Clear Sky Science · nl
Evolutionair reinforcement-learningkader voor energiezuinige fouttolerantie en topologische stabiliteit in WSN's
Waarom slimme sensornetwerken ertoe doen
Van precisielandbouw tot waarschuwingssystemen bij rampen: draadloze sensornetwerken houden onze omgeving stilletjes in de gaten. Kleine, batterijgevoede apparaten verspreid over steden, fabrieken, bossen en ziekenhuizen verzamelen gegevens en sturen die ter analyse terug. Omdat deze sensoren goedkoop, op afstand geplaatst en moeilijk te onderhouden zijn, falen ze vaak en raken ze snel door hun energievoorraad. Dit artikel onderzoekt een nieuwe manier om zulke netwerken langer, betrouwbaarder en met minder menselijke tussenkomst te laten werken, met een intelligent leerframework genaamd EvoGenRL.
De uitdaging van uitgeputte en falende sensoren
Draadloze sensornetwerken moeten meerdere eisen tegelijk afwegen. Elke knooppunt heeft zeer beperkte batterij-energie en rekenkracht. Weer, fysieke schade of storing in de omgeving kan knooppunten of verbindingen doen uitvallen en communicatieroutes verbreken. Naarmate netwerken groter en complexer worden, veranderen verkeersbelasting en omgevingscondities voortdurend. Traditionele methoden pakken meestal slechts één aspect aan, zoals energiebesparing of routingverbetering, en ze zijn vaak ontworpen voor vaste, voorspelbare situaties. Daardoor kunnen netwerken bij opeenstapeling van fouten of veranderende omstandigheden te maken krijgen met dataverlies, grotere vertragingen en verkorte levensduur.
Een lerend brein voor sensornetwerken
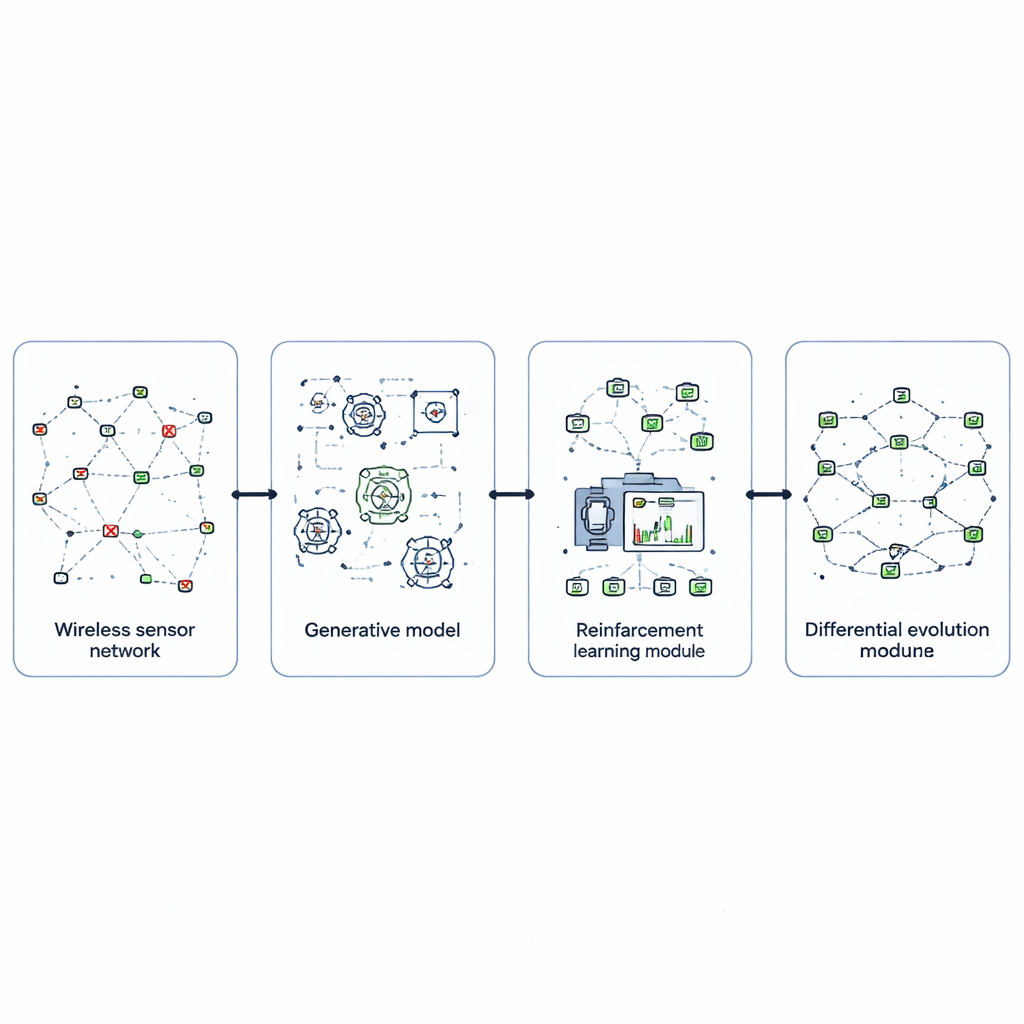
Om dit aan te pakken, ontwerpen de auteurs EvoGenRL, een gecombineerd leerframework dat het netwerk behandelt als een systeem dat van ervaring kan leren. Centraal staat reinforcement learning, een proef‑en‑foutmethode waarbij een intelligente agent de toestand van het netwerk observeert — zoals batterijniveau, afleveringssucces en recente storingen — en acties kiest zoals het wijzigen van routes, sommige knooppunten laten slapen of gegevens opnieuw verzenden. Acties die energie besparen, meer pakketten afleveren en sneller herstellen van fouten krijgen hogere beloningen, waardoor de agent wordt aangezet tot beter langetermijngedrag. Dit verandert netwerkbesturing van vaste regels in een adaptief beleid dat verbetert naarmate het nieuwe situaties tegenkomt.
Problemen bedenken voordat ze gebeuren
Een belangrijke moeilijkheid bij elk leersysteem is het trainen op voldoende realistische situaties, vooral zeldzame maar schadelijke storingen. EvoGenRL pakt dit aan met generative adversarial networks, een klasse modellen die nieuwe data kan bedenken die echte voorbeelden nabootsen. Hier fabriceert een generator-netwerk plausibele patronen van sensorsstoringen — zoals clusters van falende knooppunten of uitbarstingen van storing — terwijl een discriminator-netwerk beoordeelt of deze patronen lijken op echte geregistreerde gebeurtenissen. Door hun competitie produceert de generator een rijke variëteit aan geloofwaardige foutscenario’s. Deze synthetische situaties worden gemengd met echte data en gevoed aan de reinforcement-learningagent, zodat die kan oefenen met het omgaan met veel soorten problemen voordat het netwerk ze in het veld tegenkomt.
Gedrag bijschaven via evolutie
Zelfs een slimme leeragent is sterk afhankelijk van zijn interne instellingen, zoals hoe snel hij leert, hoeveel waarde hij hecht aan toekomstige beloningen en hoe vaak hij nieuwe acties moet verkennen. In plaats van deze knoppen handmatig te kiezen, gebruiken de auteurs een evolutionaire zoekmethode genaamd differential evolution. Ze behandelen elke mogelijke instelling als een individu in een populatie en laten ze "concurreren" op basis van hoe goed de resulterende agent het netwerk in simulatie bestuurt. Door herhaaldelijk te muteren, combineren en de beste kandidaten te selecteren, convergeert de methode naar hyperparameters die het leren sneller, stabieler en beter geschikt voor veranderende netwerkcondities maken. Deze evolutionaire laag omsluit de leeragent en scherpt zijn prestaties gestaag aan.
Het framework op de proef gesteld
De onderzoekers evalueren EvoGenRL met een publiek beschikbare dataset van draadloze sensoractiviteit en gedetailleerde netsimulaties. Ze vergelijken het met verschillende gevestigde routing- en optimalisatieschema’s uit recente literatuur. Over herhaalde runs en uiteenlopende netwerkgroottes en storingspercentages gebruikt het nieuwe framework consequent minder energie, houdt het meer knooppunten langer in leven en behoudt het stabielere verbindingen. In cijfers: EvoGenRL verlaagt het energieverbruik tot ongeveer 2,2 joule per knooppunt, verlengt de netwerkleeftijd tot 1700 cycli en verhoogt het aandeel succesvol afgeleverde datapakketten tot 99,7 procent. Het verkort ook de tijd die data nodig heeft om het netwerk te doorkruisen tot enkele milliseconden en verhoogt de totale datasnelheid, wat betekent dat het netwerk responsief kan blijven terwijl het energie bespaart.
Wat dit betekent voor alledaagse technologie
In eenvoudige termen leert EvoGenRL een sensornetwerk om voor zichzelf te zorgen. Door veel soorten storingen te simuleren, te leren welke reacties het beste werken en voortdurend het eigen gedrag bij te schaven, kan het systeem batterijen langer sparen en de datastroom behouden ondanks fouten en veranderende omstandigheden. Dit maakt het aantrekkelijk voor kritieke toepassingen, zoals medische monitoring, industriële besturing en milieubewaking, waar onderhoudsbezoeken kostbaar of gevaarlijk zijn en uitval onacceptabel is. Hoewel de benadering tijdens training nog steeds aanzienlijke rekenkracht vergt, biedt het een veelbelovend blauwdruk voor toekomstige zelfbeheerende netwerken die slimmer, robuuster en zuiniger met hun beperkte energiebronnen zijn.
Bronvermelding: Lakshmi, S., Aswath, S., Swaminathan, A. et al. Evolutionary reinforcement learning framework for energy-efficient fault resilience and topological stability in WSNs. Sci Rep 16, 11769 (2026). https://doi.org/10.1038/s41598-026-38518-3
Trefwoorden: draadloze sensornetwerken, energiezuinig netwerken, fouttolerante systemen, reinforcement learning, generatieve modellen