Clear Sky Science · de
Evolutionäres Reinforcement‑Learning‑Framework für energieeffiziente Fehlertoleranz und topologische Stabilität in WSNs
Warum intelligente Sensornetzwerke wichtig sind
Von präziser Landwirtschaft bis zu Katastrophenwarnsystemen beobachten drahtlose Sensornetzwerke still und leise unsere Umwelt. Winzige, batteriebetriebene Geräte, verteilt in Städten, Fabriken, Wäldern und Krankenhäusern, sammeln Daten und senden sie zur Analyse. Da diese Sensoren jedoch günstig, entlegen und schwer wartbar sind, fallen sie häufig aus und verlieren schnell Energie. Dieses Papier untersucht eine neue Methode, solche Netzwerke länger, zuverlässiger und mit weniger menschlichem Eingriff am Laufen zu halten, mithilfe eines intelligenten Lernframeworks namens EvoGenRL.
Die Herausforderung erschöpfter und ausfallender Sensoren
Drahtlose Sensornetzwerke müssen mehrere Anforderungen gleichzeitig bewältigen. Jeder Knoten hat nur sehr begrenzte Batteriekapazität und Rechenleistung. Wetter, physische Beschädigung oder Störungen können Knoten oder Verbindungen ausfallen lassen und Kommunikationspfade unterbrechen. Mit wachsender Größe und Komplexität ändern sich Verkehrsaufkommen und Umgebungsbedingungen ständig. Traditionelle Methoden bearbeiten meist nur einen Aspekt, etwa Energiesparen oder Routing‑Verbesserung, und sind oft für feste, vorhersehbare Szenarien ausgelegt. Folglich können bei gehäuften Fehlern oder veränderten Bedingungen Datenverlust, höhere Verzögerungen und verkürzte Lebensdauern auftreten.
Ein lernendes Gehirn für Sensornetzwerke
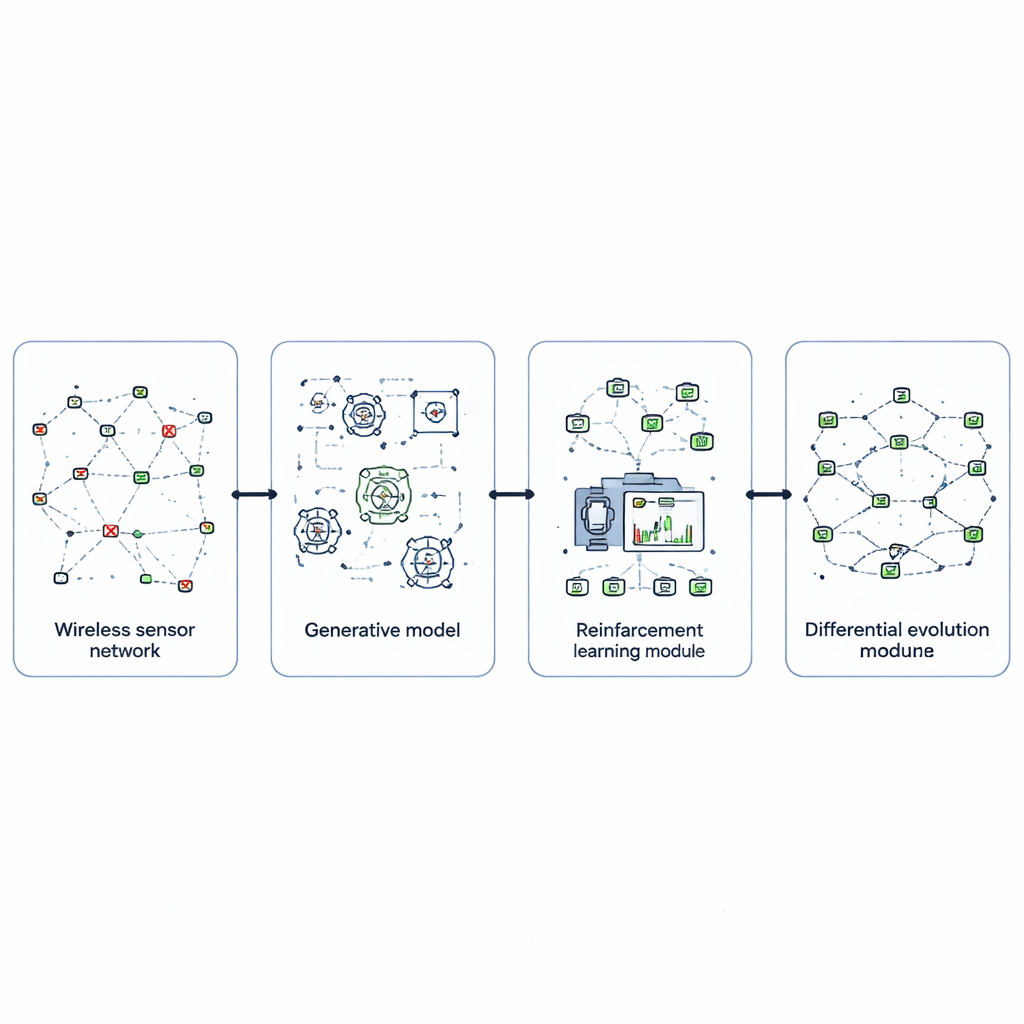
Um dem zu begegnen, entwerfen die Autoren EvoGenRL, ein kombiniertes Lernframework, das das Netzwerk als ein System behandelt, das aus Erfahrung lernen kann. Im Kern steht Reinforcement Learning, eine Trial‑and‑Error‑Methode, bei der ein intelligenter Agent den Zustand des Netzwerks beobachtet — etwa Batteriestände, Zustellraten und jüngste Fehler — und Aktionen wählt wie Pfadänderungen, das Schlafschalten bestimmter Knoten oder das erneute Senden von Daten. Aktionen, die Energie sparen, mehr Pakete zustellen und schneller von Fehlern erholen, erhalten höhere Belohnungen und lenken den Agenten zu besserem langfristigem Verhalten. So wandelt sich die Netzwerksteuerung von festen Regeln zu einer adaptiven Politik, die sich bei neuen Situationen verbessert.
Probleme antizipieren, bevor sie auftreten
Eine zentrale Schwierigkeit für lernende Systeme ist, sie auf genügend realistische Situationen zu trainieren, insbesondere auf seltene, aber schädliche Ausfälle. EvoGenRL begegnet dem mithilfe generativer adversarieller Netzwerke, einer Klasse von Modellen, die neue Daten erzeugen können, die echten Beispielen ähneln. Hier fabriziert ein Generator plausible Muster von Sensorsausfällen — etwa Ansammlungen ausgefallener Knoten oder Störungsbündel —, während ein Diskriminator beurteilt, ob diese Muster echten aufgezeichneten Ereignissen gleichen. Durch ihren Wettkampf erzeugt der Generator eine große Vielfalt glaubhafter Fehlerszenarien. Diese synthetischen Situationen werden mit realen Daten gemischt und dem Reinforcement‑Learning‑Agenten zugeführt, sodass er das Bewältigen vieler Störungsarten üben kann, bevor das Netzwerk sie im Feld erlebt.
Feinabstimmung des Verhaltens durch Evolution
Selbst ein kluger Lernagent ist stark von seinen internen Einstellungen abhängig, etwa von der Lernrate, wie sehr er zukünftige Belohnungen bewertet, und wie oft er neue Aktionen erkundet. Statt diese Stellschrauben manuell zu wählen, setzen die Autoren eine evolutionäre Suchmethode namens Differential Evolution ein. Jede mögliche Einstellung wird als Individuum in einer Population betrachtet und anhand der Leistung des resultierenden Agenten in Simulationen „konkurrieren“ gelassen. Durch wiederholtes Mutieren, Kombinieren und Selektieren der besten Kandidaten konvergiert die Methode zu Hyperparametern, die das Lernen schneller, stabiler und besser an wechselnde Netzbedingungen angepasst machen. Diese evolutionäre Ebene umgibt den Lernagenten und schärft seine Leistung kontinuierlich.
Das Framework auf die Probe gestellt
Die Forschenden bewerten EvoGenRL mithilfe eines öffentlich verfügbaren Datensatzes zur Aktivität drahtloser Sensoren und detaillierter Netzwerksimulationen. Sie vergleichen es mit mehreren etablierten Routing‑ und Optimierungsschemata aus aktueller Literatur. Über wiederholte Läufe und bei variierenden Netzgrößen und Fehlerquoten nutzt das neue Framework durchgängig weniger Energie, hält mehr Knoten länger am Leben und erhält stabilere Verbindungen. Konkret reduziert EvoGenRL den Energieverbrauch auf etwa 2,2 Joule pro Knoten, verlängert die Netzlebensdauer auf 1700 Zyklen und erhöht den Anteil erfolgreich zugestellter Datenpakete auf 99,7 Prozent. Zudem verkürzt es die Latenz, sodass Daten in wenigen Millisekunden das Netzwerk durchlaufen, und steigert die Gesamtdatenrate, sodass das Netzwerk reaktionsfähig bleibt und gleichzeitig Energie spart.
Was das für Alltags‑Technologie bedeutet
Einfach gesagt lehrt EvoGenRL ein Sensornetzwerk, sich selbst zu versorgen. Durch das Simulieren vieler Fehlertypen, das Lernen wirksamer Reaktionen und das stetige Feinjustieren seines Verhaltens kann das System Batterien länger schonen und Datenfluss trotz Fehlern und wechselnder Bedingungen aufrechterhalten. Das macht es attraktiv für kritischere Einsätze wie medizinische Überwachung, industrielle Steuerung und Umweltbeobachtung, wo Wartungsbesuche kostspielig oder gefährlich sind und Ausfallzeiten inakzeptabel. Auch wenn der Ansatz während des Trainings noch beträchtliche Rechenressourcen verlangt, bietet er eine vielversprechende Blaupause für künftige selbstverwaltende Netzwerke, die klüger, robuster und energieeffizienter sind.
Zitation: Lakshmi, S., Aswath, S., Swaminathan, A. et al. Evolutionary reinforcement learning framework for energy-efficient fault resilience and topological stability in WSNs. Sci Rep 16, 11769 (2026). https://doi.org/10.1038/s41598-026-38518-3
Schlüsselwörter: drahtlose Sensornetzwerke, energieeffiziente Vernetzung, fehlertolerante Systeme, Reinforcement Learning, generative Modelle