Clear Sky Science · it
Uno schema robusto di watermarking audio zero usando impronte multi-caratteristiche e apprendimento automatico
Perché i Marchi Nascosti nel Suono Contano
Ogni giorno canzoni, podcast e registrazioni vengono copiati, trasmessi e condivisi in rete. Questo facile accesso è ottimo per gli ascoltatori, ma rende difficile per creatori e aziende dimostrare la proprietà dei loro contenuti audio senza alterare il suono stesso. L'articolo descritto qui introduce un nuovo modo di “marcare” l'audio in modo che la proprietà possa essere provata, anche dopo pesanti elaborazioni, mantenendo intatto il suono originale.
Proteggere il Suono Senza Toccarlo
Il watermarking digitale tradizionale funziona un po' come un timbro tenue impresso su un'immagine o una canzone: vengono aggiunti dati al file originale. Con l'audio, però, anche piccole modifiche possono creare artefatti udibili o sollevare problemi legali, specialmente per registrazioni forensi, mediche o d'archivio che devono rimanere intatte. Lo zero-watermarking segue una strada diversa. Invece di alterare il suono, analizza pattern unici già presenti nell'audio e li usa per costruire un “impronta” che viene conservata altrove. In caso di controversia, questa impronta può essere confrontata con una registrazione sospetta per verificare se coincidono—non è mai necessario modificare il segnale originale.
Ascoltare l'Audio da Molti Angoli
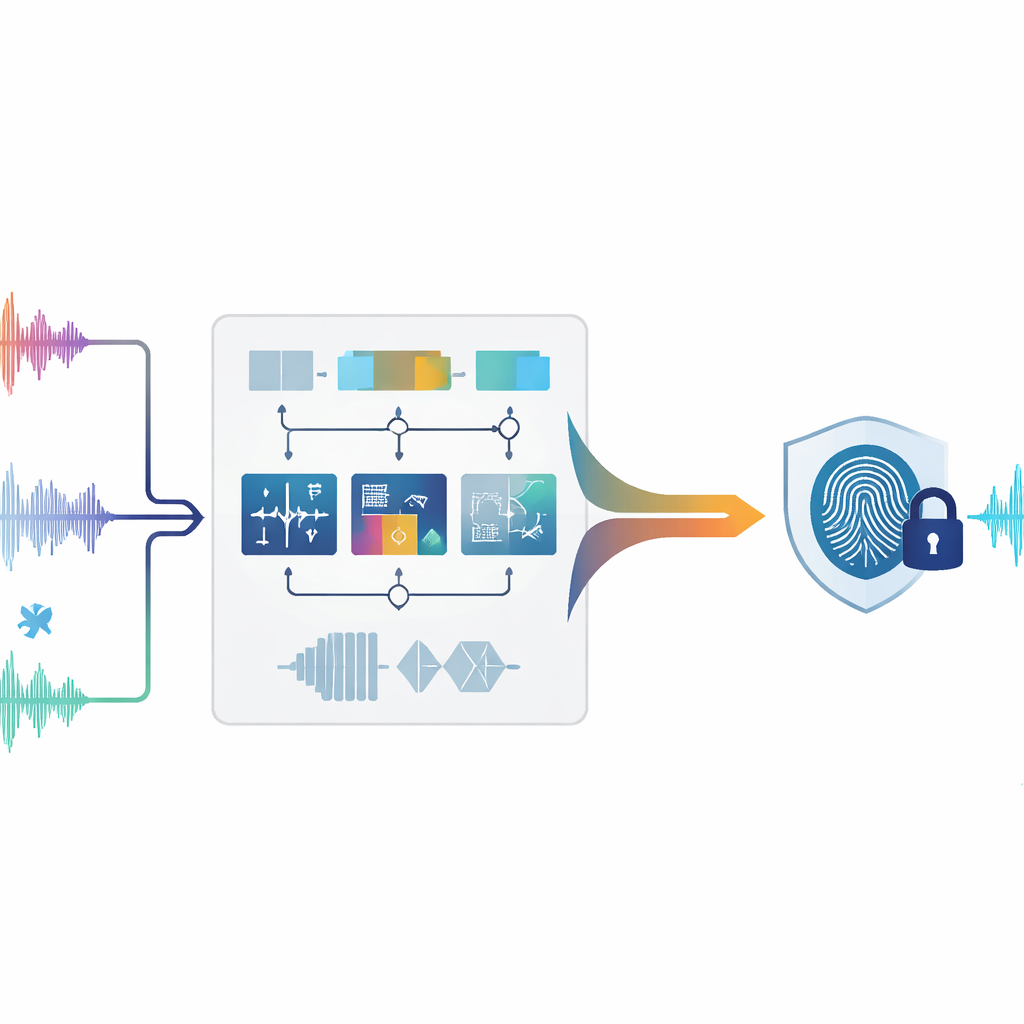
Gli autori propongono un sistema di zero-watermarking che analizza l'audio in diversi modi complementari contemporaneamente. Prima di tutto, il suono viene spezzettato in porzioni brevi e non sovrapposte, chiamate frame. Per ogni frame, il sistema misura nove diverse caratteristiche che descrivono come il suono si comporta nel tempo, come la sua energia è distribuita tra toni bassi e alti e come appare la sua struttura quando trattata come una rete di campioni correlati. Alcune caratteristiche riflettono cambiamenti rapidi, come battiti o onset; altre catturano dove si concentra la maggior parte dell'energia nello spettro o quanto è ampia la banda di frequenze; altre ancora distillano la forma complessiva del segnale tramite trasformate matematiche. Insieme, queste misure dipingono un ritratto ricco di ogni istante dell'audio.
Dalle Misurazioni Ricche a un'Impronta Stabile
Non tutti gli aspetti di un suono resistono allo stesso modo a elaborazioni pesanti. Compressione, filtraggio, cambi di campionamento e variazioni di tempo o tono possono distorcere alcune caratteristiche lasciandone altre quasi intatte. Per affrontare questo, il metodo valuta come ciascuna delle nove caratteristiche si comporta sotto molti diversi attacchi simulati. Le caratteristiche che restano stabili ricevono maggiore importanza, mentre quelle che fluttuano vengono attenuate. Per ogni frame, le caratteristiche pesate vengono unite in un unico valore composito. Un confronto scorrevole con i frame vicini trasforma quindi questa traccia continua in una sequenza di zeri e uni, un po' come convertire un motivo sonoro in un codice a barre. Questa sequenza binaria viene poi combinata con il watermark desiderato (per esempio, una piccola immagine logo convertita in bit), producendo l'impronta audio finale legata in modo univoco a quel contenuto.

Insegnare a una Macchina a Leggere Attraverso il Rumore
La sfida centrale è recuperare la stessa impronta dopo che l'audio è stato attaccato—per esempio aggiungendo rumore, comprimendolo in MP3 o cambiandone leggermente la velocità. Per risolvere questo, gli autori addestrano un modello di apprendimento automatico chiamato Random Forest. Durante l'addestramento, il sistema vede molti esempi degli stessi frame audio sia nella forma originale sia dopo diverse distorsioni, insieme alla corretta etichetta binaria per ogni frame. La Random Forest impara quali combinazioni di caratteristiche temporali, spettrali e strutturali corrispondono a uno 0 o a un 1. Successivamente, quando viene analizzata una registrazione sospetta, i suoi frame vengono processati allo stesso modo e la foresta addestrata predice la sequenza binaria. Combinando questa sequenza predetta con l'impronta memorizzata, il watermark originale può essere ricostruito e confrontato con quello vero. Gli autori forniscono anche un argomento matematico che spiega perché enfatizzare caratteristiche stabili e usare un classificatore a voto dovrebbe mantenere bassi gli errori di ricostruzione, anche sotto attacchi intensi.
Quanto Bene Regge il Metodo
Per testare il sistema, i ricercatori lo hanno applicato a 100 clip musicali di diversi generi e ad ulteriori suoni di parlato e ambientali provenienti da ben note banche dati pubbliche. Hanno poi sottoposto i contenuti watermarkati a un ampio ventaglio di abusi: rumore di fondo aggiunto, filtraggio passa-alto e passa-basso, compressione MP3, ricampionamento e richiesta, piccole variazioni di velocità di riproduzione e shift di pitch. Hanno inoltre utilizzato una suite di test impegnativa chiamata Stirmark, progettata specificamente per mettere alla prova gli schemi di watermarking. In quasi tutte le condizioni, i watermark recuperati differivano dagli originali in meno del quattro percento dei bit e i punteggi di somiglianza sono rimasti molto alti, il che significa che il motivo del watermark è stato in gran parte preservato. Confrontato con diversi metodi zero-watermarking all'avanguardia, il nuovo approccio ha mostrato generalmente una resistenza uguale o superiore, in particolare contro le complesse modifiche di tempo e pitch, lasciando comunque l'audio perfettamente pulito.
Cosa Significa per l'Audio di Tutti i Giorni
In termini semplici, questo lavoro dimostra che è possibile provare la proprietà di una canzone o di una registrazione senza modificare nemmeno un campione del suono. Combinando con cura molteplici punti di vista sul segnale audio e usando l'apprendimento automatico per leggere attraverso le distorsioni, il metodo produce un'impronta robusta che sopravvive alle comuni elaborazioni del mondo reale. Ciò lo rende uno strumento promettente per etichette musicali, piattaforme di streaming, archivi e qualsiasi contesto in cui l'audio deve rimanere intatto ma essere fortemente protetto da usi impropri.
Citazione: Khaleel, D.I., Mosleh, M., Al-nidawi, W.J.A. et al. A robust audio zero watermarking scheme using multi feature fingerprints and machine learning. Sci Rep 16, 13504 (2026). https://doi.org/10.1038/s41598-026-40419-4
Parole chiave: watermarking audio, diritti d'autore digitali, apprendimento automatico, elaborazione del segnale, protezione dei contenuti