Clear Sky Science · pt
Compressão de imagens baseada em deep learning para comunicações sem fio: impactos na robustez, taxa de transferência e latência
Por que a entrega inteligente de imagens pelo ar é importante
Todos os dias, telefones, carros, drones e pequenos sensores capturam imagens que precisam viajar sem fio — às vezes de ruas movimentadas, outras vezes de ambientes remotos ou hostis. Quando o enlace de rádio é fraco ou ruidoso, os formatos de imagem atuais podem travar, borrar ou falhar completamente, o que é perigoso para tarefas como direção autônoma ou monitoramento remoto. Este artigo explora como o deep learning moderno pode redesenhar a compressão de imagens para que as fotos cheguem mais rápido e de forma mais confiável, mesmo quando o canal sem fio é altamente imprevisível.
O gargalo sem fio para imagens
Formatos tradicionais como JPEG, WebP e padrões de vídeo como HEVC foram concebidos para enlaces estáveis, cabeados ou de alta qualidade. Eles comprimem imagens em menos bits, mas são frágeis: alguns bits invertidos no fluxo comprimido podem arruinar a imagem inteira, exigindo correção de erros pesada e retransmissões. Em canais sem fio reais, especialmente aqueles com desvanecimento acentuado e baixa relação sinal‑ruído (SNR), essa fragilidade se traduz em longos tempos de espera antes que qualquer imagem utilizável apareça. Ainda assim, muitas aplicações modernas — de câmeras IoT a veículos autônomos — precisam primeiro de uma visão rápida, ainda que grosseira, da cena, e só depois de refinamentos conforme o enlace permitir.
Imagens progressivas que se adaptam ao ar
Os autores constroem um pipeline adaptativo e progressivo de transmissão em torno de dois dos principais compressores de imagem por deep learning: um modelo “hyperprior” e um modelo VQGAN. Em vez de enviar um fluxo de bits rígido por imagem, esses sistemas quebram a representação comprimida em pedaços ordenados. Os pedaços mais importantes vão primeiro e já permitem uma reconstrução grosseira; pedaços posteriores adicionam detalhes quando o canal melhora ou mais largura de banda fica disponível. O modelo hyperprior representa a imagem como mapas de características compactos cuja contribuição para a qualidade é ranqueada por importância. O modelo VQGAN representa a imagem usando entradas de um codebook; envia primeiro codewords grosseiros e depois refinamentos residuais em estágios. Em ambos os casos, o transmissor consulta o estado atual do canal e escolhe quantos pedaços pode enviar com segurança naquele intervalo de tempo.
Testes em condições sem fio adversas
Para avaliar essas ideias, o estudo simula a transmissão de imagens por um canal com desvanecimento Rayleigh, um modelo padrão no qual a intensidade do sinal sobe e desce de forma imprevisível. Usando o conjunto Kodak de imagens de teste de alta qualidade, os autores comparam seus modelos progressivos hyperprior e VQGAN progressivo contra uma linha de base adaptativa WebP que também ajusta seu nível de compressão ao canal. Crucialmente, eles medem não apenas a qualidade da imagem, mas também a taxa de transferência (quantos pixels por segundo são entregues) e o tempo de espera — o atraso até que uma imagem seja recebida com sucesso. Esse tempo de espera é frequentemente ignorado em trabalhos de comunicação por deep learning, mas domina a experiência do usuário em aplicações sensíveis a atraso.
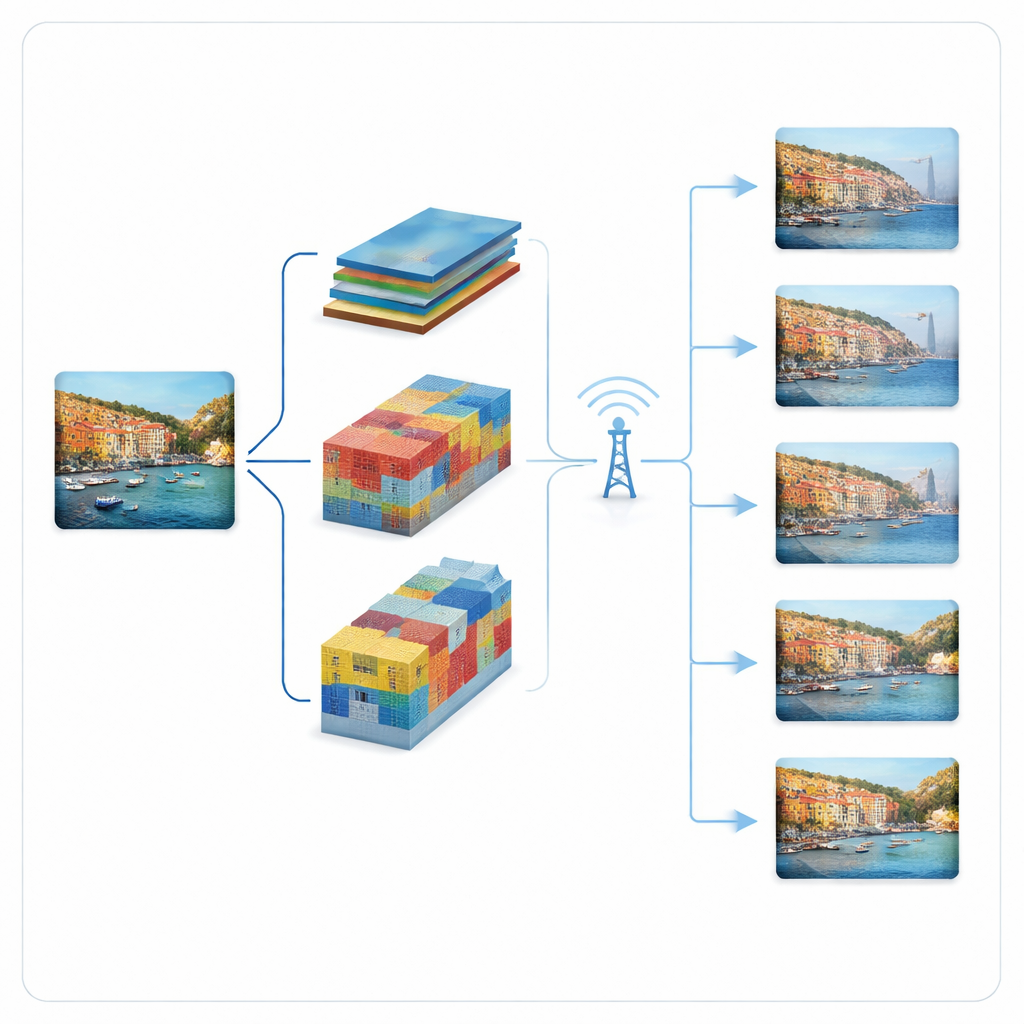
Velocidade versus robustez: o que vence onde
Os resultados mostram que, em condições muito ruidosas, o WebP adaptativo padrão essencialmente desiste: o canal não consegue suportar nem mesmo sua configuração de qualidade mais baixa, então nenhuma imagem completa é entregue. Em contraste, ambos os modelos aprendidos progressivos ainda fornecem imagens visualizáveis, porque podem recorrer ao envio apenas de uma camada base mínima. Entre eles, o modelo hyperprior progressivo alcança a menor latência e a maior taxa de transferência na maioria das configurações de baixa SNR, graças aos seus mapas de características muito compactos e finamente ordenados. Isso o torna especialmente atraente quando a resposta rápida é vital, como em sistemas de visão interativos. O VQGAN progressivo, embora ligeiramente menos eficiente, oferece maior qualidade visual nas condições mais adversas e pode tolerar erros de bit sem depender de códigos de correção de erro separados, o que reduz a carga computacional e a complexidade do sistema.
O que isso significa para a imagem sem fio do futuro
Em termos simples, o artigo mostra que ensinar compressores neurais a enviar imagens em pedaços inteligentes e de tamanho reduzido transforma a forma como as fotos viajam por enlaces sem fio não confiáveis. Um design (hyperprior) é otimizado para obter imagens "boas o suficiente" na tela com atraso mínimo, enquanto o outro (VQGAN) é afinado para manter a nitidez das imagens mesmo quando o canal está muito ruim e códigos de proteção adicionais são impraticáveis. Juntos, eles demonstram que a compressão aprendida e progressiva pode manter câmeras e sistemas de visão operando de forma suave onde os codecs atuais falham, apontando para redes futuras em que qualidade, velocidade e robustez da entrega de imagens possam ser equilibradas de forma flexível em tempo real.
Citação: Naseri, M., Ashtari, P., Seif, M. et al. Deep learning-based image compression for wireless communications: impacts on robustness, throughput, and latency. npj Wirel. Technol. 2, 14 (2026). https://doi.org/10.1038/s44459-025-00019-6
Palavras-chave: transmissão de imagens sem fio, compressão por deep learning, codificação progressiva, comunicação de baixa latência, codecs robustos