Clear Sky Science · pl
Modele multimodalne do klasyfikacji raka skóry z użyciem klinicznego tekstu swobodnego i obrazów dermatoskopowych
Dlaczego ważne są mądrzejsze kontrole skóry
Rak skóry jest powszechny, ale jeśli zostanie wykryty wcześnie, pacjenci zwykle mają bardzo dobre rokowania. Lekarze już dziś korzystają ze zdjęć zbliżeniowych pieprzyków, aby ocenić, które z nich wyglądają niepokojąco. To badanie stawia proste pytanie o dalekosiężnych konsekwencjach: czy komputery, które potrafią czytać notatki lekarza dotyczące każdego pieprzyka, a nie tylko oglądać zdjęcia, mogłyby wykrywać raka skóry dokładniej i sprawiedliwiej?

Obrazy plus słowa dają pełniejszy obraz
Naukowcy zbudowali dużą bazę danych z rutynowych wizyt dermatologicznych w Wielkiej Brytanii. Zawierała 5481 zbliżeniowych zdjęć dermatoskopowych od 4538 dorosłych, wraz z podstawowymi danymi pacjenta, takimi jak wiek i typ skóry, oraz czterema rodzajami notatek klinicznych. Notatki obejmowały opis wyglądu zmiany i jej zmian w czasie, występowanie raka skóry w rodzinie, ekspozycję na słońce oraz uwagi chirurga i plan leczenia. Każdy przypadek został oznaczony jako łagodny lub złośliwy, a w miarę możliwości przypadki złośliwe potwierdzono badaniem histopatologicznym.
Ukryte wskazówki w notatkach klinicznych
W przeciwieństwie do prostych danych w formie pól wyboru, tekst swobodny pozwala lekarzom opisać subtelne cechy: pieprzyk, który stał się ciemniejszy, zmianę która krwawi, czy pacjenta pracującego przez lata na zewnątrz. Takie szczegóły mogą być bardzo informatywne, ale mogą też zdradzać odpowiedź. Wiele notatek zawiera to, co autorzy określają jako język sugerujący: zwroty stwierdzające lub mocno sugerujące rozpoznanie albo leczenie, takie jak „rękawica podstawnokomórkowy rak, skierować do biopsji” czy „nie wymaga leczenia”. Jeśli model uczenia maszynowego po prostu przyczepi się do tych skrótów, może wydawać się bardzo dokładny na danych historycznych, zamiast naprawdę nauczyć się rozpoznawać raka z obrazów lub z opisów podanych przez pacjentów.
Uczenie komputerów, by ignorowały skróty
Aby sprostać temu problemowi, zespół zaprojektował kilka poziomów czyszczenia tekstu. Proste reguły najpierw usuwały jawne nazwy chorób skóry oraz słowa „łagodny” i „złośliwy”. Następnie użyto dużego modelu językowego do wykonania subtelniejszego filtrowania. W jednym ustawieniu kluczowe frazy diagnostyczne i plany leczenia zastępowano neutralnymi znacznikami, aby zmierzyć, jak bardzo każdy typ stwierdzenia podnosi wydajność. W najsurowszym ustawieniu pozostawiono tylko faktyczne informacje, które pacjent mógłby rozsądnie podać, takie jak czas obecności zmiany czy wcześniejsze nawyki związane z opalaniem. Takie podejście miało przybliżyć tekst do tego, co widziałby system skierowany do pacjenta, zamiast polegać na wewnętrznych wskazówkach od specjalistów.
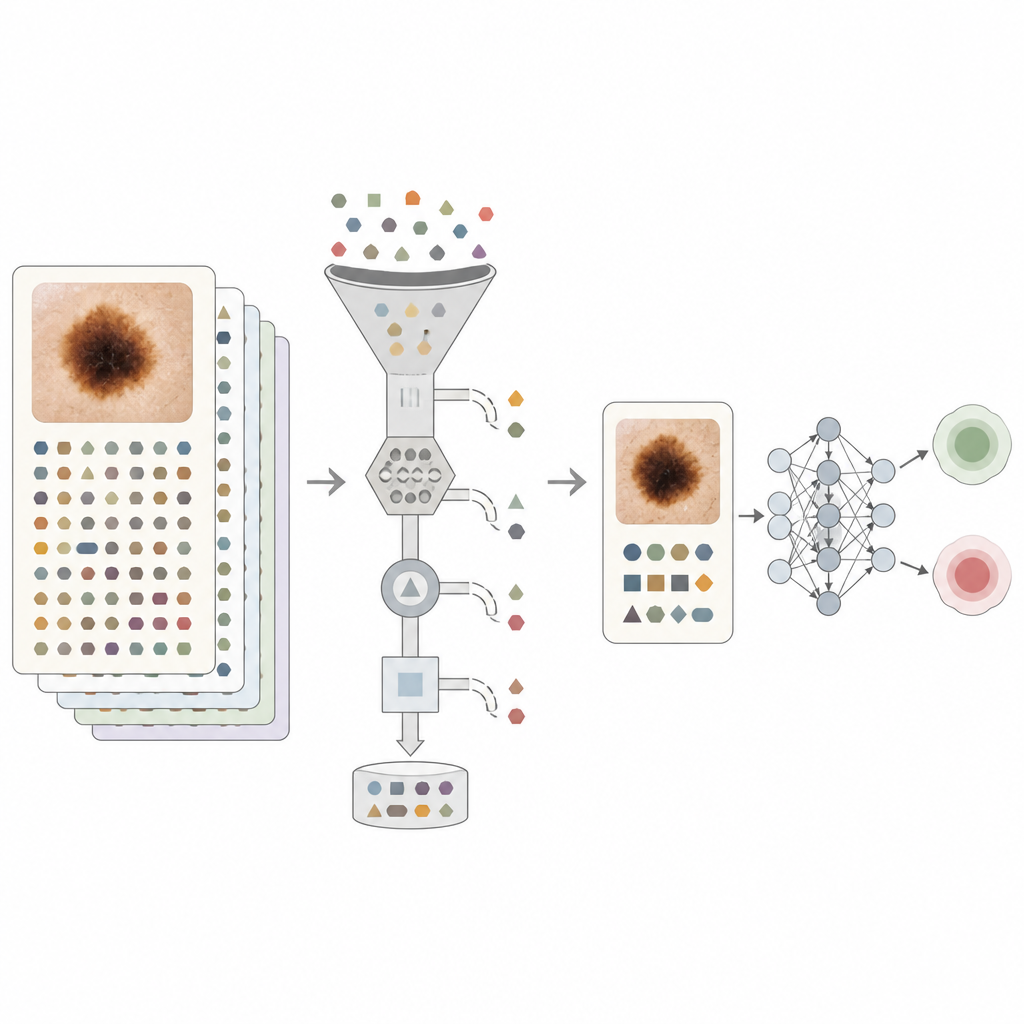
Czego naprawdę nauczyły się modele
Gdy model komputerowy opierał się tylko na obrazach, radził sobie dobrze, ale dodanie nieprzefiltrowanych notatek znacznie poprawiło wyniki. Główna miara dokładności, pole pod krzywą ROC (AUROC), wzrosła z 0,909 dla samych obrazów do 0,970 dla obrazów plus surowe notatki. Nawet gdy usunięto wszelkie oczywiste sformułowania diagnostyczne, połączenie obrazów z ostro przefiltrowanym tekstem osiągnęło AUROC około 0,948, czyli więcej niż każde źródło osobno. Eksperymenty z oznaczonymi frazami wykazały, że proste działania typu „skierować do szpitala” przekazywały niemal tyle samo informacji co jawna etykieta nowotworowa, co potwierdza, że wiele notatek niesie silne wbudowane uprzedzenia. Autorzy przeanalizowali też wydajność w różnych grupach wiekowych i kategoriach koloru skóry i stwierdzili stosunkowo niski poziom niesprawiedliwości, zarówno dla modeli opartych tylko na obrazach, jak i dla w pełni multimodalnych modeli.
Co to oznacza dla przyszłych badań skóry
Dla osób niebędących ekspertami kluczowy wniosek jest taki, że notatki lekarza zawierają rzeczywiste, użyteczne wskazówki, które mogą pomóc komputerom wspierać decyzje dotyczące raka skóry, ale trzeba je przetwarzać ostrożnie. Jeśli modele będą miały dostęp do nieprzefiltrowanych notatek, mogą nauczyć się naśladować sformułowania lekarzy zamiast rozpoznawać ryzykowne zmiany skórne na podstawie cech samej zmiany. Badanie pokazuje, że poprzez przemyślane oczyszczanie tekstu i łączenie go z obrazami oraz podstawowymi danymi pacjenta można zwiększyć dokładność przy jednoczesnym zmniejszeniu ukrytych uprzedzeń. Z czasem takie narzędzia multimodalne mogą pomóc lekarzom pierwszego kontaktu lepiej kierować pacjentów do specjalistów i skrócić czas oczekiwania na opiekę specjalistyczną, a także stworzyć fundament pod bezpieczne systemy uwzględniające tekst, które pewnego dnia mogłyby bezpośrednio wspierać pacjentów.
Cytowanie: Watson, M., Winterbottom, T., Hudson, T. et al. Multimodal models for skin cancer classification using clinical freetext and dermatoscopic images. Commun Med 6, 277 (2026). https://doi.org/10.1038/s43856-026-01456-2
Słowa kluczowe: rak skóry, uczenie maszynowe, dermatologia, notatki kliniczne, obrazowanie medyczne