Clear Sky Science · fr
Compression d'image par apprentissage profond pour les communications sans fil : impacts sur la robustesse, le débit et la latence
Pourquoi la livraison intelligente d'images par voie hertzienne compte
Chaque jour, des téléphones, des voitures, des drones et de petits capteurs capturent des images qui doivent être transmises sans fil—parfois depuis des rues urbaines encombrées, parfois depuis des environnements éloignés ou agressifs. Lorsque la liaison radio est faible ou bruyante, les formats d'image actuels peuvent se figer, s'embuer ou échouer complètement, ce qui est dangereux pour des tâches comme la conduite autonome ou la surveillance à distance. Cet article explore comment l'apprentissage profond moderne peut repenser la compression d'images afin que les images arrivent plus vite et plus fiablement, même lorsque le canal sans fil est très imprévisible.
Le goulot d'étranglement sans fil pour les images
Les formats traditionnels tels que JPEG, WebP et les standards vidéo comme HEVC ont été conçus pour des liaisons stables, filaires ou de haute qualité. Ils compressent les images dans moins de bits, mais sont fragiles : quelques bits inversés dans le flux compressé peuvent ruiner l'image entière, obligeant à recourir à une correction d'erreurs lourde et à des retransmissions. Dans les canaux sans fil réels, en particulier ceux soumis à de fortes variations d'atténuation et à un faible rapport signal/bruit (SNR), cette fragilité se traduit par de longs temps d'attente avant qu'une image exploitable n'apparaisse. Pourtant, de nombreuses applications modernes—des caméras IoT aux véhicules autonomes—ont besoin d'une vue rapide, même grossière, de la scène en priorité, puis d'affinements au fur et à mesure que la liaison le permet.
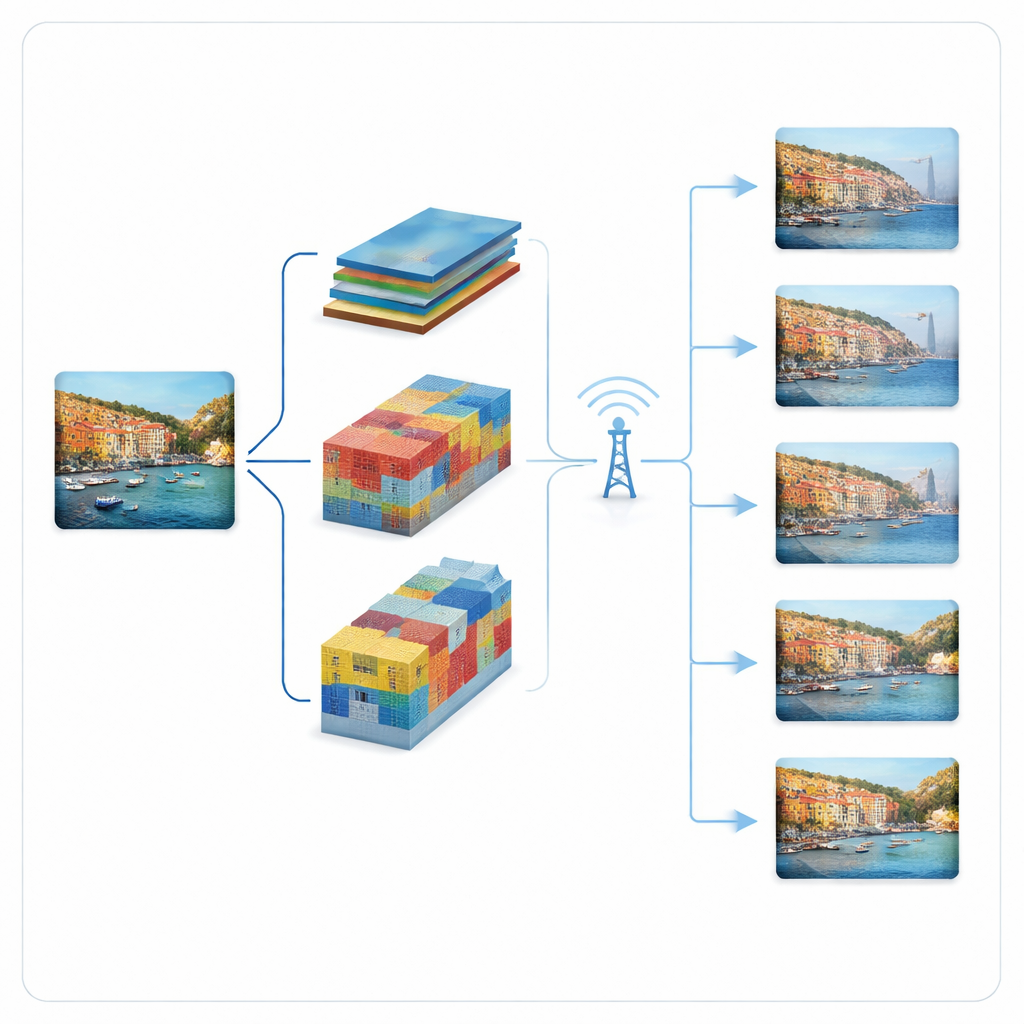
Images progressives qui s'adaptent au canal
Les auteurs construisent une chaîne de transmission adaptative et progressive autour de deux compresseurs d'image par apprentissage profond de pointe : un modèle « hyperprior » et un modèle VQGAN. Plutôt que d'envoyer un flux de bits rigide par image, ces systèmes fragmentent la représentation compressée en morceaux ordonnés. Les morceaux les plus importants sont envoyés en premier et permettent déjà une reconstruction grossière ; les morceaux suivants ajoutent du détail lorsque le canal s'améliore ou que davantage de bande passante devient disponible. Le modèle hyperprior représente l'image par des cartes de caractéristiques compactes dont la contribution à la qualité est classée par importance. Le modèle VQGAN représente l'image à l'aide d'entrées d'un dictionnaire ; il envoie d'abord les codewords grossiers puis des raffinements résiduels en plusieurs étapes. Dans les deux cas, l'émetteur consulte l'état courant du canal et choisit combien de morceaux il peut envoyer en toute sécurité durant la fenêtre temporelle.
Tests en conditions sans fil difficiles
Pour évaluer ces idées, l'étude simule la transmission d'images sur un canal de fading de Rayleigh, un modèle standard où la force du signal monte et descend de façon imprévisible. En utilisant l'ensemble Kodak d'images de test haute qualité, les auteurs comparent leurs modèles progressifs hyperprior et VQGAN progressif à une référence WebP adaptative qui ajuste aussi son niveau de compression au canal. De manière cruciale, ils mesurent non seulement la qualité d'image mais aussi le débit (combien de pixels par seconde sont livrés) et le temps d'attente—le délai avant qu'une image soit reçue avec succès. Ce temps d'attente est souvent ignoré dans les travaux sur les communications par apprentissage profond, mais il domine l'expérience utilisateur dans les applications sensibles au délai.
Vitesse contre robustesse : qui l'emporte où
Les résultats montrent que dans des conditions très bruyantes, le WebP adaptatif standard abandonne essentiellement : le canal ne peut pas soutenir même son réglage de qualité le plus bas, donc aucune image complète n'est livrée. En revanche, les deux modèles appris progressifs fournissent encore des images exploitables, car ils peuvent se replier sur l'envoi d'une couche de base minimale. Parmi eux, le modèle hyperprior progressif atteint la latence la plus faible et le débit le plus élevé dans la plupart des réglages de faible SNR, grâce à ses cartes de caractéristiques très compactes et finement ordonnées. Cela le rend particulièrement attractif lorsque la réponse rapide est vitale, comme pour les systèmes de vision interactifs. Le VQGAN progressif, bien que légèrement moins efficace, offre une qualité visuelle supérieure dans les conditions les plus difficiles et peut tolérer des erreurs de bits sans s'appuyer sur des codes de correction d'erreurs séparés, ce qui réduit la charge de calcul et la complexité système.
Ce que cela implique pour l'imagerie sans fil future
En termes simples, l'article montre qu'apprendre aux compresseurs neuronaux à envoyer les images en morceaux intelligents et de petite taille transforme la manière dont les images circulent sur des liaisons sans fil peu fiables. Un design (hyperprior) est optimisé pour afficher des images « suffisamment bonnes » avec un délai minimal, tandis que l'autre (VQGAN) est réglé pour conserver des images nettes même quand le canal est très mauvais et que des codes de protection supplémentaires sont impraticables. Ensemble, ils démontrent que la compression progressive et apprise peut maintenir les caméras et systèmes de vision opérationnels là où les codecs actuels peinent, ouvrant la voie à des réseaux futurs où la qualité, la rapidité et la robustesse de la livraison d'images peuvent être équilibrées de manière flexible en temps réel.
Citation: Naseri, M., Ashtari, P., Seif, M. et al. Deep learning-based image compression for wireless communications: impacts on robustness, throughput, and latency. npj Wirel. Technol. 2, 14 (2026). https://doi.org/10.1038/s44459-025-00019-6
Mots-clés: transmission d'images sans fil, compression par apprentissage profond, codage progressif, communication à faible latence, codecs robustes