Clear Sky Science · fr
Cadre d’apprentissage par renforcement évolutif pour la résilience aux pannes économe en énergie et la stabilité topologique dans les RSF
Pourquoi les réseaux de capteurs intelligents comptent
De l’agriculture de précision aux systèmes d’alerte en cas de catastrophe, les réseaux de capteurs sans fil observent notre monde en silence. De minuscules appareils alimentés par batterie, disséminés dans les villes, les usines, les forêts et les hôpitaux, collectent des données et les renvoient pour analyse. Mais parce que ces capteurs sont peu coûteux, éloignés et difficiles à entretenir, ils tombent souvent en panne et s’épuisent rapidement. Cet article explore une nouvelle façon de maintenir ces réseaux plus longtemps, de manière plus fiable et avec moins d’interventions humaines, en utilisant un cadre d’apprentissage intelligent appelé EvoGenRL.
Le défi des capteurs fatigués et défaillants
Les réseaux de capteurs sans fil doivent concilier plusieurs besoins à la fois. Chaque nœud dispose de très peu d’énergie batterie et de capacité de calcul limitée. La météo, les dommages physiques ou les interférences peuvent provoquer des pannes de nœuds ou de liaisons, rompant les chemins de communication. À mesure que les réseaux grandissent et se complexifient, les charges de trafic et les conditions environnantes changent en permanence. Les méthodes traditionnelles s’occupent généralement d’un seul aspect, comme économiser l’énergie ou améliorer le routage, et sont souvent conçues pour des situations fixes et prévisibles. En conséquence, lorsque les pannes s’accumulent ou que les conditions évoluent, ces réseaux peuvent subir des pertes de données, des délais accrus et une réduction de leur durée de vie.
Un cerveau apprenant pour les réseaux de capteurs
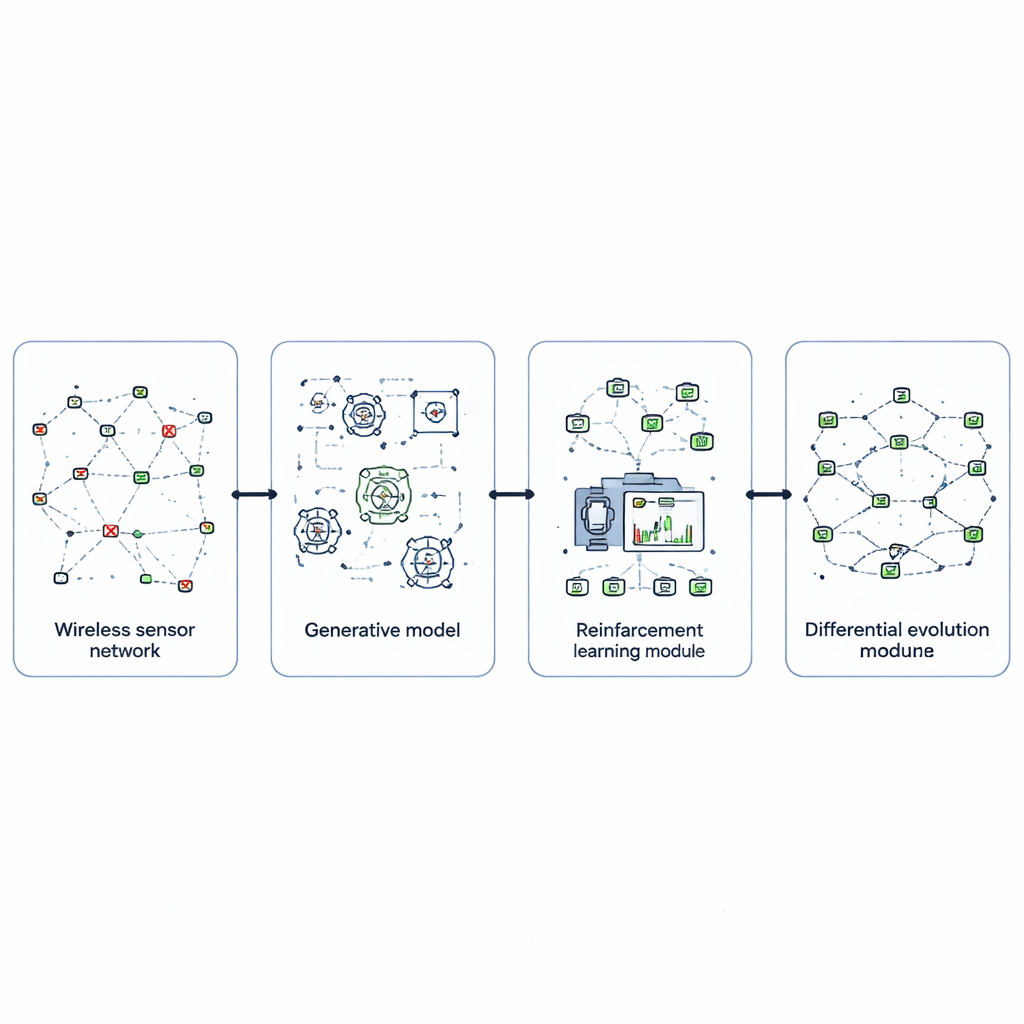
Pour y remédier, les auteurs conçoivent EvoGenRL, un cadre d’apprentissage combiné qui traite le réseau comme un système pouvant apprendre par expérience. Au cœur se trouve l’apprentissage par renforcement, une méthode par essai‑erreur où un agent intelligent observe l’état du réseau — niveaux de batterie, réussite des livraisons, pannes récentes — et choisit des actions comme modifier les routes, mettre certains nœuds en veille ou retransmettre des données. Les actions qui économisent de l’énergie, livrent plus de paquets et récupèrent plus rapidement des pannes rapportent des récompenses plus élevées, incitant l’agent à adopter un comportement à long terme meilleur. Cela transforme le contrôle du réseau, de règles fixes en une politique adaptative qui s’améliore à mesure qu’elle rencontre de nouvelles situations.
Imaginer les problèmes avant qu’ils n’arrivent
Une difficulté majeure pour tout système d’apprentissage est de l’entraîner sur un nombre suffisant de situations réalistes, en particulier les pannes rares mais dommageables. EvoGenRL s’en saisit en utilisant des réseaux antagonistes génératifs, une classe de modèles capables d’inventer de nouvelles données qui imitent des exemples réels. Ici, un réseau générateur fabrique des schémas plausibles de pannes de capteurs — comme des clusters de nœuds défaillants ou des rafales d’interférences — tandis qu’un réseau discriminant juge si ces schémas ressemblent à des événements enregistrés. Par leur compétition, le générateur produit une grande variété de scénarios de panne crédibles. Ces situations synthétiques sont mêlées aux données réelles et fournies à l’agent d’apprentissage par renforcement, qui peut ainsi s’entraîner à faire face à de nombreux types de problèmes avant que le réseau ne les rencontre sur le terrain.
Ajuster le comportement par évolution
Même un agent apprenant intelligent dépend fortement de ses réglages internes, comme la vitesse d’apprentissage, l’importance accordée aux récompenses futures et la fréquence d’exploration de nouvelles actions. Plutôt que de choisir ces paramètres manuellement, les auteurs utilisent une méthode de recherche évolutive appelée évolution différentielle. Ils traitent chaque configuration possible comme un individu d’une population et les laissent « concourir » en fonction de la qualité du contrôle du réseau obtenu en simulation. En mutant, combinant et sélectionnant à plusieurs reprises les meilleurs candidats, la méthode converge vers des hyperparamètres qui rendent l’apprentissage plus rapide, plus stable et mieux adapté aux conditions réseau changeantes. Cette couche évolutive enveloppe l’agent d’apprentissage, affinant progressivement ses performances.
Mise à l’épreuve du cadre
Les chercheurs évaluent EvoGenRL à l’aide d’un jeu de données public d’activité de capteurs sans fil et de simulations réseau détaillées. Ils le comparent à plusieurs schémas de routage et d’optimisation établis trouvés dans la littérature récente. Sur des exécutions répétées et pour des tailles de réseau et des taux de panne variables, le nouveau cadre utilise systématiquement moins d’énergie, maintient davantage de nœuds en vie plus longtemps et conserve des liaisons plus stables. En chiffres, EvoGenRL réduit la consommation d’énergie à environ 2,2 joules par nœud, étend la durée de vie du réseau à 1700 cycles et porte la part des paquets de données délivrés avec succès à 99,7 pour cent. Il réduit aussi le temps de traversal des données à quelques millisecondes et augmente le débit global, ce qui signifie que le réseau peut rester réactif tout en économisant l’énergie.
Ce que cela signifie pour la technologie de tous les jours
En termes simples, EvoGenRL apprend à un réseau de capteurs à prendre soin de lui‑même. En simulant de nombreux types de pannes, en apprenant quelles réponses fonctionnent le mieux et en ajustant continuellement son propre comportement, le système peut prolonger la durée de vie des batteries et maintenir la circulation des données malgré les pannes et les conditions changeantes. Cela le rend attractif pour des usages critiques — surveillance médicale, contrôle industriel et surveillance environnementale — où les visites de maintenance sont coûteuses ou dangereuses et où les interruptions sont inacceptables. Si l’approche exige encore une puissance de calcul significative pendant l’entraînement, elle offre un plan prometteur pour de futurs réseaux autogérés, plus intelligents, plus robustes et plus économes en énergie.
Citation: Lakshmi, S., Aswath, S., Swaminathan, A. et al. Evolutionary reinforcement learning framework for energy-efficient fault resilience and topological stability in WSNs. Sci Rep 16, 11769 (2026). https://doi.org/10.1038/s41598-026-38518-3
Mots-clés: réseaux de capteurs sans fil, réseautique économe en énergie, systèmes tolérants aux pannes, apprentissage par renforcement, modèles génératifs