Clear Sky Science · ru
Надёжная схема нулевого аудиоветмартинга с использованием многофункциональных отпечатков и машинного обучения
Почему скрытые отметки в звуке важны
Каждый день песни, подкасты и записи копируются, стримятся и распространяются в Интернете. Такой лёгкий доступ удобен слушателям, но усложняет авторам и компаниям задачу доказать право собственности на аудио, не вредя при этом самому звуку. В описанной статье предложен новый способ «маркировки» аудио, который позволяет подтвердить владение даже после серьёзной обработки, при этом исходный звук остаётся полностью нетронутым.
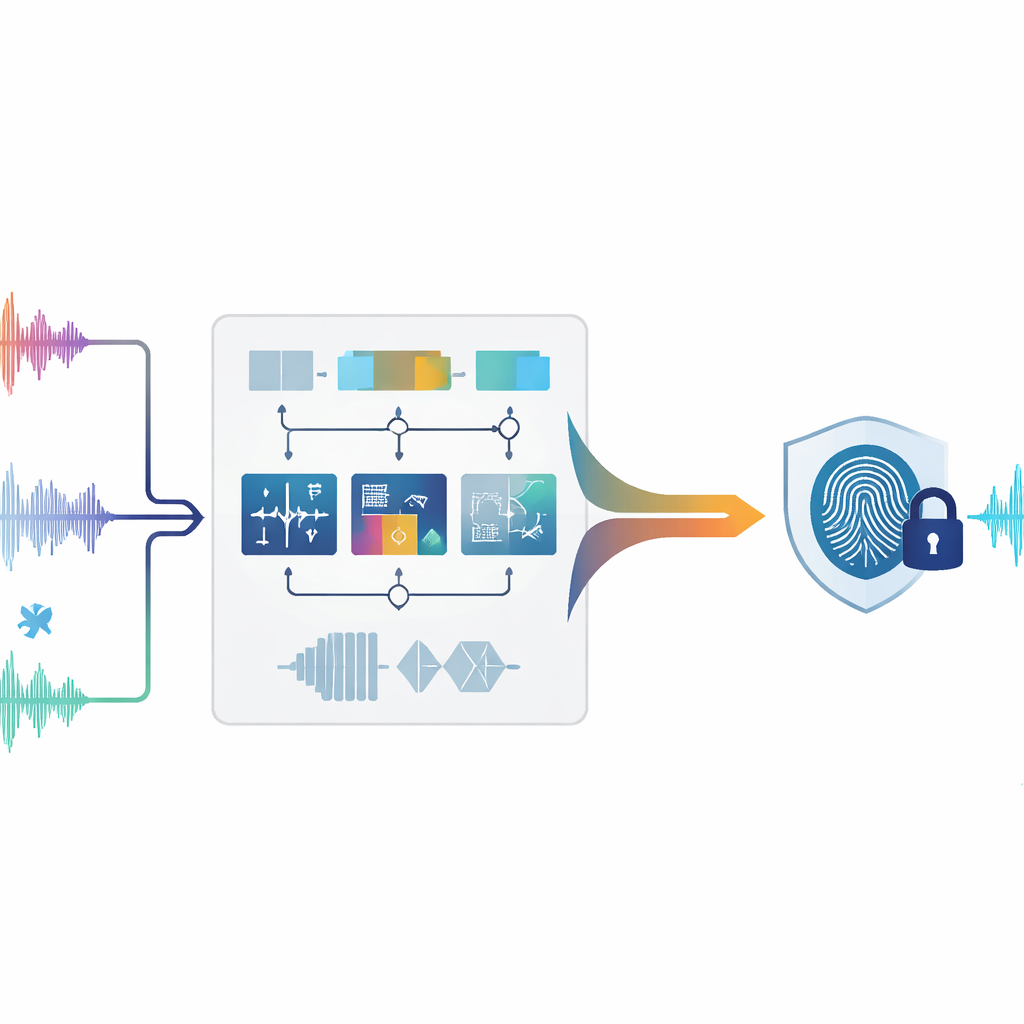
Защита звука без его изменения
Традиционное цифровое встраивание меток работает как едва заметный штамп, вдавленный в изображение или трек: в исходный файл добавляются дополнительные данные. Однако в аудио даже крошечные изменения могут вызвать слышимые артефакты или создать правовые проблемы, особенно для судебных, медицинских или архивных записей, которые должны оставаться нетронутыми. Нулевой водяной знак идёт другим путём. Вместо изменения звука он изучает уникальные шаблоны, уже присутствующие в аудиосигнале, и использует их для создания «отпечатка», который хранится отдельно. В спорной ситуации этот отпечаток можно сравнить с подозрительной записью, чтобы проверить совпадение — при этом никаких правок в исходном сигнале не требуется.
Прослушивание аудио с разных сторон
Авторы предлагают систему нулевого водяного знака, которая анализирует аудио одновременно несколькими взаимодополняющими методами. Сначала звук разбивается на короткие неперекрывающиеся отрезки, или фреймы. Для каждого фрейма система измеряет девять различных признаков, описывающих поведение звука во времени, распределение энергии по низким и высоким тонам и структуру сигнала при трактовке его как сети взаимосвязанных отсчётов. Некоторые признаки отражают быстрые изменения, такие как внезапные удары или атаки; другие фиксируют, где сосредоточена основная энергия в спектре или как широка полоса частот; ещё одни извлекают общую форму сигнала через математические преобразования. В совокупности эти измерения дают богатый портрет каждого момента в аудио.
От подробных измерений — к стабильному отпечатку
Не все свойства звука одинаково хорошо переживают агрессивную обработку. Сжатие, фильтрация, ресемплинг, а также изменения времени или тона могут исказить одни признаки и почти не затронуть другие. Чтобы учесть это, метод оценивает поведение каждого из девяти признаков при множестве смоделированных атак. Признаки, остающиеся стабильными, получают больший вес, тогда как колеблющиеся — уменьшаются в значимости. Для каждого фрейма взвешенные признаки объединяются в одно составное значение. Скользящее сравнение с соседними фреймами затем превращает эту непрерывную кривую в последовательность нулей и единиц, по аналогии с преобразованием звукового шаблона в штрих-код. Эта двоичная последовательность комбинируется с желаемой водяной меткой (например, небольшим логотипом, преобразованным в биты), создавая окончательный ауди-отпечаток, привязанный к конкретному произведению.

Обучение машины читать через шум
Главная задача — восстановить тот же отпечаток после того, как аудио подверглось атакам, например добавлению шума, сжатию в MP3 или небольшим изменениям скорости воспроизведения. Для этого авторы обучают модель машинного обучения под названием Случайный лес (Random Forest). В процессе обучения система видит множество примеров одинаковых фреймов как в исходном виде, так и после различных искажений, вместе с правильной двоичной «меткой» для каждого фрейма. Случайный лес учится, какие сочетания временных, частотных и структурных признаков соответствуют 0 или 1. Позже, при анализе подозрительной записи, её фреймы обрабатывают аналогично, и обучённый лес предсказывает двоичную последовательность. Сопоставляя эту предсказанную последовательность с сохранённым отпечатком, можно реконструировать исходную водяную метку и сравнить её с эталоном. Авторы также приводят математическое обоснование того, почему акцент на стабильных признаках и использование классификатора на основе голосования позволяют поддерживать низкий уровень ошибок восстановления даже при сильных атаках.
Как метод выдерживает испытания
Для проверки системы исследователи применили её к 100 музыкальным отрывкам из разных жанров, а также к образцам речи и звукам окружающей среды из известных публичных наборов данных. Затем водяной знак подвергали широкому спектру воздействий: добавляли фоновый шум, применяли высоко- и низкочастотную фильтрацию, MP3-сжатие, ресемплинг и пере-квантование, небольшие изменения скорости воспроизведения и сдвиги тона. Также использовали сложный набор тестов Stirmark, специально созданный для испытаний схем встраивания меток. Во почти всех условиях восстановленные водяные метки отличались от оригиналов менее чем в четырёх процентах бит, а показатели схожести оставались очень высокими, то есть структура метки в основном сохранялась. По сравнению с несколькими современными методами нулевого водяного знака новый подход в целом показал равную или лучшую устойчивость, особенно при сложных временных и тональных модификациях, при этом не нарушая чистоты аудио.
Что это значит для повседневного аудио
Проще говоря, работа демонстрирует возможность доказать право собственности на песню или запись без изменения ни одного сэмпла исходного звука. Тщательно сочетая множество точек зрения на аудиосигнал и применяя машинное обучение для прочтения через искажения, метод формирует устойчивый отпечаток, выживающий при обычной обработке в реальном мире. Это делает его перспективным инструментом для музыкальных лейблов, стриминговых платформ, архивов и любых ситуаций, где аудио должно оставаться нетронутым и одновременно эффективно защищённым от злоупотреблений.
Цитирование: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Ключевые слова: аудио водяные метки, цифровое авторское право, машинное обучение, обработка сигналов, защита контента