Clear Sky Science · pt
Um esquema robusto de marca d’água zero em áudio usando múltiplas impressões digitais de características e aprendizado de máquina
Por que marcas ocultas em áudio importam
Todos os dias, canções, podcasts e gravações são copiados, transmitidos e compartilhados pela internet. Esse acesso fácil é ótimo para os ouvintes, mas torna difícil para criadores e empresas comprovarem a propriedade de seus áudios sem alterar o som. O trabalho descrito aqui apresenta uma nova maneira de “marcar” o áudio para que a autoria possa ser provada mesmo após processamento intenso, mantendo o som original perfeitamente intacto.
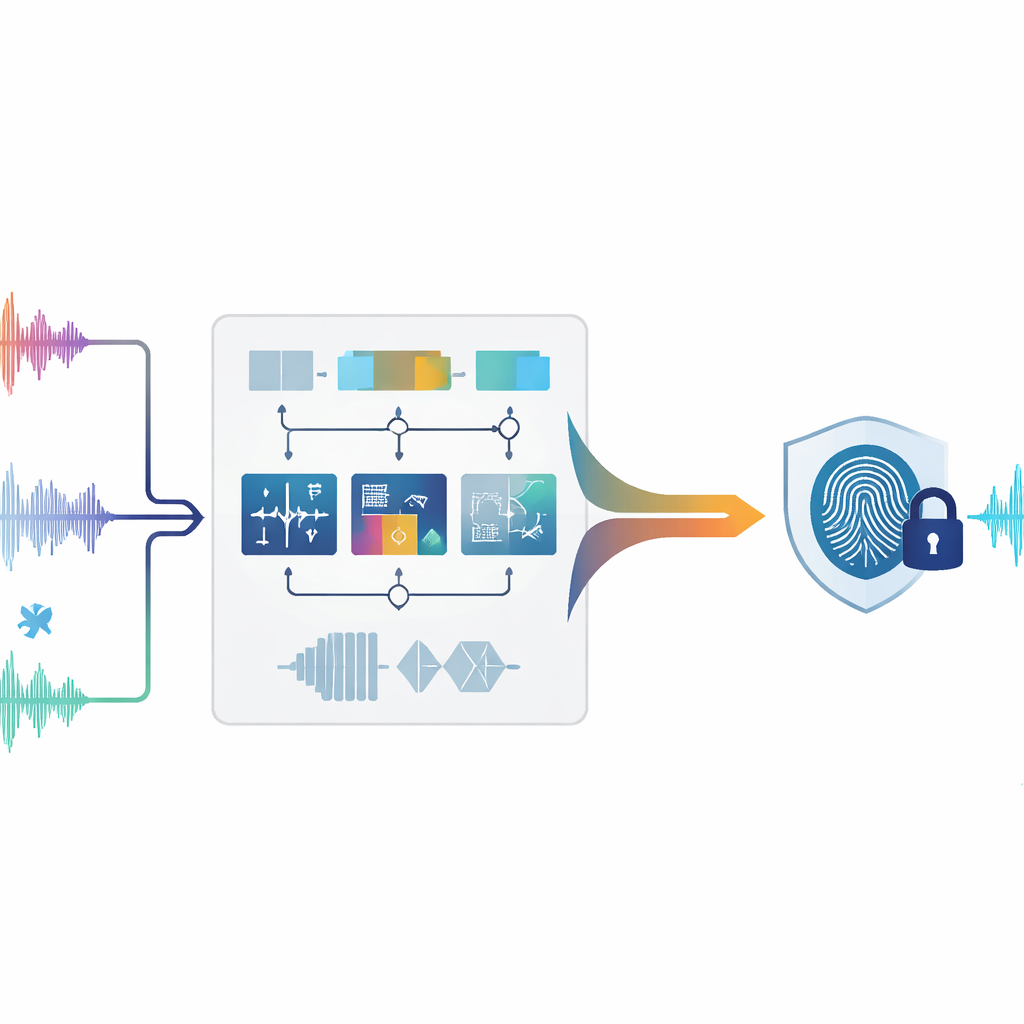
Proteger o som sem tocá‑lo
Marcação digital tradicional funciona um pouco como um selo sutil pressionado em uma imagem ou numa música: dados extras são adicionados ao arquivo original. No áudio, porém, até pequenas alterações podem gerar artefatos audíveis ou questões legais, especialmente em gravações forenses, médicas ou arquivísticas que precisam permanecer imaculadas. A marca d’água zero segue outro caminho. Em vez de alterar o som, ela estuda padrões únicos já presentes no áudio e os usa para construir uma “impressão digital” que é armazenada em outro lugar. Em uma disputa, essa impressão pode ser comparada com uma gravação suspeita para verificar correspondência — nenhuma edição do sinal original é necessária.
Ouvindo o áudio por múltiplos ângulos
Os autores propõem um sistema de marca d’água zero que analisa o áudio de várias maneiras complementares ao mesmo tempo. Primeiro, o som é dividido em pequenos trechos não sobrepostos, ou quadros. Para cada quadro, o sistema mede nove características diferentes que descrevem como o som se comporta ao longo do tempo, como sua energia se distribui entre tons graves e agudos, e como sua estrutura aparece quando tratada como uma rede de amostras relacionadas. Algumas características refletem mudanças rápidas, como batidas ou ataques; outras capturam onde está concentrada a maior parte da energia no espectro ou quão ampla é a faixa de frequências; outras ainda destilam a forma geral do sinal em transformadas matemáticas. Em conjunto, essas medidas pintam um retrato rico de cada momento do áudio.
De medidas ricas a uma impressão digital estável
Nem todos os aspectos de um som sobrevivem igualmente bem a processamentos pesados. Compressão, filtragem, reamostragem e alterações de tempo ou tom podem distorcer algumas características e deixar outras quase intactas. Para lidar com isso, o método avalia como cada uma das nove características se comporta sob muitas simulações de ataques diferentes. Características que permanecem estáveis recebem maior importância, enquanto as que flutuam são rebaixadas. Para cada quadro, as características ponderadas são combinadas em um único valor composto. Uma comparação deslizante com quadros vizinhos transforma esse traço contínuo em uma sequência de zeros e uns, como transformar um padrão sonoro em um código de barras. Essa sequência binária é então combinada com a marca d’água desejada (por exemplo, uma pequena imagem de logotipo convertida em bits), produzindo a impressão digital final do áudio ligada de forma única àquele conteúdo.

Treinando uma máquina para ler através do ruído
O desafio central é recuperar a mesma impressão após o áudio ter sido atacado — por exemplo, adicionando ruído, comprimindo em MP3 ou alterando ligeiramente a velocidade. Para resolver isso, os autores treinam um modelo de aprendizado de máquina chamado Random Forest. Durante o treinamento, o sistema vê muitos exemplos dos mesmos quadros de áudio tanto na forma original quanto após diversas distorções, junto com o rótulo binário correto para cada quadro. A Random Forest aprende quais combinações de características temporais, espectrais e estruturais correspondem a 0 ou 1. Depois, quando uma gravação suspeita é analisada, seus quadros são processados da mesma forma e a floresta treinada prevê a sequência binária. Ao combinar essa sequência prevista com a impressão armazenada, a marca d’água original pode ser reconstruída e comparada com a verdadeira. Os autores também fornecem um argumento matemático mostrando por que enfatizar características estáveis e usar um classificador por votação tende a manter os erros de reconstrução baixos, mesmo sob ataques fortes.
Quão bem o método resiste
Para testar o sistema, os pesquisadores aplicaram‑no a 100 trechos musicais de vários gêneros e a gravações adicionais de voz e sons ambientais de conjuntos de dados públicos conhecidos. Em seguida, submeteram o conteúdo marcado a uma ampla gama de abusos: ruído de fundo adicionado, filtragem passa‑alto e passa‑baixo, compressão MP3, reamostragem e requantização, pequenas mudanças na velocidade de reprodução e alterações de pitch. Também usaram uma bateria de testes exigente chamada Stirmark, projetada especificamente para desafiar esquemas de marca d’água. Em quase todas as condições, as marcas recuperadas diferiram das originais em menos de quatro por cento dos bits, e as pontuações de similaridade permaneceram muito altas, indicando que o padrão da marca foi amplamente preservado. Em comparação com vários métodos de marca d’água zero de ponta, a nova abordagem mostrou, em geral, resistência igual ou superior, particularmente sob modificações de tempo e pitch difíceis, enquanto ainda deixava o áudio perfeitamente limpo.
O que isso significa para o áudio do dia a dia
Em termos simples, este trabalho mostra que é possível provar a propriedade de uma canção ou gravação sem alterar um único ponto do som subjacente. Ao combinar cuidadosamente múltiplas perspectivas sobre o sinal de áudio e usar aprendizado de máquina para interpretar distorções, o método produz uma impressão digital robusta que sobrevive a processamentos comuns do mundo real. Isso o torna uma ferramenta promissora para gravadoras, plataformas de streaming, arquivos e qualquer cenário em que o áudio precise permanecer intacto mas ainda assim ser fortemente protegido contra uso indevido.
Citação: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Palavras-chave: marcação de áudio, direitos autorais digitais, aprendizado de máquina, processamento de sinais, proteção de conteúdo