Clear Sky Science · en
A robust audio zero watermarking scheme using multi feature fingerprints and machine learning
Why Hidden Marks in Sound Matter
Every day, songs, podcasts, and recordings are copied, streamed, and shared across the internet. This easy access is great for listeners, but it makes it hard for creators and companies to prove ownership of their audio without damaging the sound itself. The paper described here introduces a new way to “mark” audio so that ownership can be proven, even after heavy processing, while keeping the original sound perfectly untouched.
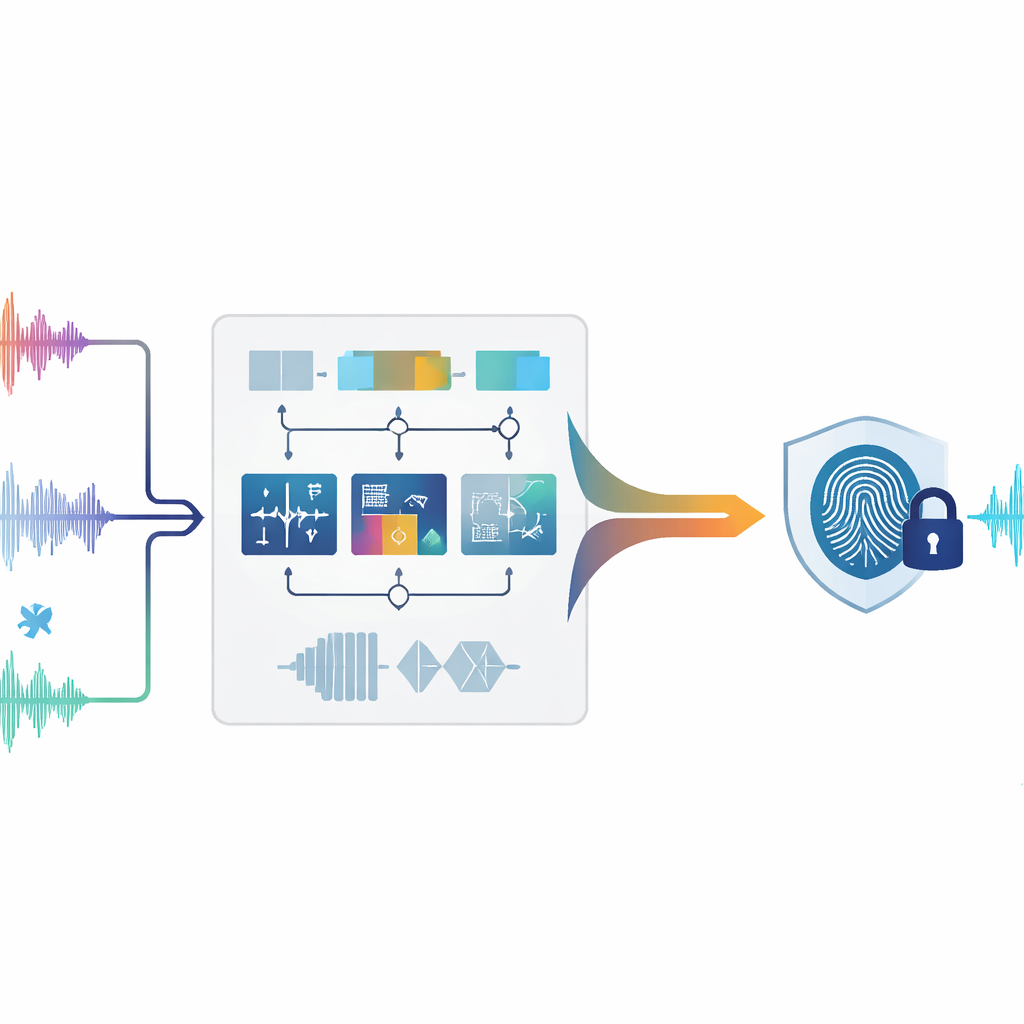
Protecting Sound Without Touching It
Traditional digital watermarking works a bit like a faint stamp pressed into a picture or a song: extra data are added to the original file. With audio, however, even tiny changes can create audible artifacts or raise legal concerns, especially for forensic, medical, or archival recordings that must remain pristine. Zero-watermarking takes a different route. Instead of altering the sound, it studies unique patterns already present in the audio and uses them to build a “fingerprint” that is stored elsewhere. During a dispute, this fingerprint can be compared with a suspect recording to check if they match—no edits to the original signal are ever needed.
Listening to Audio From Many Angles
The authors propose a zero-watermarking system that listens to audio in several complementary ways at once. First, the sound is chopped into short, non-overlapping pieces, or frames. For each frame, the system measures nine different features that describe how the sound behaves over time, how its energy is spread across low and high tones, and how its structure looks when treated as a network of related samples. Some features reflect quick changes, like sudden beats or onsets; others capture where most of the energy lies in the spectrum or how wide the range of frequencies is; still others distill the overall shape of the signal in mathematical transforms. Together, these measurements paint a rich portrait of each moment in the audio.
From Rich Measurements to a Stable Fingerprint
Not all aspects of a sound survive heavy processing equally well. Compression, filtering, re-sampling, and time or pitch changes may distort some features but leave others almost untouched. To cope with this, the method evaluates how each of the nine features behaves under many different simulated attacks. Features that stay stable receive higher importance, while those that fluctuate get downplayed. For every frame, the weighted features are blended into a single composite value. A sliding comparison against neighboring frames then turns this continuous trace into a sequence of zeros and ones, much like turning a sound pattern into a barcode. This binary sequence is then combined with the desired watermark (for example, a small logo image converted into bits), producing the final audio fingerprint tied uniquely to that piece of content.

Teaching a Machine to Read Through the Noise
The core challenge is to recover the same fingerprint after the audio has been attacked—for example, by adding noise, compressing it to MP3, or slightly changing its speed. To solve this, the authors train a machine-learning model called a Random Forest. During training, the system sees many examples of the same audio frames both in their original form and after different distortions, along with the correct binary “label” for each frame. The Random Forest learns which blends of time, frequency, and structural features correspond to a 0 or a 1. Later, when a suspect recording is analyzed, its frames are processed in the same way, and the trained forest predicts the binary sequence. By combining this predicted sequence with the stored fingerprint, the original watermark can be reconstructed and compared to the true one. The authors also provide a mathematical argument showing why emphasizing stable features and using a voting-based classifier should keep reconstruction errors low, even under strong attacks.
How Well the Method Holds Up
To test the system, the researchers applied it to 100 music clips from several genres and to additional speech and environmental sounds from well-known public datasets. They then subjected the watermarked content to a broad range of abuses: added background noise, high- and low-pass filtering, MP3 compression, re-sampling and re-quantization, small changes in playback speed, and pitch shifts. They also used a demanding test suite called Stirmark, designed specifically to challenge watermarking schemes. Across nearly all conditions, the recovered watermarks differed from the originals in less than four percent of bits, and the similarity scores remained very high, meaning the pattern of the watermark was largely preserved. When compared with several state-of-the-art zero-watermarking methods, the new approach generally showed equal or better resilience, particularly under tricky time and pitch modifications, while still leaving the audio perfectly clean.
What This Means for Everyday Audio
In plain terms, this work shows that it is possible to prove ownership of a song or recording without changing a single sample of the underlying sound. By carefully combining many viewpoints on the audio signal and using machine learning to read through distortions, the method produces a robust fingerprint that survives common real-world processing. This makes it a promising tool for music labels, streaming platforms, archives, and any setting where audio must remain untouched but still be strongly protected against misuse.
Citation: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Keywords: audio watermarking, digital copyright, machine learning, signal processing, content protection