Clear Sky Science · de
Ein robustes Null-Wasserzeichen-Verfahren für Audio mit multifunktionalen Fingerabdrücken und maschinellem Lernen
Warum versteckte Kennzeichen in Klang wichtig sind
Jeden Tag werden Lieder, Podcasts und Aufnahmen im Internet kopiert, gestreamt und geteilt. Dieser leichte Zugriff ist für Hörerinnen und Hörer großartig, erschwert jedoch für Urheber und Firmen den Eigentumsnachweis an Audiodateien, ohne den Klang selbst zu verändern. Die hier beschriebene Studie stellt eine neue Methode vor, Audio so zu „markieren“, dass Eigentum auch nach starker Bearbeitung nachgewiesen werden kann, während der Originalklang unverändert bleibt.
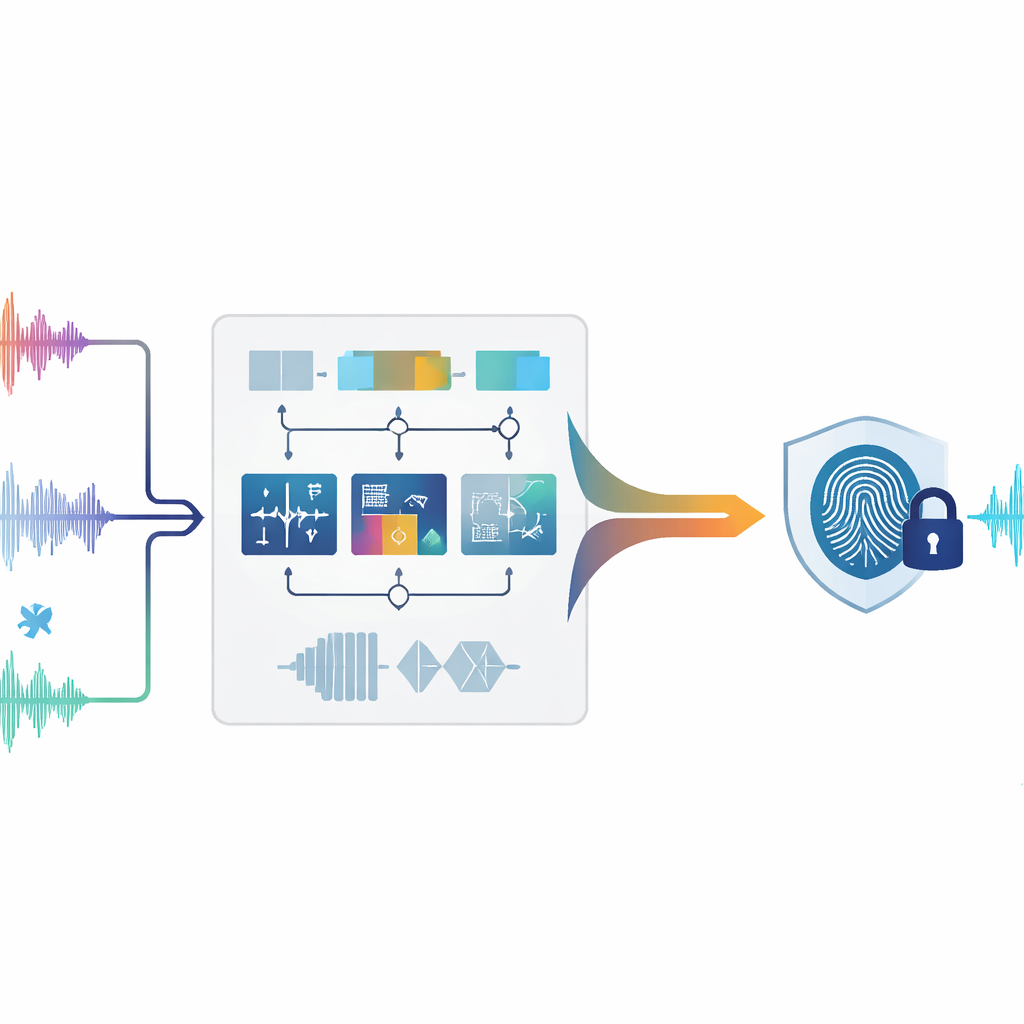
Schutz des Klangs, ohne ihn zu berühren
Traditionelles digitales Wasserzeichen funktioniert ein wenig wie ein kaum sichtbarer Stempel in einem Bild oder einem Song: Zusätzliche Daten werden der Originaldatei hinzugefügt. Bei Audio können jedoch schon kleinste Änderungen hörbare Artefakte erzeugen oder rechtliche Probleme verursachen, insbesondere bei forensischen, medizinischen oder archivischen Aufnahmen, die makellos bleiben müssen. Null-Wasserzeichen geht einen anderen Weg. Anstatt den Klang zu verändern, untersucht es einzigartige Muster, die bereits im Audio vorhanden sind, und nutzt diese, um einen „Fingerabdruck“ zu erstellen, der an anderer Stelle gespeichert wird. Im Streitfall kann dieser Fingerabdruck mit einer verdächtigen Aufnahme verglichen werden — Änderungen am ursprünglichen Signal sind dafür nicht erforderlich.
Audio aus vielen Blickwinkeln betrachten
Die Autoren schlagen ein Null-Wasserzeichen-System vor, das Audio gleichzeitig auf mehrere, sich ergänzende Weisen analysiert. Zunächst wird der Klang in kurze, nicht überlappende Abschnitte, sogenannte Frames, aufgeteilt. Für jeden Frame misst das System neun verschiedene Merkmale, die beschreiben, wie sich der Klang über die Zeit verhält, wie sich seine Energie auf tiefe und hohe Töne verteilt und wie seine Struktur aussieht, wenn man sie als Netzwerk verwandter Abtastwerte betrachtet. Einige Merkmale spiegeln schnelle Veränderungen wider, etwa plötzliche Schläge oder Einsätze; andere erfassen, wo sich die meiste Energie im Spektrum befindet oder wie breit das Frequenzspektrum ist; wieder andere verdichten die Gesamtform des Signals in mathematischen Transformationen. Zusammen liefern diese Messungen ein detailreiches Porträt jedes Moments im Audio.
Von detaillierten Messungen zu einem stabilen Fingerabdruck
Nicht alle Aspekte eines Klangs überstehen starke Bearbeitungen gleichermaßen gut. Kompression, Filterung, Resampling sowie Zeit- oder Tonhöhenveränderungen können einige Merkmale verzerren, während andere nahezu unberührt bleiben. Um damit umzugehen, bewertet die Methode, wie sich jedes der neun Merkmale unter vielen simulierten Angriffen verhält. Merkmale, die stabil bleiben, erhalten höhere Gewichtung, jene, die schwanken, werden heruntergestuft. Für jeden Frame werden die gewichteten Merkmale zu einem einzigen zusammengesetzten Wert verschmolzen. Ein gleitender Vergleich mit benachbarten Frames wandelt diese kontinuierliche Spur dann in eine Folge von Nullen und Einsen um, ähnlich wie ein Barcode aus einem Klangmuster entsteht. Diese binäre Abfolge wird anschließend mit dem gewünschten Wasserzeichen (zum Beispiel einem kleinen Logo, in Bits umgewandelt) kombiniert und ergibt den endgültigen Audio-Fingerabdruck, der eindeutig mit diesem Inhalt verknüpft ist.

Eine Maschine darin trainieren, trotz Störungen zu lesen
Die zentrale Herausforderung besteht darin, denselben Fingerabdruck wiederherzustellen, nachdem das Audio angegriffen wurde — etwa durch Hinzufügen von Rauschen, MP3-Kompression oder leichte Geschwindigkeitsänderungen. Zur Lösung trainieren die Autoren ein Modell des maschinellen Lernens, einen Random Forest. Während des Trainings sieht das System viele Beispiele derselben Audioframes sowohl im Originalzustand als auch nach unterschiedlichen Verzerrungen, zusammen mit dem korrekten binären „Label“ für jeden Frame. Der Random Forest lernt, welche Kombinationen aus Zeit-, Frequenz- und Strukturmerkmalen einem 0 oder einem 1 entsprechen. Später, wenn eine verdächtige Aufnahme analysiert wird, werden ihre Frames auf dieselbe Weise verarbeitet und der trainierte Wald sagt die binäre Folge voraus. Durch die Kombination dieser vorhergesagten Folge mit dem gespeicherten Fingerabdruck lässt sich das ursprüngliche Wasserzeichen rekonstruieren und mit dem echten vergleichen. Die Autoren liefern zudem ein mathematisches Argument, warum die Betonung stabiler Merkmale und der Einsatz eines abstimmungsbasierten Klassifikators die Rekonstruktionsfehler gering halten sollten, selbst bei starken Angriffen.
Wie gut die Methode standhält
Zur Prüfung wendeten die Forscher das System auf 100 Musikclips aus verschiedenen Genres sowie auf zusätzliche Sprach- und Umgebungsgeräusche aus bekannten öffentlichen Datensätzen an. Anschließend setzten sie die wasserzeichenbehafteten Inhalte einer breiten Palette von Misshandlungen aus: Hintergrundrauschen, Hoch- und Tiefpassfilterung, MP3-Kompression, Resampling und Requantisierung, kleine Änderungen der Wiedergabegeschwindigkeit sowie Tonhöhenverschiebungen. Außerdem nutzten sie eine anspruchsvolle Testsuite namens Stirmark, die speziell dazu entwickelt wurde, Wasserzeichensysteme herauszufordern. Unter nahezu allen Bedingungen unterschieden sich die wiederhergestellten Wasserzeichen in weniger als vier Prozent der Bits von den Originalen, und die Ähnlichkeitswerte blieben sehr hoch, was bedeutet, dass das Muster des Wasserzeichens weitgehend erhalten blieb. Im Vergleich mit mehreren modernen Null-Wasserzeichen-Verfahren zeigte der neue Ansatz generell gleiche oder bessere Widerstandsfähigkeit, insbesondere bei schwierigen Zeit- und Tonhöhenmodifikationen, während der Audioinhalt weiterhin völlig sauber blieb.
Was das für alltägliches Audio bedeutet
Einfach gesagt zeigt diese Arbeit, dass es möglich ist, das Eigentum an einem Song oder einer Aufnahme nachzuweisen, ohne auch nur ein einziges Sample des zugrunde liegenden Klangs zu verändern. Durch die sorgfältige Kombination vieler Blickwinkel auf das Audiosignal und den Einsatz von maschinellem Lernen, um Verzerrungen zu durchdringen, erzeugt die Methode einen robusten Fingerabdruck, der gängige Verarbeitungen in der Praxis übersteht. Das macht sie zu einem vielversprechenden Werkzeug für Plattenfirmen, Streaming-Plattformen, Archive und alle Bereiche, in denen Audio unberührt bleiben, aber dennoch wirksam gegen Missbrauch geschützt werden muss.
Zitation: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Schlüsselwörter: Audio-Wasserzeichen, digitales Urheberrecht, maschinelles Lernen, Signalverarbeitung, Inhaltsschutz