Clear Sky Science · es
Compresión de imágenes basada en aprendizaje profundo para comunicaciones inalámbricas: impactos en robustez, rendimiento y latencia
Por qué importa una entrega inteligente de imágenes por el aire
Cada día, teléfonos, coches, drones y pequeños sensores capturan imágenes que deben viajar de forma inalámbrica: a veces desde calles urbanas concurridas, otras desde entornos remotos o adversos. Cuando el enlace de radio es débil o ruidoso, los formatos de imagen actuales pueden detenerse, emborronarse o fallar por completo, lo cual es peligroso para tareas como la conducción autónoma o la monitorización remota. Este artículo explora cómo el aprendizaje profundo moderno puede rediseñar la compresión de imágenes para que las fotografías lleguen más rápido y de forma más fiable, incluso cuando el canal inalámbrico es altamente impredecible.
El cuello de botella inalámbrico para las imágenes
Los formatos tradicionales como JPEG, WebP y estándares de vídeo como HEVC se diseñaron para enlaces estables, cableados o de alta calidad. Comprimen las imágenes a menos bits, pero son frágiles: unos pocos bits alterados en el flujo comprimido pueden arruinar la imagen entera, obligando a aplicar corrección de errores intensiva y retransmisiones. En canales inalámbricos reales, especialmente aquellos con desvanecimiento pronunciado y baja relación señal‑ruido (SNR), esa fragilidad se traduce en largos tiempos de espera antes de que aparezca cualquier imagen usable. Sin embargo, muchas aplicaciones modernas —desde cámaras IoT hasta vehículos autónomos— necesitan primero una vista rápida, aunque tosca, de la escena, y solo después refinamientos según lo permita el enlace.
Imágenes progresivas que se adaptan al aire
Los autores construyen una tubería de transmisión adaptativa y progresiva alrededor de dos compresores de imagen con aprendizaje profundo: un modelo “hyperprior” y un modelo VQGAN. En lugar de enviar un flujo de bits rígido por imagen, estos sistemas dividen la representación comprimida en piezas ordenadas. Las piezas más importantes se envían primero y ya permiten una reconstrucción aproximada; las piezas posteriores aportan detalles cuando el canal mejora o hay más ancho de banda disponible. El modelo hyperprior representa la imagen como mapas de características compactos cuya contribución a la calidad se ordena por importancia. El modelo VQGAN representa la imagen usando entradas de un libro de códigos; envía primero códigos groseros y luego refinamientos residuales en etapas. En ambos casos, el transmisor consulta el estado actual del canal y elige cuántas piezas puede enviar con seguridad en ese intervalo de tiempo.
Pruebas en condiciones inalámbricas adversas
Para evaluar estas ideas, el estudio simula la transmisión de imágenes sobre un canal con desvanecimiento Rayleigh, un modelo estándar donde la intensidad de la señal sube y baja de forma impredecible. Usando el conjunto Kodak de imágenes de prueba de alta calidad, los autores comparan su hyperprior progresivo y su VQGAN progresivo frente a una referencia adaptativa WebP que también ajusta su nivel de compresión al canal. De forma crucial, miden no solo la calidad de la imagen sino también el rendimiento (cuántos píxeles por segundo se entregan) y el tiempo de espera —el retardo hasta que una imagen se recibe con éxito. Este tiempo de espera suele ignorarse en trabajos de comunicaciones con aprendizaje profundo, pero domina la experiencia del usuario en aplicaciones sensibles al retardo.
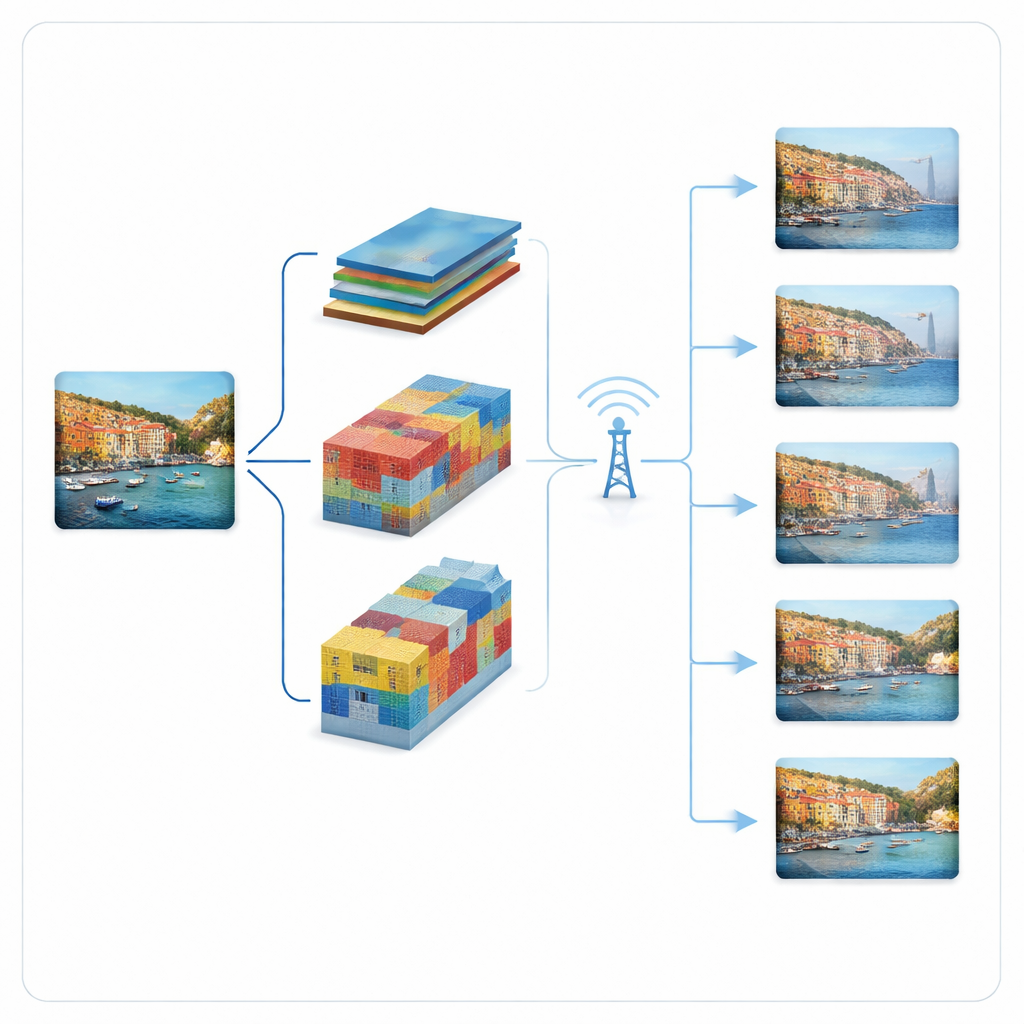
Velocidad frente a robustez: qué gana en cada caso
Los resultados muestran que, en condiciones muy ruidosas, WebP adaptativo básicamente se rinde: el canal no puede soportar ni siquiera su ajuste de calidad más bajo, por lo que no se entrega ninguna imagen completa. En contraste, ambos modelos aprendidos progresivos siguen proporcionando imágenes visibles, porque pueden recurrir a enviar solo una capa base mínima. Entre ellos, el modelo hyperprior progresivo alcanza la latencia más baja y el mayor rendimiento en la mayoría de escenarios de baja SNR, gracias a sus mapas de características muy compactos y finamente ordenados. Esto lo hace especialmente atractivo cuando la respuesta rápida es vital, por ejemplo en sistemas de visión interactivos. El VQGAN progresivo, aunque algo menos eficiente, ofrece mayor calidad visual en las condiciones más adversas y puede tolerar errores de bits sin depender de códigos de corrección separados, lo que reduce la carga computacional y la complejidad del sistema.
Qué significa esto para la imagen inalámbrica del futuro
En términos sencillos, el artículo muestra que enseñar a los compresores neuronales a enviar imágenes en fragmentos inteligentes y manejables transforma la forma en que las imágenes viajan por enlaces inalámbricos poco fiables. Un diseño (hyperprior) está optimizado para llevar imágenes “suficientemente buenas” a la pantalla con retraso mínimo, mientras que el otro (VQGAN) está afinado para mantener las imágenes nítidas incluso cuando el canal es muy malo y los códigos de protección adicionales son impracticables. Juntos, demuestran que la compresión progresiva aprendida puede mantener cámaras y sistemas de visión operando sin problemas donde los códecs actuales tropiezan, apuntando a redes futuras donde la calidad, la velocidad y la robustez de la entrega de imágenes puedan equilibrarse de forma flexible en tiempo real.
Cita: Naseri, M., Ashtari, P., Seif, M. et al. Deep learning-based image compression for wireless communications: impacts on robustness, throughput, and latency. npj Wirel. Technol. 2, 14 (2026). https://doi.org/10.1038/s44459-025-00019-6
Palabras clave: transmisión inalámbrica de imágenes, compresión con aprendizaje profundo, codificación progresiva, comunicación de baja latencia, codecs robustos