Clear Sky Science · pt
Estrutura evolutiva de aprendizado por reforço para resiliência a falhas energeticamente eficiente e estabilidade topológica em RSAs
Por que redes de sensores inteligentes importam
Da agricultura de precisão a sistemas de alerta de desastres, redes de sensores sem fio vigiam nosso mundo de forma discreta. Dispositivos minúsculos alimentados por bateria, espalhados por cidades, fábricas, florestas e hospitais, coletam dados e os enviam para análise. Mas, por serem baratos, remotos e de manutenção difícil, esses sensores falham com frequência e ficam sem energia rapidamente. Este artigo explora uma nova maneira de manter essas redes funcionando por mais tempo, com mais confiabilidade e com menos intervenções humanas, usando uma estrutura inteligente de aprendizado chamada EvoGenRL.
O desafio dos sensores cansados e com falhas
Redes de sensores sem fio precisam conciliar várias necessidades ao mesmo tempo. Cada nó tem energia de bateria e capacidade de processamento muito limitadas. Tempo, danos físicos ou interferência podem causar falhas em nós ou enlaces, rompendo caminhos de comunicação. À medida que as redes crescem em tamanho e complexidade, cargas de tráfego e condições externas mudam constantemente. Métodos tradicionais geralmente tratam apenas um aspecto, como economia de energia ou melhoria de roteamento, e costumam ser projetados para situações fixas e previsíveis. Como resultado, quando as falhas se acumulam ou as condições mudam, essas redes podem sofrer perda de dados, atrasos maiores e redução da vida útil.
Um cérebro aprendente para redes de sensores
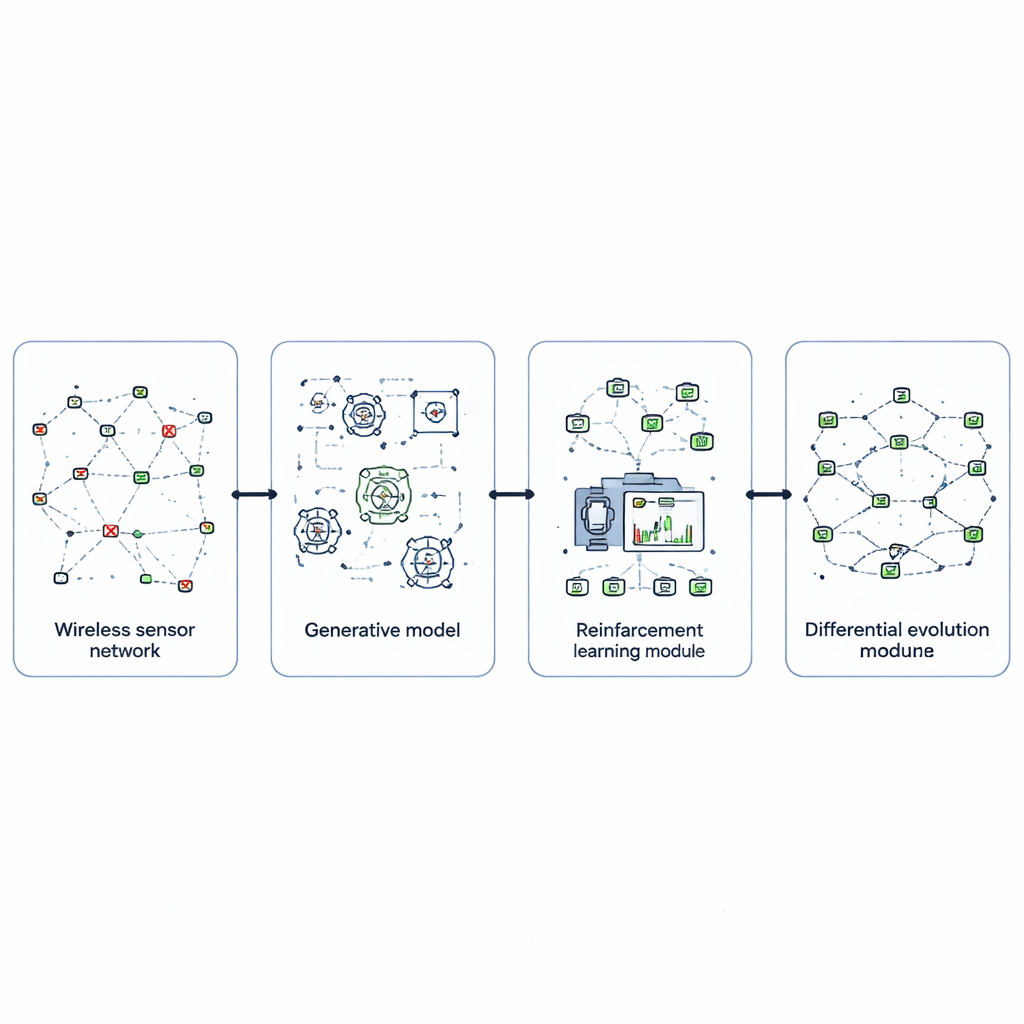
Para enfrentar isso, os autores projetam o EvoGenRL, uma estrutura de aprendizado combinada que trata a rede como um sistema capaz de aprender com a experiência. No núcleo está o aprendizado por reforço, um método de tentativa e erro em que um agente inteligente observa a condição da rede — como níveis de bateria, sucesso de entrega e falhas recentes — e escolhe ações como alterar rotas, colocar alguns nós em modo de sono ou retransmitir dados. Ações que economizam energia, entregam mais pacotes e se recuperam mais rápido de falhas recebem maiores recompensas, orientando o agente a um comportamento melhor em longo prazo. Isso transforma o controle da rede de regras fixas em uma política adaptativa que melhora à medida que enfrenta novas situações.
Imaginando problemas antes que aconteçam
Uma dificuldade central em qualquer sistema de aprendizado é treiná‑lo com situações realistas suficientes, especialmente falhas raras, mas danosas. O EvoGenRL resolve isso usando redes generativas adversariais, uma classe de modelos que pode inventar novos dados que imitam exemplos reais. Aqui, uma rede geradora fabrica padrões plausíveis de falhas em sensores — como agrupamentos de nós com falha ou rajadas de interferência — enquanto uma rede discriminadora avalia se esses padrões se assemelham a eventos registrados genuínos. Pela competição entre elas, o gerador produz uma variedade rica de cenários de falha críveis. Essas situações sintéticas são misturadas com dados reais e alimentadas ao agente de aprendizado por reforço, para que ele possa treinar como lidar com muitos tipos de problema antes que a rede os enfrente em campo.
Ajustando o comportamento por evolução
Mesmo um agente de aprendizado inteligente depende fortemente de seus parâmetros internos, como a velocidade de aprendizado, o peso dado a recompensas futuras e a frequência com que deve explorar novas ações. Em vez de escolher esses controles manualmente, os autores usam um método de busca evolutiva chamado evolução diferencial. Eles tratam cada configuração possível como um indivíduo em uma população e os deixam “competir” com base em quão bem o agente resultante controla a rede em simulação. Ao repetir mutações, combinações e seleção dos melhores candidatos, o método converge para hiperparâmetros que tornam o aprendizado mais rápido, estável e melhor adaptado às condições de rede em mudança. Essa camada evolutiva envolve o agente de aprendizado, refinando continuamente seu desempenho.
Testando a estrutura
Os pesquisadores avaliam o EvoGenRL usando um conjunto de dados público de atividade de sensores sem fio e simulações detalhadas de rede. Eles o comparam com vários esquemas estabelecidos de roteamento e otimização extraídos da literatura recente. Ao longo de execuções repetidas e com diferentes tamanhos de rede e taxas de falha, a nova estrutura usa consistentemente menos energia, mantém mais nós vivos por mais tempo e preserva conexões mais estáveis. Em números, o EvoGenRL reduz o consumo de energia para cerca de 2,2 joules por nó, estende a vida da rede para 1.700 ciclos e eleva a parcela de pacotes de dados entregues com sucesso para 99,7%. Também reduz o tempo que os dados levam para atravessar a rede para alguns milissegundos e aumenta a taxa de transferência geral, o que significa que a rede pode permanecer responsiva mesmo enquanto economiza energia.
O que isso significa para a tecnologia do dia a dia
Em termos simples, o EvoGenRL ensina uma rede de sensores a cuidar de si mesma. Ao simular muitos tipos de falhas, aprender quais respostas funcionam melhor e afinar continuamente seu próprio comportamento, o sistema pode prolongar a vida das baterias e manter o fluxo de dados apesar de falhas e condições variáveis. Isso o torna atraente para usos críticos, como monitoramento médico, controle industrial e vigilância ambiental, onde visitas de manutenção são dispendiosas ou perigosas e tempo de inatividade é inaceitável. Embora a abordagem ainda exija poder computacional significativo durante o treinamento, oferece um roteiro promissor para futuras redes autogerenciáveis mais inteligentes, mais robustas e mais econômicas em seu orçamento de energia limitado.
Citação: Lakshmi, S., Aswath, S., Swaminathan, A. et al. Evolutionary reinforcement learning framework for energy-efficient fault resilience and topological stability in WSNs. Sci Rep 16, 11769 (2026). https://doi.org/10.1038/s41598-026-38518-3
Palavras-chave: redes de sensores sem fio, redes energeticamente eficientes, sistemas tolerantes a falhas, aprendizado por reforço, modelos generativos