Clear Sky Science · fr
Modèles multimodaux pour la classification du cancer de la peau utilisant le texte clinique libre et des images dermatoscopiques
Pourquoi des contrôles cutanés plus intelligents comptent
Le cancer de la peau est fréquent, mais lorsqu’il est détecté tôt, les patients s’en sortent généralement très bien. Les médecins utilisent déjà des photographies en gros plan des grains de beauté pour décider lesquels paraissent suspects. Cette étude pose une question simple aux implications importantes : si les ordinateurs pouvaient aussi lire les notes du médecin concernant chaque grain de beauté, et pas seulement les images, pourraient-ils repérer les cancers de la peau de manière plus précise et plus équitable ?

Des images et des mots qui révèlent une histoire plus complète
Les chercheurs ont constitué un large jeu de données à partir de consultations dermatologiques de routine au Royaume-Uni. Il comprenait 5 481 images dermatoscopiques en gros plan provenant de 4 538 adultes, ainsi que des renseignements de base sur les patients comme l’âge et le phototype, et quatre types de notes cliniques. Ces notes décrivaient l’aspect et l’évolution de la lésion, les antécédents familiaux de cancer de la peau, l’exposition solaire du patient et ce que le chirurgien pensait et prévoyait de faire. Chaque cas était étiqueté comme bénin ou malin, les cas malins étant confirmés par biopsie quand cela était possible.
Indices cachés dans les notes cliniques
Contrairement aux simples cases à cocher, le texte libre permet aux médecins de décrire des caractéristiques subtiles : un grain de beauté qui a foncé, une tache qui saigne, ou un patient ayant travaillé de longues années en extérieur. Ces détails peuvent être très informatifs, mais ils peuvent aussi trahir la réponse. De nombreuses notes contiennent ce que les auteurs appellent un langage donnant la solution : des formulations qui énoncent ou suggèrent fortement le diagnostic ou le traitement, comme « carcinome basocellulaire, orienter vers biopsie » ou « aucun traitement nécessaire ». Si un modèle d’apprentissage automatique se contente de s’appuyer sur ces raccourcis, il peut sembler très précis sur des données passées sans réellement apprendre à reconnaître le cancer à partir des images ou des descriptions fournies par le patient.
Apprendre aux ordinateurs à ignorer les raccourcis
Pour résoudre ce problème, l’équipe a conçu plusieurs niveaux de nettoyage du texte. Des règles simples ont d’abord supprimé les noms explicites de maladies cutanées et les mots « bénin » et « malin ». Ils ont ensuite utilisé un grand modèle de langage pour effectuer un filtrage plus subtil. Dans un réglage, les phrases diagnostiques clés et les plans de traitement étaient remplacés par des balises neutres afin que les auteurs puissent mesurer combien chaque type d’énoncé améliorait les performances. Dans le réglage le plus strict, seules les informations factuelles qu’un patient pourrait raisonnablement fournir, comme la durée d’existence d’un grain de beauté ou les habitudes solaires passées, étaient conservées. Cette approche visait à rapprocher le texte de ce qu’un système destiné aux patients pourrait voir plutôt que de s’appuyer sur des indices internes provenant de spécialistes.
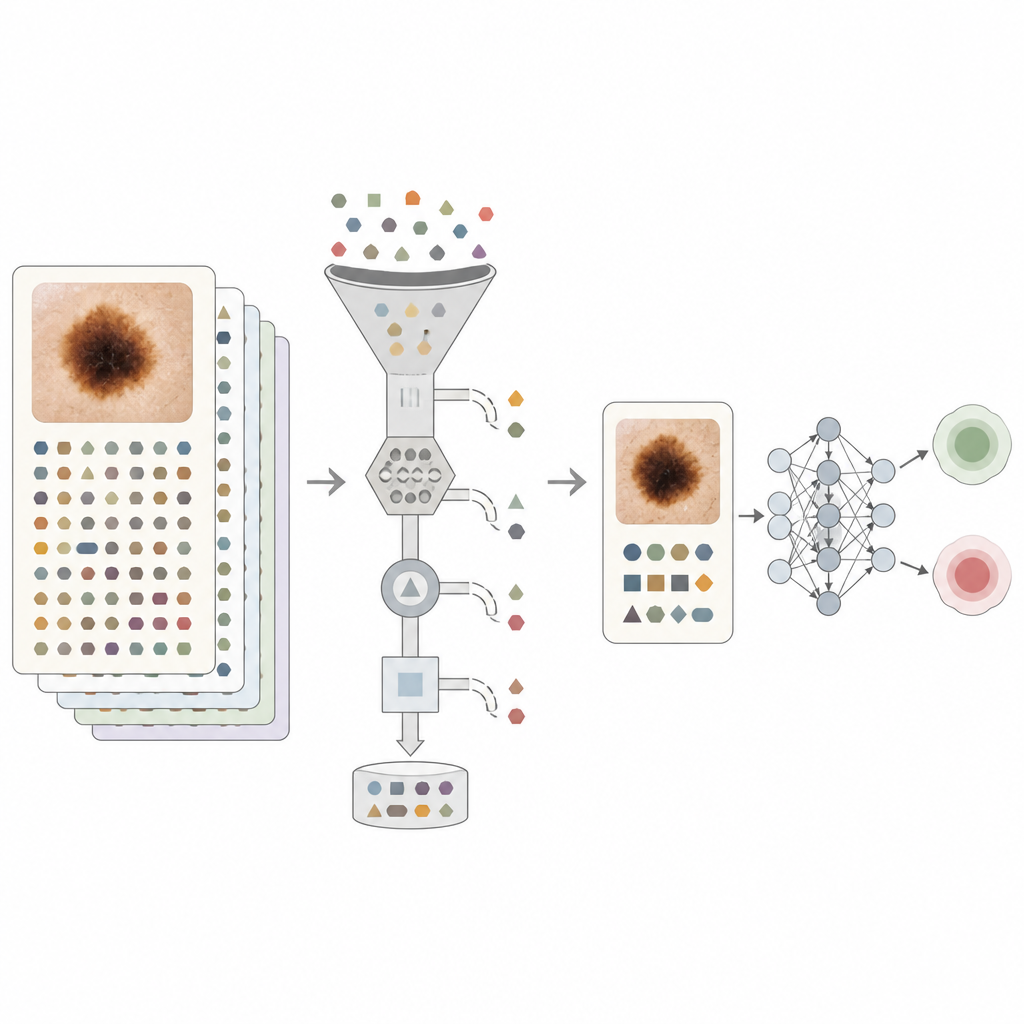
Ce que les modèles ont réellement appris
Lorsque le modèle informatique s’appuyait uniquement sur les images, il obtenait de bons résultats, mais l’ajout de notes non filtrées l’améliorait de manière significative. La mesure principale de précision, l’aire sous la courbe ROC (AUROC), est passée de 0,909 avec les seules images à 0,970 avec images plus notes brutes. Même lorsque tout langage diagnostique évident était supprimé, la combinaison d’images et de texte soigneusement filtré atteignait encore une AUROC d’environ 0,948, supérieure à chacune des sources prises isolément. Des expériences avec des phrases balisées ont montré que des actions simples comme « orienter vers l’hôpital » transmettaient presque autant d’information qu’une étiquette explicite de cancer, confirmant que de nombreuses notes portent un biais intégré fort. Les auteurs ont également examiné les performances selon les tranches d’âge et les catégories de tonalité de peau et ont constaté des niveaux relativement faibles d’iniquité, tant pour le modèle image-seul que pour les modèles pleinement multimodaux.
Ce que cela signifie pour les contrôles cutanés futurs
Pour les non-spécialistes, l’essentiel est que les notes du médecin contiennent des indices réels et utiles qui peuvent aider les ordinateurs à soutenir les décisions concernant le cancer de la peau, mais ils doivent être traités avec précaution. Si les modèles sont autorisés à lire des notes non filtrées, ils risquent d’apprendre à imiter la formulation des médecins plutôt que de reconnaître eux-mêmes les grains de beauté à risque. Cette étude montre qu’en nettoyant soigneusement le texte et en le mêlant aux images et aux données de base du patient, il est possible d’améliorer la précision tout en réduisant les biais cachés. À terme, de tels outils multimodaux pourraient aider les cliniciens de soins primaires à mieux orienter les patients et à réduire les délais d’attente pour les spécialistes, tout en jetant les bases de systèmes sûrs et sensibles au texte qui pourraient un jour assister directement les patients.
Citation: Watson, M., Winterbottom, T., Hudson, T. et al. Multimodal models for skin cancer classification using clinical freetext and dermatoscopic images. Commun Med 6, 277 (2026). https://doi.org/10.1038/s43856-026-01456-2
Mots-clés: cancer de la peau, apprentissage automatique, dermatologie, notes cliniques, imagerie médicale