Clear Sky Science · fr
Un schéma robuste de tatouage audio zéro basé sur des empreintes multi-caractéristiques et l’apprentissage automatique
Pourquoi les marques cachées dans le son comptent
Chaque jour, des chansons, des podcasts et des enregistrements sont copiés, diffusés et partagés sur Internet. Cet accès facilité est excellent pour les auditeurs, mais il complique la tâche des créateurs et des entreprises qui doivent prouver la propriété de leurs contenus audio sans altérer la qualité du son. L’article décrit ici présente une nouvelle manière de « marquer » l’audio afin de prouver la propriété, même après de lourds traitements, tout en laissant le son original parfaitement intact.
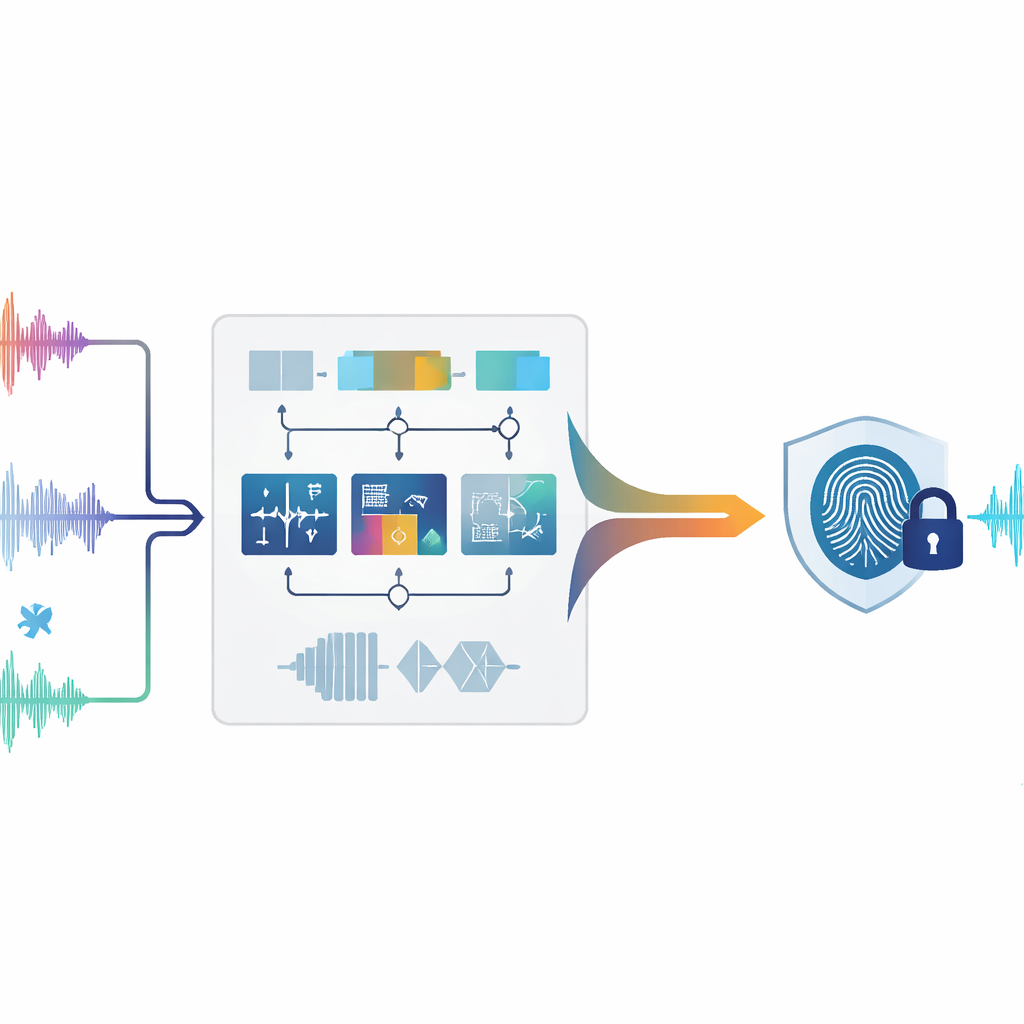
Protéger le son sans le toucher
Le tatouage numérique traditionnel fonctionne un peu comme un tampon discret apposé sur une image ou une chanson : des données supplémentaires sont ajoutées au fichier original. Avec l’audio, cependant, de minuscules modifications peuvent créer des artefacts audibles ou poser des problèmes juridiques, en particulier pour des enregistrements médico-légaux, médicaux ou d’archives qui doivent rester intacts. Le zéro-tatouage adopte une approche différente. Plutôt que d’altérer le son, il étudie des motifs uniques déjà présents dans l’audio et les utilise pour construire une « empreinte » qui est stockée séparément. En cas de litige, cette empreinte peut être comparée à un enregistrement suspect pour vérifier une correspondance — aucune modification du signal original n’est nécessaire.
Écouter l’audio sous plusieurs angles
Les auteurs proposent un système de zéro-tatouage qui analyse l’audio de plusieurs manières complémentaires simultanément. D’abord, le son est découpé en courts segments non chevauchants, ou trames. Pour chaque trame, le système mesure neuf caractéristiques différentes qui décrivent le comportement temporel du son, la répartition de son énergie entre graves et aigus, et la structure du signal lorsqu’on le considère comme un réseau d’échantillons corrélés. Certaines caractéristiques reflètent des changements rapides, comme des coups ou des attaques ; d’autres renseignent sur la répartition d’énergie dans le spectre ou sur l’étendue des fréquences ; d’autres encore résument la forme globale du signal via des transformées mathématiques. Ensemble, ces mesures dressent un portrait riche de chaque instant de l’audio.
Des mesures riches à une empreinte stable
Tous les aspects d’un son ne résistent pas de la même manière à des traitements agressifs. La compression, le filtrage, le rééchantillonnage, ainsi que des variations de vitesse ou de hauteur peuvent déformer certaines caractéristiques tout en en laissant d’autres presque intactes. Pour s’en accommoder, la méthode évalue le comportement de chacune des neuf caractéristiques face à de nombreuses attaques simulées. Les caractéristiques qui restent stables reçoivent une importance plus grande, tandis que celles qui fluctuent sont atténuées. Pour chaque trame, les caractéristiques pondérées sont fusionnées en une seule valeur composite. Une comparaison glissante par rapport aux trames voisines transforme ensuite cette courbe continue en une séquence de zéros et de uns, un peu comme convertir un motif sonore en code-barres. Cette séquence binaire est ensuite combinée avec le tatouage souhaité (par exemple, une petite image de logo convertie en bits), produisant l’empreinte audio finale liée de façon unique à ce contenu.

Apprendre à une machine à lire à travers le bruit
Le défi principal est de récupérer la même empreinte après qu’un enregistrement a subi des attaques — par exemple, ajout de bruit, compression MP3 ou modification légère de la vitesse. Pour résoudre cela, les auteurs entraînent un modèle d’apprentissage automatique appelé forêt aléatoire (Random Forest). Pendant l’entraînement, le système voit de nombreux exemples des mêmes trames audio à la fois dans leur forme originale et après différentes distorsions, avec l’étiquette binaire correcte pour chaque trame. La forêt apprend quelles combinaisons de caractéristiques temporelles, fréquentielles et structurelles correspondent à un 0 ou à un 1. Plus tard, lorsqu’un enregistrement suspect est analysé, ses trames sont traitées de la même façon et la forêt entraînée prédit la séquence binaire. En combinant cette séquence prédite avec l’empreinte stockée, le tatouage d’origine peut être reconstruit et comparé à l’original. Les auteurs fournissent également un argument mathématique expliquant pourquoi mettre l’accent sur les caractéristiques stables et utiliser un classifieur par vote devrait maintenir les erreurs de reconstruction faibles, même sous des attaques sévères.
La résistance de la méthode
Pour tester le système, les chercheurs l’ont appliqué à 100 extraits musicaux de genres variés ainsi qu’à des échantillons de parole et de sons d’environnement provenant de jeux de données publics bien connus. Ils ont ensuite soumis le contenu tatoué à une large gamme d’altérations : ajout de bruit de fond, filtrages passe-haut et passe-bas, compression MP3, rééchantillonnage et requantification, petits changements de vitesse de lecture et décalages de hauteur. Ils ont aussi utilisé une suite de tests exigeante appelée Stirmark, conçue spécialement pour mettre au défi les schémas de tatouage. Dans presque toutes les conditions, les tatouages récupérés différaient des originaux de moins de quatre pour cent de bits, et les scores de similitude restaient très élevés, ce qui signifie que la structure du tatouage était en grande partie préservée. Comparée à plusieurs méthodes zéro-tatouage à la pointe, la nouvelle approche montrait généralement une résistance égale ou supérieure, notamment face à des modifications délicates de temps et de hauteur, tout en laissant l’audio parfaitement propre.
Ce que cela signifie pour l’audio de tous les jours
En termes simples, ce travail montre qu’il est possible de prouver la propriété d’une chanson ou d’un enregistrement sans modifier un seul échantillon du son sous-jacent. En combinant soigneusement de multiples points de vue sur le signal audio et en utilisant l’apprentissage automatique pour extraire l’information malgré les distorsions, la méthode produit une empreinte robuste qui survit aux traitements courants du monde réel. Cela en fait un outil prometteur pour les maisons de disques, les plateformes de streaming, les archives et tout contexte où l’audio doit rester intact tout en étant fortement protégé contre les usages abusifs.
Citation: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Mots-clés: tatouage audio, droits d’auteur numériques, apprentissage automatique, traitement du signal, protection du contenu