Clear Sky Science · nl
Een robuust audio zero-watermarking schema met multi-feature vingerafdrukken en machine learning
Waarom verborgen tekens in geluid ertoe doen
Elke dag worden liedjes, podcasts en opnamen gekopieerd, gestreamd en gedeeld over het internet. Deze gemakkelijke toegang is fijn voor luisteraars, maar maakt het moeilijk voor makers en bedrijven om eigendom van hun audio te bewijzen zonder het geluid zelf aan te tasten. Het hier beschreven artikel introduceert een nieuwe manier om audio te "markeren" zodat eigendom aangetoond kan worden, zelfs na zware bewerkingen, terwijl het oorspronkelijke geluid volledig ongewijzigd blijft.
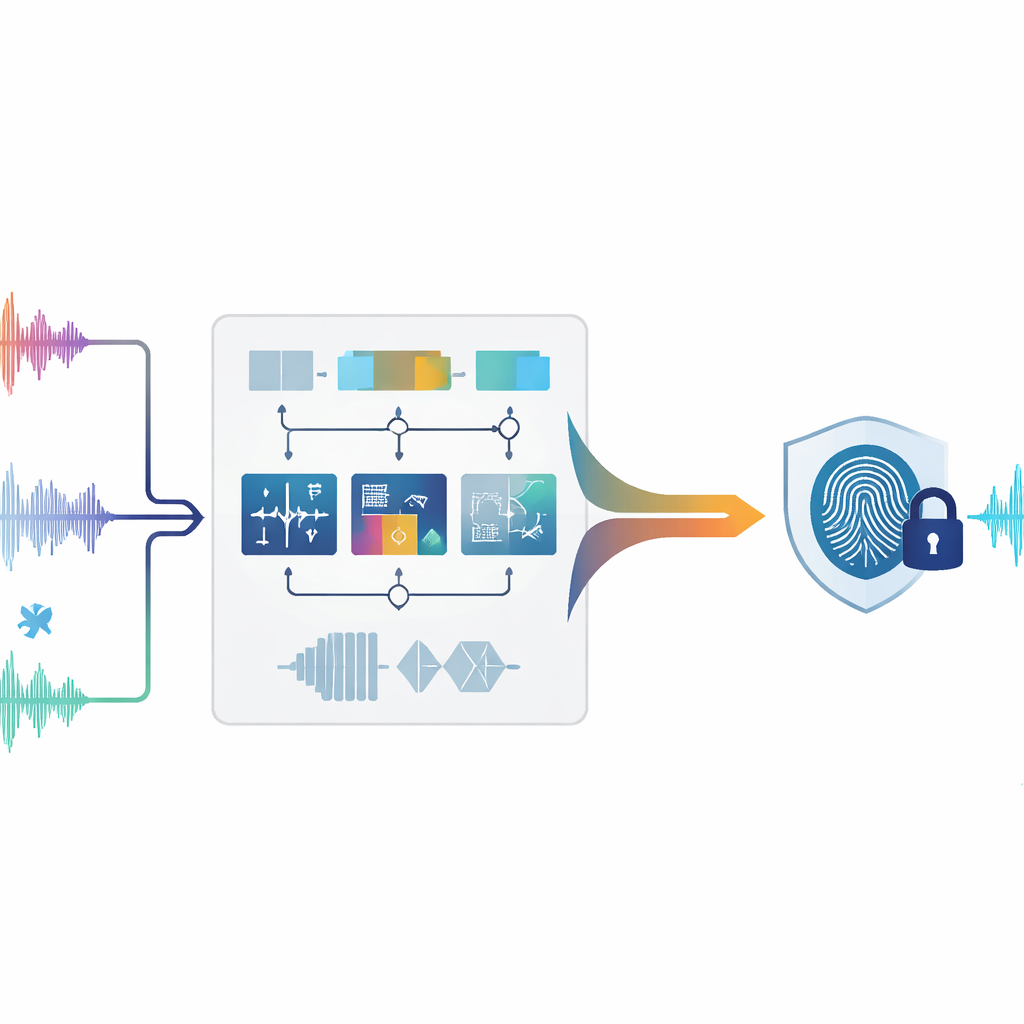
Geluid beschermen zonder het aan te raken
Traditionele digitale watermarking werkt een beetje als een zwak stempel in een afbeelding of een lied: er worden extra data aan het originele bestand toegevoegd. Bij audio kunnen zelfs kleine wijzigingen hoorbare artefacten veroorzaken of juridische zorgen oproepen, vooral bij forensische, medische of archiefopnamen die vlekkeloos moeten blijven. Zero-watermarking kiest een andere route. In plaats van het geluid te wijzigen, bestudeert het unieke patronen die al in de audio aanwezig zijn en gebruikt die om een "vingerafdruk" te bouwen die elders wordt opgeslagen. Tijdens een geschil kan deze vingerafdruk vergeleken worden met een verdachte opname om te controleren of ze overeenkomen—er zijn nooit bewerkingen aan het oorspronkelijke signaal nodig.
Audio vanuit meerdere invalshoeken beluisteren
De auteurs stellen een zero-watermarkingsysteem voor dat audio op meerdere complementaire manieren tegelijk beluistert. Eerst wordt het geluid in korte, niet-overlappende stukjes of frames gesneden. Voor elk frame meet het systeem negen verschillende kenmerken die beschrijven hoe het geluid zich in de tijd gedraagt, hoe de energie over lage en hoge tonen verdeeld is, en hoe de structuur eruitziet wanneer deze als een netwerk van gerelateerde samples wordt behandeld. Sommige kenmerken weerspiegelen snelle veranderingen, zoals plotselinge beats of onsets; andere vangen waar het merendeel van de energie in het spectrum ligt of hoe breed het frequentiebereik is; weer andere destilleren de algemene vorm van het signaal met behulp van wiskundige transformaties. Samen geven deze metingen een rijk portret van elk moment in de audio.
Van rijke metingen naar een stabiele vingerafdruk
Niet alle aspecten van een geluid overleven zware bewerkingen even goed. Compressie, filtering, hersampling en veranderingen in tijd of toonhoogte kunnen sommige kenmerken vervormen maar andere vrijwel onaangetast laten. Om hiermee om te gaan evalueert de methode hoe elk van de negen kenmerken zich gedraagt onder vele gesimuleerde aanvallen. Kenmerken die stabiel blijven krijgen meer gewicht, terwijl fluctuerende kenmerken worden teruggeschroefd. Voor elk frame worden de gewogen kenmerken samengevoegd tot één samengesteld waarde. Een schuivende vergelijking met naburige frames zet deze continue trace vervolgens om in een reeks nullen en enen, vergelijkbaar met het omzetten van een geluidspatroon in een streepjescode. Deze binaire reeks wordt daarna gecombineerd met de gewenste watermark (bijvoorbeeld een klein logo omgezet in bits), waardoor de uiteindelijke audio-vingerafdruk ontstaat die uniek aan dat stuk inhoud is gekoppeld.

Een machine leren door het lawaai heen te lezen
De kernuitdaging is om dezelfde vingerafdruk terug te winnen nadat de audio is aangevallen—bijvoorbeeld door ruis toe te voegen, te comprimeren naar MP3 of de snelheid licht te veranderen. Om dit op te lossen trainen de auteurs een machine-learningmodel genaamd Random Forest. Tijdens de training ziet het systeem veel voorbeelden van dezelfde audioframes zowel in hun originele vorm als na verschillende vervormingen, samen met het juiste binaire "label" voor elk frame. De Random Forest leert welke mengsels van tijd-, frequentie- en structurele kenmerken overeenkomen met een 0 of een 1. Later, wanneer een verdachte opname wordt geanalyseerd, worden de frames op dezelfde manier verwerkt en voorspelt het getrainde bos de binaire reeks. Door deze voorspelde reeks te combineren met de opgeslagen vingerafdruk kan de originele watermark worden gereconstrueerd en vergeleken met de echte. De auteurs geven ook een wiskundig argument waarom het benadrukken van stabiele kenmerken en het gebruik van een op stemmen gebaseerd classificatiesysteem reconstructiefouten laag zou moeten houden, zelfs onder sterke aanvallen.
Hoe goed de methode standhoudt
Om het systeem te testen pasten de onderzoekers het toe op 100 muziekfragmenten uit verschillende genres en op aanvullende spraak- en omgevingsgeluiden uit bekende openbare datasets. Ze onderwierpen de gemarkeerde inhoud vervolgens aan een breed scala aan misbruik: toegevoegde achtergrondruis, high- en low-pass filtering, MP3-compressie, hersampling en re-quantisatie, kleine veranderingen in afspeelsnelheid en toonhoogteverschuivingen. Ze gebruikten ook een veeleisende testset genaamd Stirmark, speciaal ontworpen om watermarking-schema's uit te dagen. In bijna alle omstandigheden verschilden de teruggewonnen watermarks minder dan vier procent van de bits van de originelen, en bleven de similariteitsscores zeer hoog, wat betekent dat het patroon van de watermark grotendeels behouden bleef. Vergeleken met meerdere state-of-the-art zero-watermarkingmethoden toonde de nieuwe aanpak over het algemeen gelijke of betere veerkracht, met name bij lastige tijd- en toonhoogte-aanpassingen, terwijl de audio nog steeds volledig onaangetast bleef.
Wat dit betekent voor alledaagse audio
Kort gezegd laat dit werk zien dat het mogelijk is eigendom van een nummer of opname aan te tonen zonder ook maar één sample van het onderliggende geluid te veranderen. Door zorgvuldig vele gezichtspunten op het audiosignaal te combineren en machine learning te gebruiken om door vervormingen heen te lezen, produceert de methode een robuuste vingerafdruk die gangbare bewerkingen in de echte wereld overleeft. Dit maakt het een veelbelovend hulpmiddel voor platenmaatschappijen, streamingplatforms, archieven en elke situatie waarin audio onaangeroerd moet blijven maar toch sterk beschermd moet zijn tegen misbruik.
Bronvermelding: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Trefwoorden: audio-watermarking, digitale auteursrechten, machine learning, signaalverwerking, contentbescherming