Clear Sky Science · en
Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation
Why smarter AI chips matter
Modern artificial intelligence powers everything from voice assistants to medical image analysis, but the computers that run these systems are straining under the load. As models grow larger, they demand more energy, memory, and time to make predictions. This paper explores a new way to match AI software to specialized hardware so that systems can run faster and with less energy while still keeping their accuracy. It focuses on combining two kinds of computing, analog and digital, and on automatically deciding which parts of a neural network should use which kind.
Two kinds of brain for one machine
Today’s AI chips are starting to mix traditional digital units with analog “in‑memory” engines that can perform large blocks of math inside the memory itself. Analog units are extremely fast and energy‑efficient, but they are also noisy and less precise. Digital units, by contrast, are slower and less efficient but highly reliable. A key challenge is to decide, layer by layer, where a neural network should run in analog and where it should stay digital so that the whole system works well. If too many layers run in analog, accuracy drops; if too many stay digital, the energy savings and speed gains largely disappear.
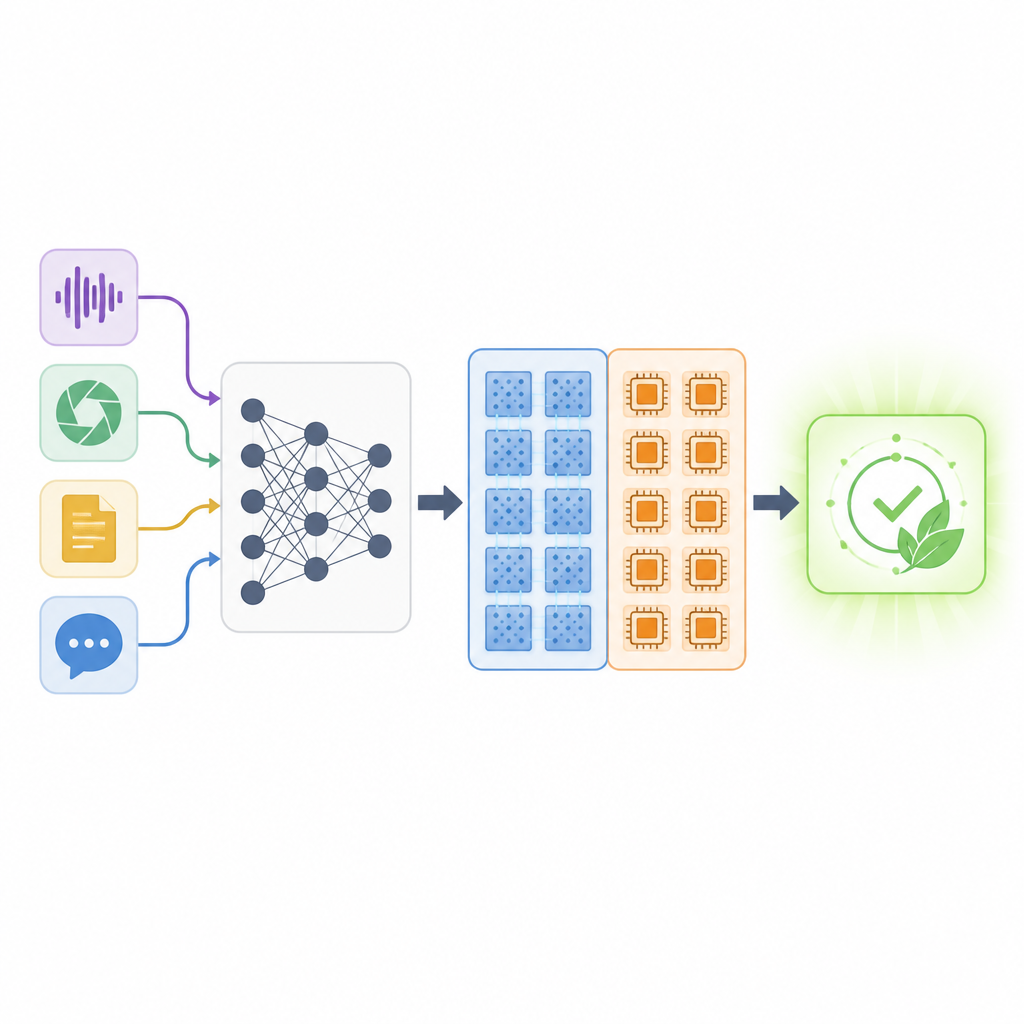
A map of many possible networks
The authors introduce the Mixed‑Precision Supernetwork, a large umbrella model that contains many possible versions of the same neural network at once. For every layer, this supernetwork includes several options: a digital version at different bit‑precisions, an analog version that includes realistic noise, and even the possibility to skip or reshape layers. During training, the system learns not just the usual weights of the network, but also how good each hardware choice is for each layer. A special ranking method then searches this space of options to find specific layer‑by‑layer “mappings” that balance three goals at the same time: task accuracy, how much work is done on analog hardware, and how much digital memory is required.
Teaching the model to fit the hardware
Beyond choosing between analog and digital, the framework can gently reshape the network so that it fits the hardware more naturally. For example, it can widen certain inner layers of a transformer or convolutional block so they fill an analog tile more completely, using more of the available rows and columns without adding delay. These hardware‑aware adaptations increase the number of parameters in some layers, but because they are placed where analog hardware is efficient, the overall energy cost remains low. The system trains in stages: first it treats all paths fairly, then gradually introduces real quantization and analog noise, and finally fine‑tunes the choices to keep the best trade‑offs between accuracy and efficiency.
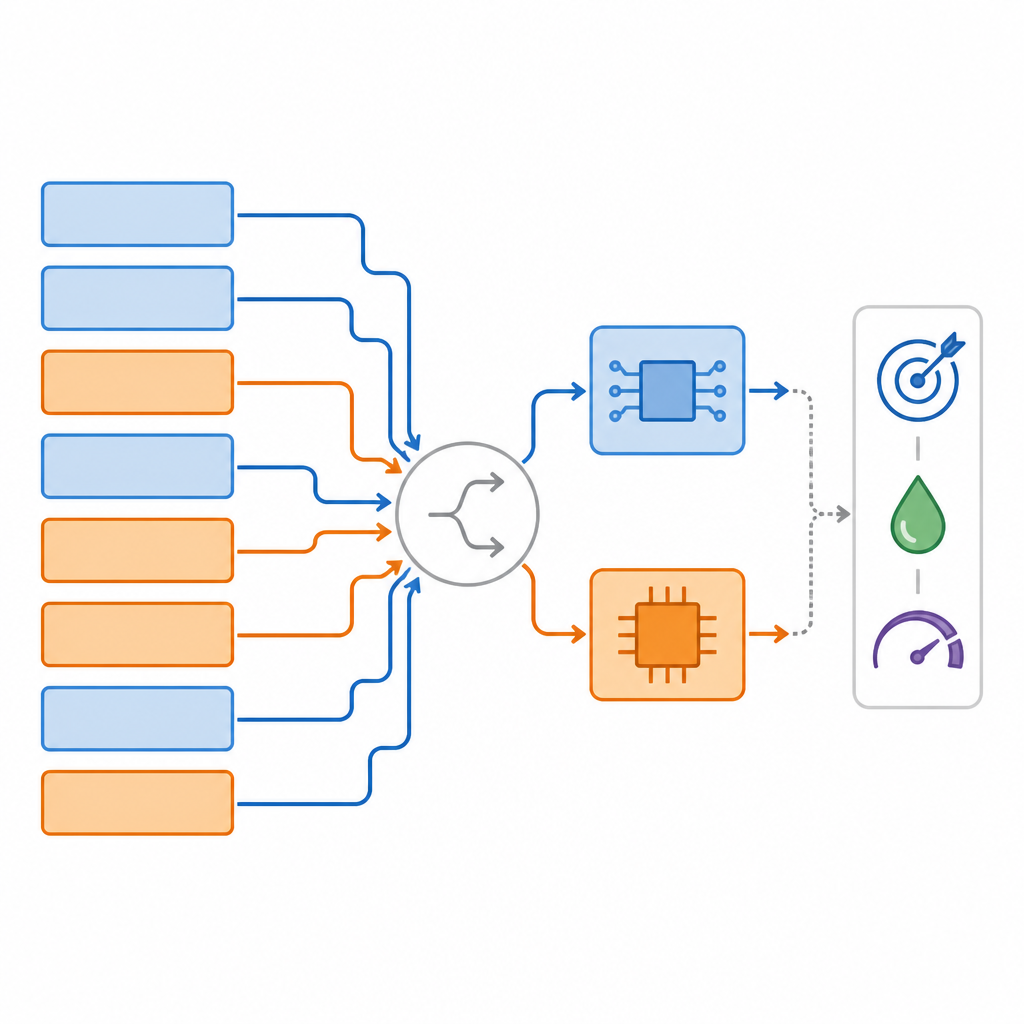
Faster searches and better trade‑offs
The team tested their approach on several standard tasks: image classification on CIFAR‑10, object segmentation on the COCO dataset, and question answering on SQuAD. Across these tests, their methods, called MPS and the more advanced MPAAS, consistently found mappings that used a high fraction of analog operations while keeping or even slightly improving accuracy compared with common baselines. On average, their mappings were discovered about 2.2 times faster than competing methods and delivered around a 3.4 percent boost in task performance compared with an all‑analog design. Hardware simulations showed that the resulting designs could cut latency by up to about 2.4 times and energy per prediction by roughly 2.6 times relative to full‑precision digital systems.
What this means for future AI hardware
For non‑experts, the main message is that the way an AI model is laid out on a chip matters almost as much as the model itself. This work shows that an automatic, hardware‑aware “planner” can decide which parts of a network should run on fast but noisy analog hardware and which should remain on precise digital units, sometimes reshaping the model to fit the chip more snugly. The result is AI that can deliver similar accuracy while using far less energy and time, an important step toward making powerful models practical in devices like phones, cars, and edge servers rather than only in large data centers.
Citation: Benmeziane, H., Lammie, C., Boybat, I. et al. Supernetwork-based efficient mapping of deep learning applications to mixed-precision hardware using model adaptation. Nat Commun 17, 4501 (2026). https://doi.org/10.1038/s41467-026-71071-1
Keywords: mixed precision hardware, analog in-memory computing, neural network mapping, hardware-aware AI, energy-efficient inference