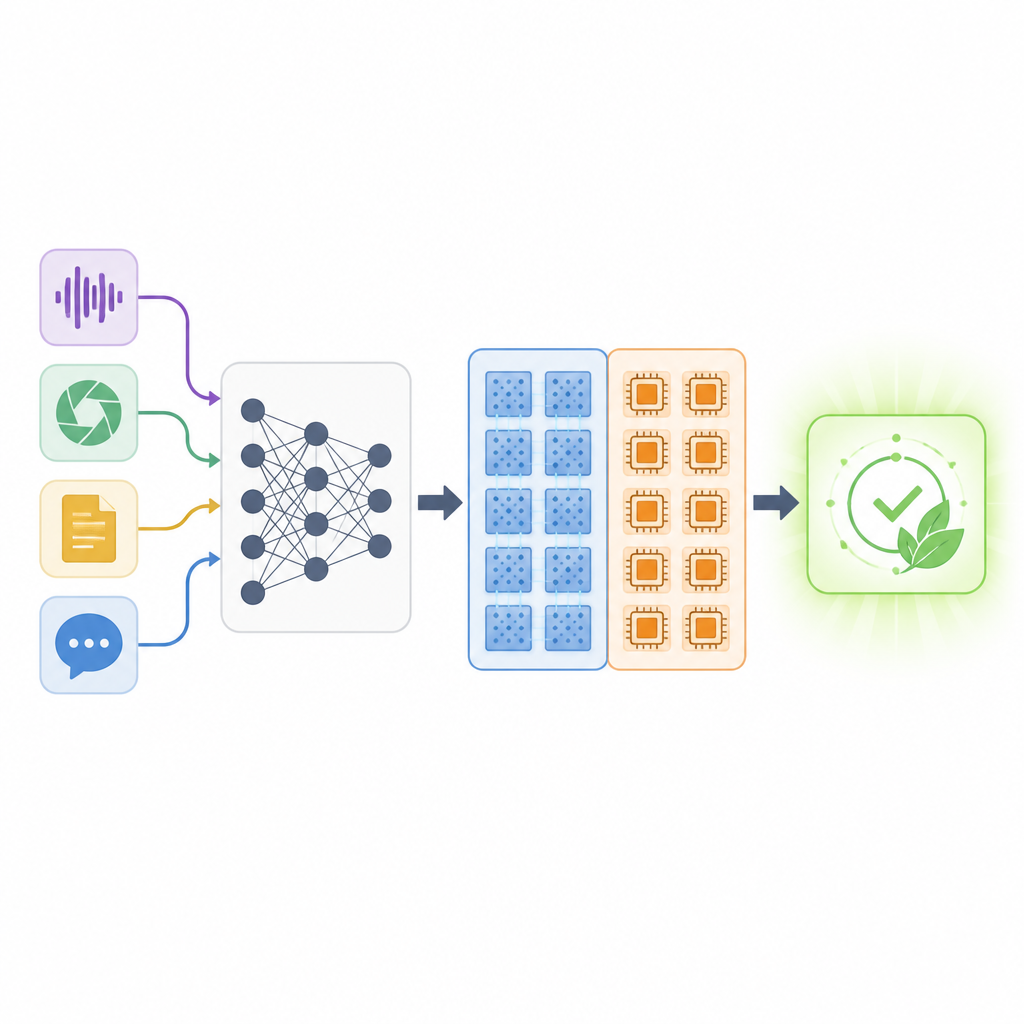
Een kaart van vele mogelijke netwerken
De auteurs introduceren het Mixed-Precision Supernetwork, een groot overkoepelend model dat veel mogelijke versies van hetzelfde neurale netwerk tegelijk bevat. Voor elke laag bevat dit supernetwerk meerdere opties: een digitale versie met verschillende bitprecisies, een analoge versie met realistische ruis, en zelfs de mogelijkheid om lagen over te slaan of van vorm te veranderen. Tijdens training leert het systeem niet alleen de gebruikelijke gewichten van het netwerk, maar ook hoe goed elke hardwarekeuze is voor elke laag. Een speciale rangschikmethode doorzoekt vervolgens deze ruimte van opties om specifieke laag-voor-laag "mappings" te vinden die drie doelen tegelijk balanceren: taaknauwkeurigheid, het aandeel werk op analoge hardware, en de benodigde digitale geheugenruimte.
Het model trainen om op de hardware te passen
Buiten de keuze tussen analoog en digitaal kan het raamwerk het netwerk subtiel omvormen zodat het beter bij de hardware past. Zo kan het bijvoorbeeld bepaalde interne lagen van een transformer- of convolutielaag verbreden zodat ze een analoge tegel vollediger vullen, gebruikmakend van meer rijen en kolommen zonder extra vertraging. Deze hardware-bewuste aanpassingen vergroten het aantal parameters in sommige lagen, maar omdat ze op plaatsen worden toegepast waar analoge hardware efficiënt is, blijft de totale energiekost laag. Het systeem traint in fasen: eerst behandelt het alle paden eerlijk, daarna introduceert het geleidelijk echte kwantisatie en analoge ruis, en ten slotte verfijnt het de keuzes om de beste trade-offs tussen nauwkeurigheid en efficiëntie te behouden.
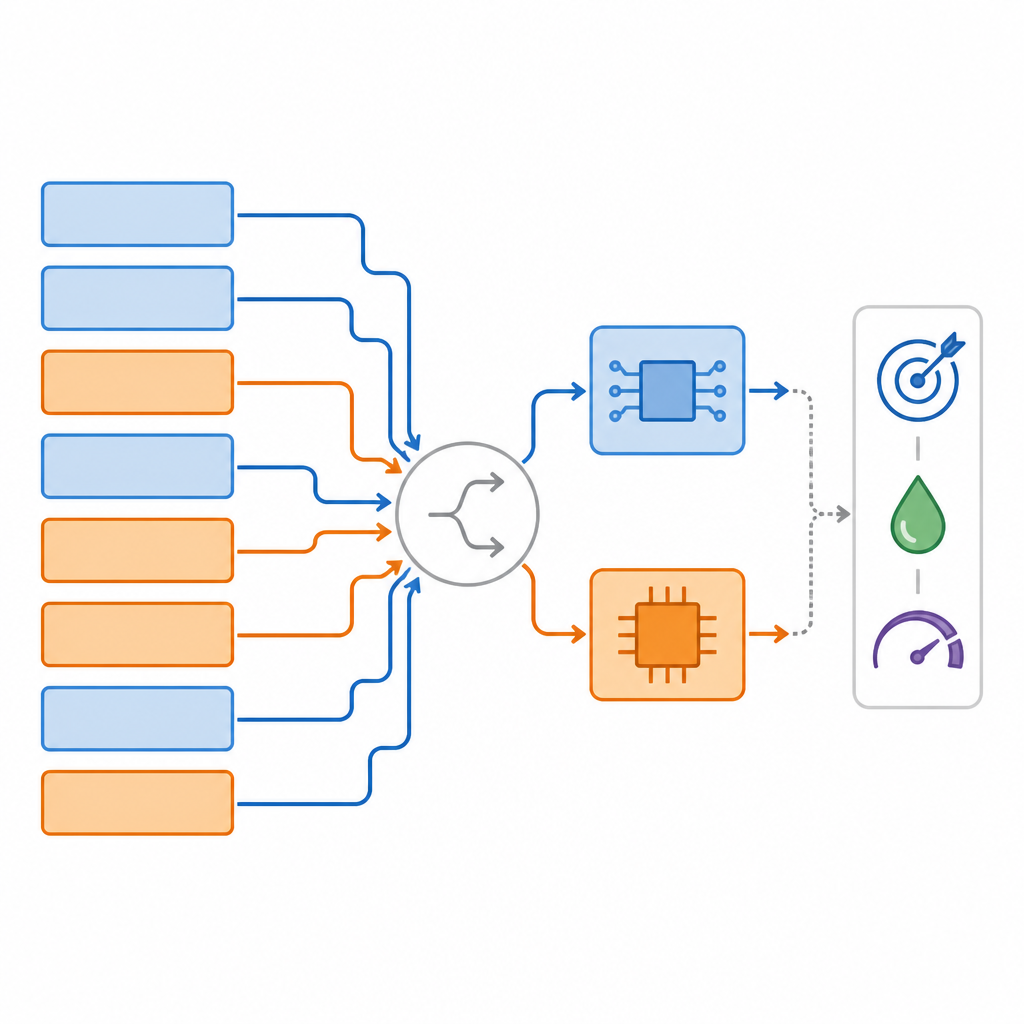
Snellere zoektochten en betere afwegingen
Het team testte hun aanpak op meerdere standaardtaken: beeldclassificatie op CIFAR-10, objectsegmentatie op de COCO-dataset en vraagbeantwoording op SQuAD. In al deze tests vonden hun methoden, MPS en het geavanceerdere MPAAS, consequent mappings die een groot deel van de bewerkingen analoog lieten verlopen terwijl de nauwkeurigheid gelijk bleef of licht verbeterde vergeleken met gangbare referenties. Gemiddeld werden hun mappings ongeveer 2,2 keer sneller gevonden dan concurrerende methoden en leverden ze een prestatieverbetering van circa 3,4 procent op ten opzichte van een volledig analoog ontwerp. Hardwaresimulaties lieten zien dat de resulterende ontwerpen de latency met ongeveer 2,4 keer en de energie per voorspelling met ruwweg 2,6 keer konden verminderen ten opzichte van volledig-precisie digitale systemen.
Wat dit betekent voor toekomstige AI-hardware
Voor niet-experts is de belangrijkste boodschap dat de manier waarop een AI-model op een chip wordt geplaatst bijna even belangrijk is als het model zelf. Dit werk toont aan dat een automatische, hardware-bewuste "planner" kan beslissen welke delen van een netwerk op snelle maar ruisige analoge hardware moeten draaien en welke op precieze digitale eenheden moeten blijven, en soms het model daarbij herschikt zodat het beter op de chip past. Het resultaat is AI die vergelijkbare nauwkeurigheid levert terwijl ze veel minder energie en tijd verbruikt — een belangrijke stap om krachtige modellen praktisch toepasbaar te maken in apparaten zoals telefoons, auto’s en edge-servers in plaats van alleen in grote datacenters.
Bronvermelding: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Trefwoorden: mixed precision hardware, analog in-memory computing, neural network mapping, hardware-aware AI, energy-efficient inference