Clear Sky Science · de
Bildkompression auf Deep‑Learning‑Basis für drahtlose Kommunikation: Auswirkungen auf Robustheit, Durchsatz und Latenz
Warum intelligente Bildübertragung über Funk wichtig ist
Jeden Tag erfassen Telefone, Autos, Drohnen und winzige Sensoren Bilder, die drahtlos übertragen werden müssen – manchmal aus überfüllten Stadtstraßen, manchmal aus abgelegenen oder rauen Umgebungen. Wenn die Funkverbindung schwach oder verrauscht ist, können heutige Bildformate stocken, unscharf werden oder komplett ausfallen, was für Aufgaben wie autonomes Fahren oder Fernüberwachung gefährlich ist. Dieses Papier untersucht, wie modernes Deep Learning die Bildkompression neu entwerfen kann, damit Bilder schneller und verlässlicher ankommen, selbst wenn der Funkkanal stark unvorhersehbar ist.
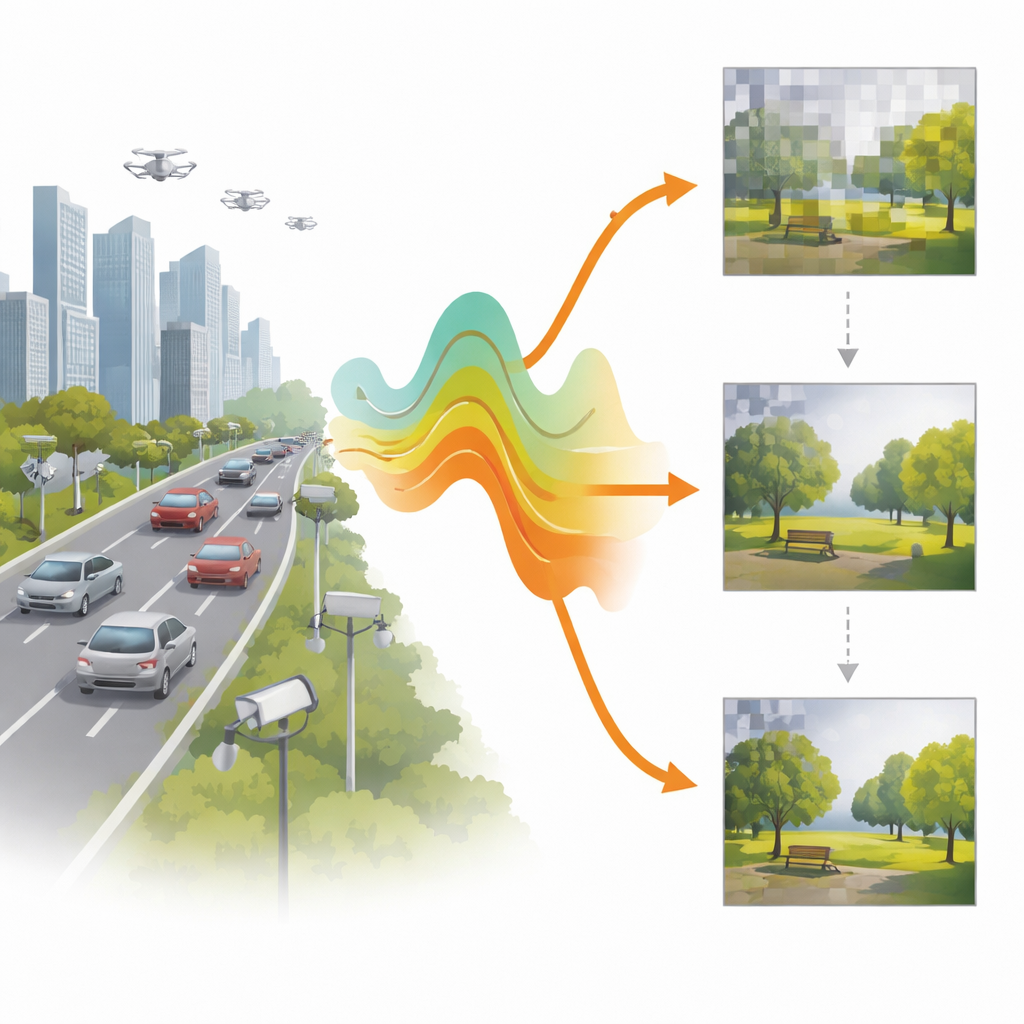
Der drahtlose Engpass für Bilder
Traditionelle Formate wie JPEG, WebP und Videostandards wie HEVC wurden für stabile, kabelgebundene oder hochwertige Verbindungen entwickelt. Sie pressen Bilder in weniger Bits, sind aber fragil: ein paar veränderte Bits im komprimierten Datenstrom können das ganze Bild ruinieren und starke Fehlerkorrektur sowie Neuaussendungen erzwingen. In realen Funkkanälen, insbesondere solchen mit starkem Fading und niedrigem Signal‑zu‑Rausch‑Verhältnis (SNR), führt diese Fragilität zu langen Wartezeiten, bevor überhaupt ein brauchbares Bild erscheint. Doch viele moderne Anwendungen – von IoT‑Kameras bis zu selbstfahrenden Autos – brauchen zuerst eine schnelle, wenn auch grobe, Sicht auf die Szene und erst danach Verfeinerungen, sobald der Kanal es zulässt.
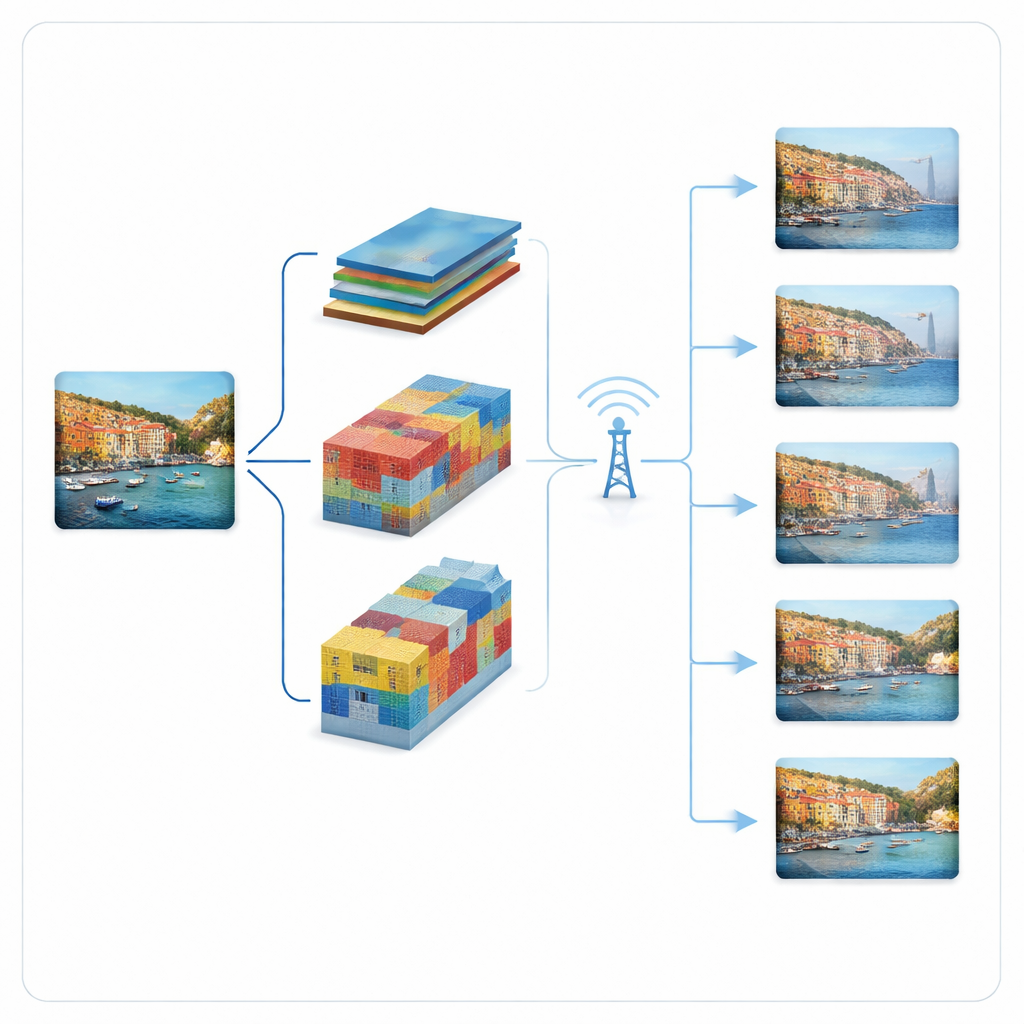
Progressive Bilder, die sich dem Funk anpassen
Die Autoren bauen eine adaptive, progressive Übertragungspipeline um zwei führende Deep‑Learning‑Bildkompressor‑Modelle auf: ein »Hyperprior«‑Modell und ein VQGAN‑Modell. Statt einen starren Bitstrom pro Bild zu senden, zerlegen diese Systeme die komprimierte Darstellung in geordnete Teile. Die wichtigsten Teile werden zuerst gesendet und erlauben bereits eine grobe Rekonstruktion; spätere Teile fügen Details hinzu, wenn sich der Kanal verbessert oder mehr Bandbreite verfügbar wird. Das Hyperprior‑Modell stellt das Bild als kompakte Feature‑Maps dar, deren Beitrag zur Qualität nach Wichtigkeit gerankt ist. Das VQGAN‑Modell repräsentiert das Bild mithilfe von Codebucheinträgen; es sendet zuerst grobe Codewörter und dann in Stufen residuale Verfeinerungen. In beiden Fällen berücksichtigt der Sender den aktuellen Kanalzustand und wählt aus, wie viele Teile er sicher in diesem Zeitschlitz senden kann.
Tests unter rauen Funkbedingungen
Um diese Ideen zu bewerten, simuliert die Studie die Bildübertragung über einen Rayleigh‑Fading‑Kanal, ein Standardmodell, bei dem die Signalstärke unvorhersehbar steigt und fällt. Mit dem Kodak‑Datensatz hochwertiger Testbilder vergleichen die Autoren ihr progressives Hyperprior und ihr progressives VQGAN mit einer adaptiven WebP‑Baseline, die ebenfalls ihr Kompressionsniveau an den Kanal anpasst. Entscheidend ist, dass sie nicht nur die Bildqualität messen, sondern auch den Durchsatz (wie viele Pixel pro Sekunde geliefert werden) und die Wartezeit – die Verzögerung, bis ein Bild erfolgreich empfangen wird. Diese Wartezeit wird in Arbeiten zur Deep‑Learning‑Kommunikation oft vernachlässigt, dominiert jedoch die Benutzererfahrung in latenzsensitiven Anwendungen.
Geschwindigkeit versus Robustheit: was wo gewinnt
Die Ergebnisse zeigen, dass unter sehr verrauschten Bedingungen die standardmäßige adaptive WebP im Grunde aufgibt: Der Kanal kann nicht einmal deren niedrigste Qualitätsstufe tragen, sodass kein vollständiges Bild geliefert wird. Im Gegensatz dazu liefern beide progressiven, gelernten Modelle weiterhin sichtbare Bilder, weil sie auf das Senden nur einer minimalen Basis‑Schicht zurückfallen können. Unter ihnen erzielt das progressive Hyperprior‑Modell in den meisten Niedrig‑SNR‑Einstellungen die niedrigste Latenz und den höchsten Durchsatz, dank seiner sehr kompakten, fein geordneten Feature‑Maps. Das macht es besonders attraktiv, wenn schnelle Reaktion entscheidend ist, etwa für interaktive Sichtsysteme. Das progressive VQGAN ist zwar etwas weniger effizient, bietet aber in den härtesten Bedingungen höhere visuelle Qualität und kann Bitfehler tolerieren, ohne auf separate Fehlerkorrekturcodes angewiesen zu sein, was die Rechenlast und Systemkomplexität reduziert.
Was das für die zukünftige drahtlose Bildgebung bedeutet
Einfach gesagt zeigt das Papier, dass das Lehren neuronaler Kompressoren, Bilder in intelligente, mundgerechte Stücke zu senden, die Art und Weise verändert, wie Bilder über unzuverlässige Funkverbindungen reisen. Ein Design (Hyperprior) ist darauf optimiert, möglichst schnell »gut genug« Bilder auf den Bildschirm zu bringen, während das andere (VQGAN) darauf ausgelegt ist, Bilder auch bei sehr schlechtem Kanal scharf zu halten, wenn zusätzliche Schutzcodes unpraktisch sind. Zusammen demonstrieren sie, dass progressive, gelernte Kompression Kameras und Sichtsysteme dort reibungslos arbeiten lassen kann, wo heutige Codecs scheitern, und weisen auf zukünftige Netzwerke hin, in denen Qualität, Geschwindigkeit und Robustheit der Bildübertragung in Echtzeit flexibel ausbalanciert werden können.
Zitation: Naseri, M., Ashtari, P., Seif, M. et al. Deep learning-based image compression for wireless communications: impacts on robustness, throughput, and latency. npj Wirel. Technol. 2, 14 (2026). https://doi.org/10.1038/s44459-025-00019-6
Schlüsselwörter: drahtlose Bildübertragung, Deep‑Learning‑Kompression, progressive Codierung, niedrige Latenz Kommunikation, robuste Codecs