Clear Sky Science · es
Un esquema robusto de esteganografía cero para audio usando huellas multi‑características y aprendizaje automático
Por qué importan las marcas ocultas en el sonido
Cada día, canciones, pódcasts y grabaciones se copian, transmiten y comparten por internet. Este acceso fácil es fantástico para los oyentes, pero dificulta que creadores y empresas demuestren la propiedad de su audio sin dañar el sonido. El trabajo aquí descrito presenta una nueva forma de “marcar” el audio para poder probar la titularidad, incluso tras procesos agresivos, manteniendo intacto el sonido original.
Proteger el sonido sin tocarlo
La esteganografía digital tradicional funciona un poco como un sello tenue estampado en una imagen o una canción: se añaden datos al archivo original. Con el audio, sin embargo, incluso cambios minúsculos pueden crear artefactos audibles o plantear problemas legales, especialmente en grabaciones forenses, médicas o archivísticas que deben permanecer inalteradas. La esteganografía cero sigue otro camino. En lugar de alterar el sonido, estudia patrones únicos ya presentes en el audio y los utiliza para construir una “huella” que se guarda por separado. En caso de disputa, esa huella puede compararse con una grabación sospechosa para verificar si coinciden: no se requiere editar la señal original.
Escuchar el audio desde muchos ángulos
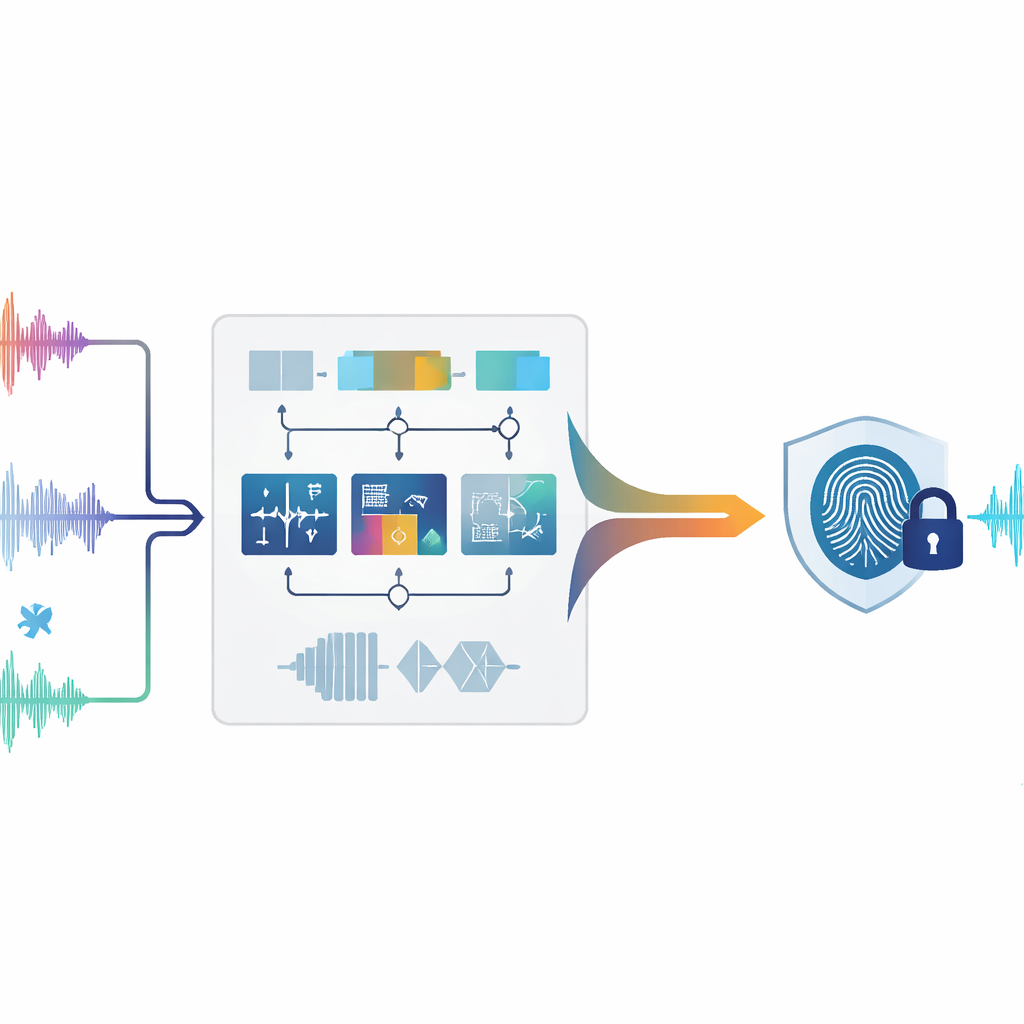
Los autores proponen un sistema de esteganografía cero que examina el audio de varias maneras complementarias a la vez. Primero, el sonido se divide en fragmentos cortos y no solapados, o tramas. Para cada trama, el sistema mide nueve características diferentes que describen cómo se comporta el sonido en el tiempo, cómo se distribuye su energía entre tonos bajos y altos y cómo se estructura cuando se trata como una red de muestras relacionadas. Algunas características reflejan cambios rápidos, como golpes o inicios bruscos; otras capturan dónde se concentra la mayor parte de la energía en el espectro o qué tan amplia es la gama de frecuencias; y otras destilan la forma global de la señal mediante transformadas matemáticas. En conjunto, estas medidas pintan un retrato rico de cada instante del audio.
De medidas ricas a una huella estable
No todos los aspectos de un sonido sobreviven igual a un procesamiento intenso. La compresión, el filtrado, el remuestreo y los cambios de tiempo o tono pueden distorsionar algunas características y dejar otras prácticamente intactas. Para gestionarlo, el método evalúa cómo se comporta cada una de las nueve características ante muchos ataques simulados distintos. Las características que permanecen estables reciben mayor importancia, mientras que las que fluctúan se atenúan. Para cada trama, las características ponderadas se combinan en un único valor compuesto. Una comparación deslizante contra las tramas vecinas convierte luego esta traza continua en una secuencia de ceros y unos, al modo de transformar un patrón sonoro en un código de barras. Esta secuencia binaria se combina entonces con la marca deseada (por ejemplo, una pequeña imagen de logo convertida en bits), produciendo la huella de audio final vinculada de forma única a ese contenido.

Enseñar a una máquina a leer entre el ruido
El reto central es recuperar la misma huella después de que el audio haya sido atacado —por ejemplo, añadiendo ruido, comprimiéndolo a MP3 o cambiando ligeramente su velocidad. Para resolverlo, los autores entrenan un modelo de aprendizaje automático llamado Bosque Aleatorio (Random Forest). Durante el entrenamiento, el sistema ve muchos ejemplos de las mismas tramas de audio tanto en su forma original como tras diferentes distorsiones, junto con la etiqueta binaria correcta para cada trama. El Bosque Aleatorio aprende qué combinaciones de características temporales, frecuenciales y estructurales corresponden a un 0 o a un 1. Más tarde, cuando se analiza una grabación sospechosa, sus tramas se procesan de la misma manera y el bosque entrenado predice la secuencia binaria. Al combinar esta secuencia predicha con la huella almacenada, la marca original puede reconstruirse y compararse con la verdadera. Los autores también aportan un argumento matemático que explica por qué enfatizar las características estables y usar un clasificador por votación debería mantener bajos los errores de reconstrucción, incluso bajo ataques severos.
Cómo resiste el método
Para evaluar el sistema, los investigadores lo aplicaron a 100 fragmentos musicales de varios géneros y a sonidos adicionales de habla y ambientales procedentes de conjuntos de datos públicos bien conocidos. Luego sometieron el contenido marcado a una amplia gama de abusos: ruido de fondo añadido, filtrado paso alto y paso bajo, compresión MP3, remuestreo y requantización, pequeños cambios en la velocidad de reproducción y desplazamientos de tono. También emplearon una batería de pruebas exigente llamada Stirmark, diseñada específicamente para desafiar esquemas de marcas. En casi todas las condiciones, las marcas recuperadas difirieron de las originales en menos del cuatro por ciento de los bits, y las puntuaciones de similitud se mantuvieron muy altas, lo que indica que el patrón de la marca se preservó en gran medida. Al compararlo con varios métodos de esteganografía cero de vanguardia, el nuevo enfoque mostró en general una resistencia igual o superior, particularmente frente a modificaciones complejas de tiempo y tono, conservando a la vez el audio perfectamente limpio.
Qué significa esto para el audio cotidiano
En términos sencillos, este trabajo demuestra que es posible probar la titularidad de una canción o grabación sin cambiar ni una sola muestra del sonido subyacente. Combinando cuidadosamente múltiples puntos de vista sobre la señal de audio y usando aprendizaje automático para leer a través de las distorsiones, el método produce una huella robusta que sobrevive al procesamiento habitual del mundo real. Esto lo convierte en una herramienta prometedora para discográficas, plataformas de streaming, archivos y cualquier situación en la que el audio deba permanecer intacto pero aun así estar fuertemente protegido contra el uso indebido.
Cita: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Palabras clave: esteganografía de audio, derechos digitales, aprendizaje automático, procesamiento de señales, protección de contenido