Clear Sky Science · it
Compressione delle immagini basata su deep learning per le comunicazioni wireless: impatti su robustezza, throughput e latenza
Perché la consegna intelligente delle immagini over‑the‑air è importante
Ogni giorno telefoni, auto, droni e piccoli sensori acquisiscono immagini che devono viaggiare wireless—talvolta dalle strade affollate della città, talvolta da ambienti remoti o ostili. Quando il collegamento radio è debole o rumoroso, i formati d’immagine attuali possono bloccarsi, sfocarsi o fallire del tutto, cosa pericolosa per attività come la guida autonoma o il monitoraggio remoto. Questo articolo esplora come il deep learning moderno possa riprogettare la compressione delle immagini in modo che le foto arrivino più velocemente e in modo più affidabile, anche quando il canale wireless è altamente imprevedibile.
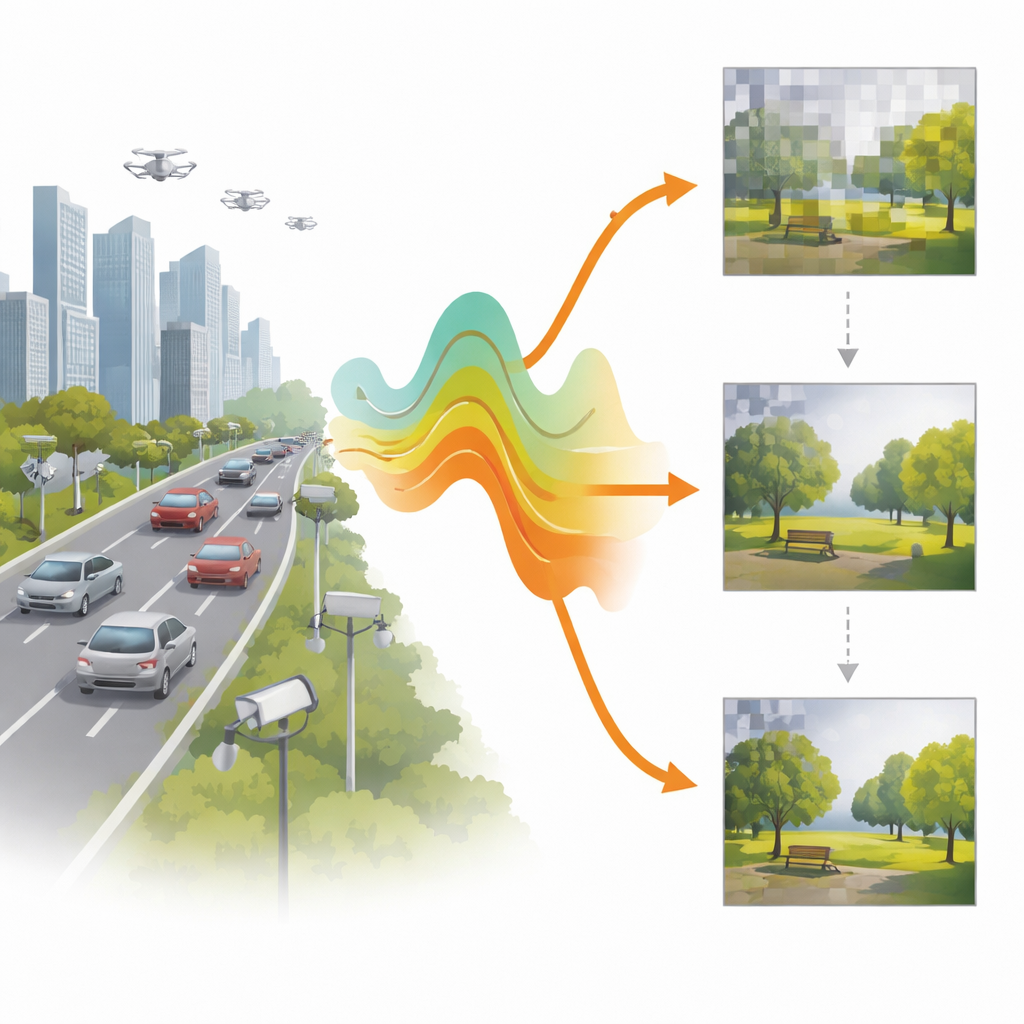
Il collo di bottiglia wireless per le immagini
I formati tradizionali come JPEG, WebP e gli standard video come HEVC sono stati sviluppati per collegamenti stabili, cablati o di alta qualità. Riducono il numero di bit necessari per un’immagine, ma sono fragili: pochi bit invertiti nello stream compresso possono rovinare l’intera immagine, imponendo pesanti correzioni d’errore e ritrasmissioni. Nei canali wireless reali, specialmente quelli con forte fading e basso rapporto segnale‑rumore (SNR), questa fragilità si traduce in lunghi tempi di attesa prima che appaia una immagine utilizzabile. Molte applicazioni moderne—from telecamere IoT a veicoli autonomi—hanno però bisogno prima di una visione rapida, seppure approssimativa, della scena, e solo successivamente di raffinamenti man mano che il collegamento lo consente.
Immagini progressive che si adattano all’aria
Gli autori sviluppano una pipeline adattiva e progressiva per la trasmissione basata su due dei principali compressori d’immagini deep learning: un modello “hyperprior” e un modello VQGAN. Invece di inviare un unico stream di bit rigido per immagine, questi sistemi suddividono la rappresentazione compressa in pezzi ordinati. I pezzi più importanti vengono inviati per primi e permettono già una ricostruzione grezza; i pezzi successivi aggiungono dettagli quando il canale migliora o è disponibile più larghezza di banda. Il modello hyperprior rappresenta l’immagine come mappe di feature compatte il cui contributo alla qualità è classificato per importanza. Il modello VQGAN rappresenta l’immagine usando voci di un codebook; invia prima codeword grossolane e poi affinamenti residui a stadi. In entrambi i casi, il trasmettitore consulta lo stato corrente del canale e sceglie quanti pezzi può inviare in sicurezza in quel timeslot.
Test in condizioni wireless avverse
Per valutare queste idee, lo studio simula la trasmissione di immagini su un canale Rayleigh fading, un modello standard in cui la potenza del segnale aumenta e diminuisce in modo imprevedibile. Usando il set Kodak di immagini di prova ad alta qualità, gli autori confrontano il loro hyperprior progressivo e il VQGAN progressivo con un baseline WebP adattivo che regola anch’esso il livello di compressione in funzione del canale. In modo cruciale, misurano non solo la qualità dell’immagine ma anche il throughput (quanti pixel al secondo vengono consegnati) e il tempo di attesa—il ritardo fino a quando un’immagine è ricevuta con successo. Questo tempo di attesa è spesso ignorato nei lavori di comunicazione basata su deep learning, ma domina l’esperienza utente nelle applicazioni sensibili al ritardo.
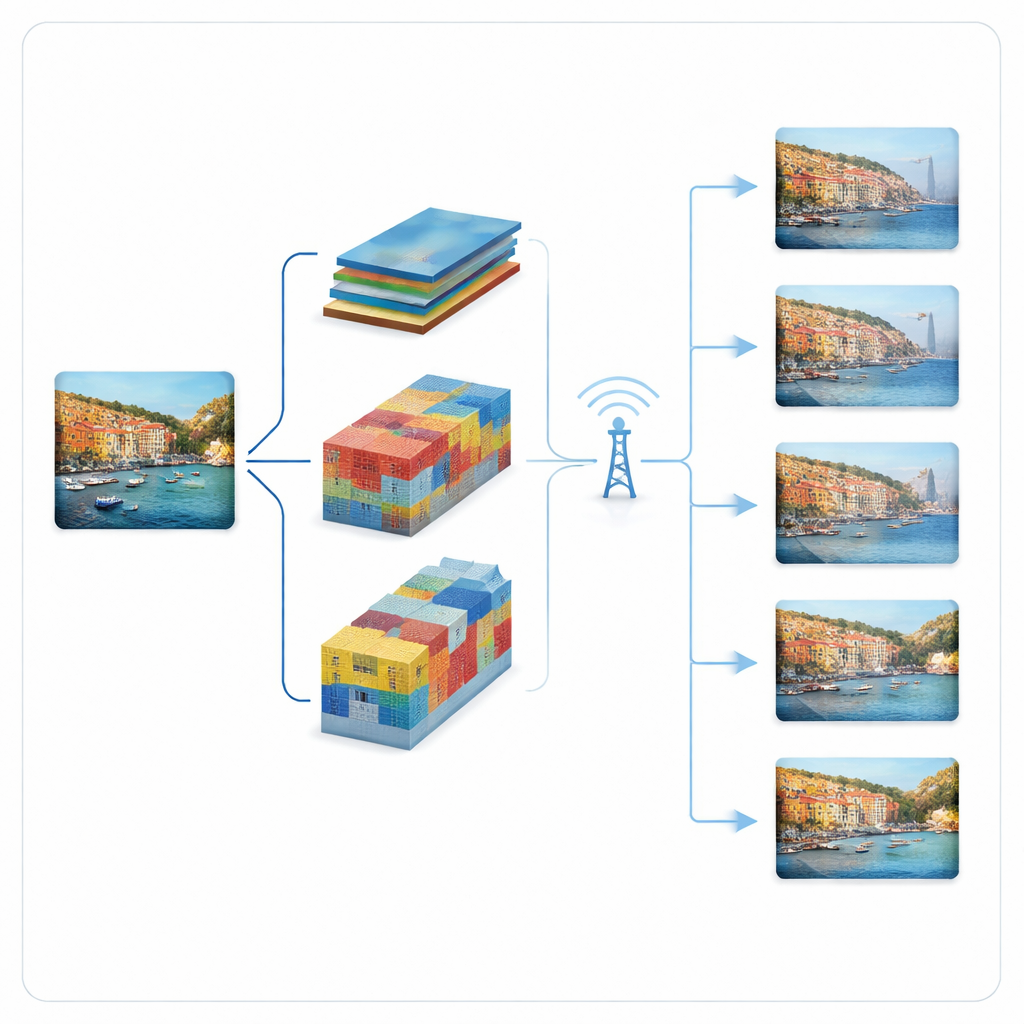
Velocità vs robustezza: chi vince dove
I risultati mostrano che in condizioni molto rumorose, l’adattivo WebP standard sostanzialmente rinuncia: il canale non supporta nemmeno il suo livello di qualità più basso, quindi nessuna immagine completa viene consegnata. Al contrario, entrambi i modelli appresi e progressivi continuano a fornire immagini visualizzabili, perché possono ricorrere all’invio solo di uno strato base minimale. Tra questi, il modello hyperprior progressivo raggiunge la latenza più bassa e il throughput più alto nella maggior parte degli scenari a basso SNR, grazie alle sue mappe di feature molto compatte e finemente ordinate. Questo lo rende particolarmente interessante quando la risposta rapida è vitale, come nei sistemi di visione interattiva. Il VQGAN progressivo, sebbene leggermente meno efficiente, offre qualità visiva superiore nelle condizioni più estreme e può tollerare errori di bit senza dipendere da codici di correzione separati, riducendo così il carico computazionale e la complessità del sistema.
Cosa significa per il futuro dell’imaging wireless
In termini semplici, l’articolo dimostra che insegnare ai compressori neurali a inviare immagini in porzioni intelligenti e di piccole dimensioni trasforma il modo in cui le immagini viaggiano su collegamenti wireless inaffidabili. Un progetto (hyperprior) è ottimizzato per mostrare sullo schermo immagini “sufficientemente buone” con ritardo minimo, mentre l’altro (VQGAN) è tarato per mantenere immagini nitide anche quando il canale è molto degradato e l’uso di codici di protezione aggiuntivi è impraticabile. Insieme, dimostrano che la compressione appresa e progressiva può mantenere telecamere e sistemi di visione operativi dove i codec odierni inciampano, indicando reti future in cui qualità, velocità e robustezza della consegna delle immagini possono essere bilanciate in tempo reale.
Citazione: Naseri, M., Ashtari, P., Seif, M. et al. Deep learning-based image compression for wireless communications: impacts on robustness, throughput, and latency. npj Wirel. Technol. 2, 14 (2026). https://doi.org/10.1038/s44459-025-00019-6
Parole chiave: trasmissione wireless di immagini, compressione deep learning, codifica progressiva, comunicazione a bassa latenza, codec robusti