Clear Sky Science · pl
Odporny schemat zerowego znakowania wodnego dźwięku z użyciem wieloczynnikowych odcisków palców i uczenia maszynowego
Dlaczego ukryte znaki w dźwięku mają znaczenie
Codziennie piosenki, podcasty i nagrania są kopiowane, przesyłane strumieniowo i udostępniane w internecie. Taki łatwy dostęp jest świetny dla słuchaczy, ale utrudnia twórcom i firmom udowodnienie własności audio bez naruszania jakości dźwięku. Opisany tu artykuł przedstawia nowy sposób „oznaczania” materiałów dźwiękowych, który pozwala udowodnić własność nawet po silnym przetworzeniu, przy jednoczesnym zachowaniu oryginalnego brzmienia w nienaruszonym stanie.
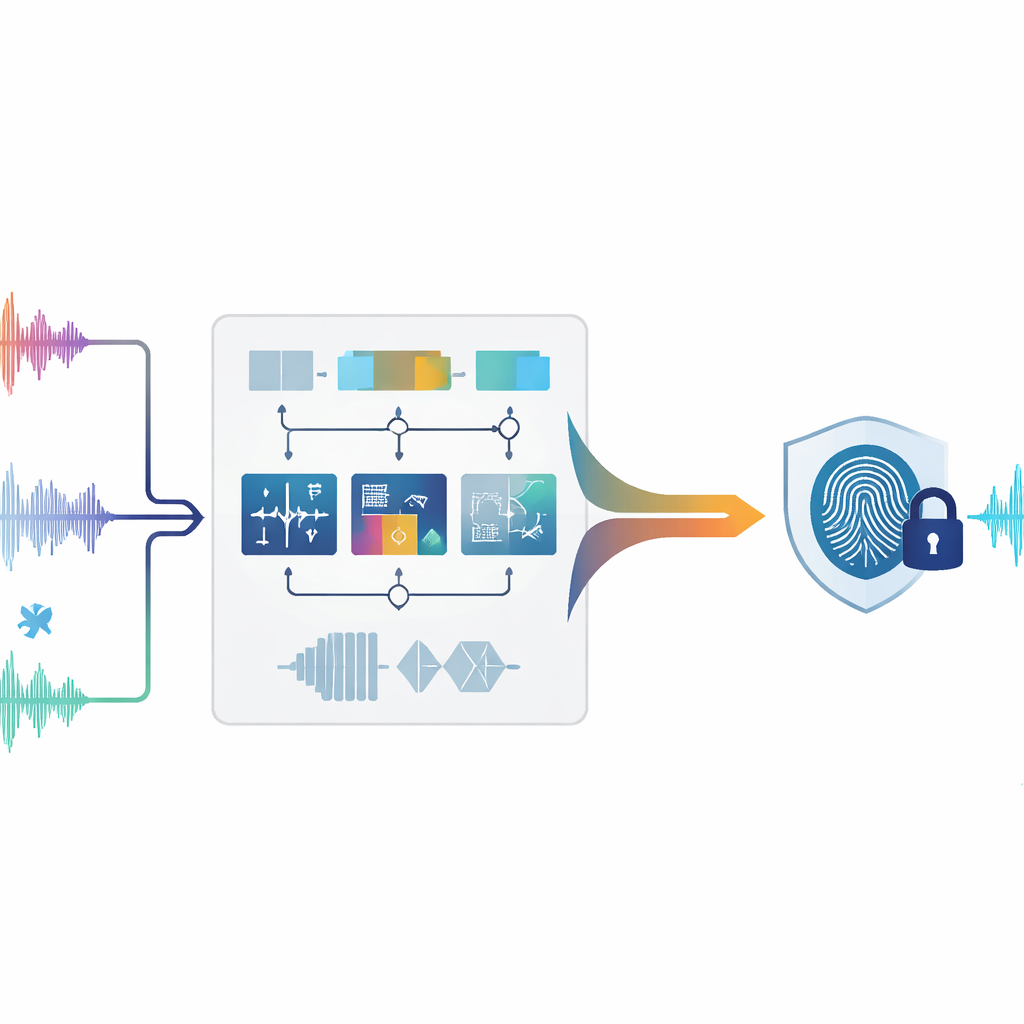
Ochrona dźwięku bez jego modyfikowania
Tradycyjne cyfrowe znakowanie wodne działa trochę jak delikatna pieczęć wciśnięta w obrazek lub utwór: do oryginalnego pliku dodawane są dodatkowe dane. W przypadku audio nawet niewielkie zmiany mogą wprowadzić słyszalne artefakty lub rodzić wątpliwości prawne, szczególnie w materiałach sądowych, medycznych czy archiwalnych, które muszą pozostać nienaruszone. Zerowe znakowanie wodne idzie inną drogą. Zamiast modyfikować dźwięk, bada unikatowe wzorce już obecne w nagraniu i wykorzystuje je do zbudowania „odcisku palca”, który jest przechowywany osobno. W razie sporu ten odcisk można porównać z podejrzanym nagraniem, aby sprawdzić, czy pasują — oryginalny sygnał nigdy nie musi być edytowany.
Słuchając dźwięku z wielu perspektyw
Autorzy proponują system zerowego znakowania wodnego, który analizuje dźwięk na kilka komplementarnych sposobów jednocześnie. Najpierw sygnał jest dzielony na krótkie, niepokrywające się fragmenty, zwane klatkami. Dla każdej klatki system mierzy dziewięć różnych cech opisujących zachowanie dźwięku w czasie, rozkład energii między tonami niskimi i wysokimi oraz strukturę sygnału traktowaną jako sieć powiązanych próbek. Niektóre cechy odzwierciedlają szybkie zmiany, takie jak nagłe uderzenia czy początki dźwięków; inne określają, gdzie skoncentrowana jest większość energii w spektrum lub jak szeroki jest zakres częstotliwości; kolejne sprowadzają ogólny kształt sygnału w postaci transformacji matematycznych. Razem te pomiary tworzą bogaty portret każdego momentu w nagraniu.
Od bogatych pomiarów do stabilnego odcisku palca
Nie wszystkie cechy dźwięku przetrwają intensywne przetwarzanie równie dobrze. Kompresja, filtrowanie, ponowne próbkowanie oraz zmiany czasu lub wysokości tonu mogą zniekształcać jedne cechy, pozostawiając inne niemal nienaruszone. Aby sobie z tym poradzić, metoda ocenia, jak każda z dziewięciu cech zachowuje się pod wieloma symulowanymi atakami. Cechy, które pozostają stabilne, otrzymują większą wagę, natomiast te niestabilne są deprecjonowane. Dla każdej klatki ważone cechy są łączone w jedną składową wartość. Następnie porównanie przesuwne względem sąsiednich klatek przekształca tę ciągłą krzywą w sekwencję zer i jedynek, podobnie jak przekształcenie wzorca dźwiękowego w kod kreskowy. Ta binarna sekwencja jest potem łączona z żądanym znakiem wodnym (na przykład małym obrazkiem logo skonwertowanym na bity), tworząc ostateczny odcisk palca audio unikatowo powiązany z danym materiałem.

Nauczanie maszyny czytania przez szumy
Głównym wyzwaniem jest odzyskanie tego samego odcisku palca po tym, jak nagranie zostało zaatakowane — na przykład przez dodanie szumu, kompresję do MP3 lub nieznaczną zmianę prędkości odtwarzania. W celu rozwiązania tego problemu autorzy trenują model uczenia maszynowego zwany Random Forest. Podczas treningu system widzi wiele przykładów tych samych klatek audio zarówno w formie oryginalnej, jak i po różnych zniekształceniach, wraz z prawidłową binarną etykietą dla każdej klatki. Las losowy uczy się, które kombinacje cech czasowych, częstotliwościowych i strukturalnych odpowiadają zeru lub jedynce. Później, gdy analizowane jest podejrzane nagranie, jego klatki są przetwarzane w ten sam sposób, a wytrenowany model przewiduje sekwencję binarną. Łącząc tę przewidzianą sekwencję z przechowywanym odciskiem, można zrekonstruować oryginalny znak wodny i porównać go z prawdziwym. Autorzy przedstawiają też argument matematyczny wyjaśniający, dlaczego podkreślanie stabilnych cech i użycie klasyfikatora opartego na głosowaniu powinno utrzymać błędy rekonstrukcji na niskim poziomie, nawet przy silnych atakach.
Jak dobrze metoda się sprawdza
Aby przetestować system, badacze zastosowali go do 100 fragmentów muzycznych z różnych gatunków oraz do dodatkowych nagrań mowy i dźwięków środowiskowych z dobrze znanych publicznych zestawów danych. Następnie poddali oznakowane materiały szerokiemu spektrum nadużyć: dodaniu szumu tła, filtrom górno- i dolnoprzepustowym, kompresji MP3, ponownemu próbkowaniu i rekwantyzacji, niewielkim zmianom prędkości odtwarzania oraz przesunięciom wysokości dźwięku. Użyto także wymagającego pakietu testowego Stirmark, zaprojektowanego specjalnie do sprawdzania odporności schematów znakowania wodnego. W niemal wszystkich warunkach odzyskane znaki wodne różniły się od oryginałów w mniej niż czterech procentach bitów, a wskaźniki podobieństwa pozostały bardzo wysokie, co oznacza, że wzorzec znaku wodnego został w dużej mierze zachowany. W porównaniu z kilkoma nowoczesnymi metodami zerowego znakowania wodnego nowe podejście generalnie wykazywało równą lub lepszą odporność, szczególnie przy trudnych modyfikacjach czasu i tonu, przy jednoczesnym pozostawieniu dźwięku w nienaruszonym stanie.
Co to oznacza dla codziennego audio
Mówiąc prosto, praca ta pokazuje, że możliwe jest udowodnienie własności piosenki lub nagrania bez zmieniania choćby jednej próbki oryginalnego dźwięku. Poprzez ostrożne łączenie wielu punktów widzenia na sygnał audio i użycie uczenia maszynowego do odczytywania przez zniekształcenia, metoda generuje odporny odcisk palca, który przetrwa powszechne przetwarzanie w rzeczywistych warunkach. Czyni to rozwiązanie obiecującym narzędziem dla wytwórni muzycznych, platform streamingowych, archiwów i wszędzie tam, gdzie dźwięk musi pozostać nietknięty, a jednocześnie być skutecznie chroniony przed nadużyciami.
Cytowanie: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Słowa kluczowe: znakowanie wodne audio, cyfrowe prawa autorskie, uczenie maszynowe, przetwarzanie sygnałów, ochrona treści