Clear Sky Science · it
Modelli multimodali per la classificazione del cancro cutaneo usando testo clinico libero e immagini dermatoscopiche
Perché controlli cutanei più intelligenti contano
Il cancro della pelle è comune, ma quando viene diagnosticato precocemente le persone generalmente hanno buone prospettive. I medici usano già fotografie ravvicinate dei nei per decidere quali sembrano preoccupanti. Questo studio pone una domanda semplice ma di grande portata: se i computer potessero leggere anche le note del medico su ciascun neo, oltre alle immagini, potrebbero individuare i tumori cutanei in modo più accurato e più equo?

Immagini e parole raccontano una storia più completa
I ricercatori hanno costruito un ampio set di dati da cliniche dermatologiche di routine nel Regno Unito. Comprendeva 5.481 immagini dermatoscopiche ravvicinate provenienti da 4.538 adulti, insieme a dati di base dei pazienti come età e fototipo, e quattro tipi di note cliniche. Queste note descrivevano l’aspetto della lesione e la sua evoluzione nel tempo, eventuali casi familiari di cancro cutaneo, l’esposizione solare del paziente e il pensiero e il piano d’intervento del chirurgo. Ciascun caso è stato etichettato come benigno o maligno, con i casi maligni confermati da biopsia quando possibile.
Indizi nascosti all’interno delle note cliniche
A differenza dei semplici dati a casella, il testo libero consente ai medici di descrivere caratteristiche sottili: un neo che è diventato più scuro, una lesione che sanguina o un paziente che ha lavorato all’aperto per anni. Questi dettagli possono essere molto informativi, ma possono anche rivelare la risposta. Molte note contengono quello che gli autori chiamano linguaggio indicativo: frasi che enunciano o suggeriscono fortemente la diagnosi o il trattamento, come “carcinoma basocellulare, inviare per biopsia” o “nessun trattamento necessario”. Se un modello di apprendimento automatico si limita ad aggrapparsi a queste scorciatoie, può apparire molto accurato sui dati passati pur imparando poco su come riconoscere realmente il cancro dalle immagini o dalle descrizioni fornite dal paziente.
Insegnare ai computer a ignorare le scorciatoie
Per affrontare questo problema, il team ha progettato diversi livelli di pulizia del testo. Regole semplici hanno innanzitutto rimosso i nomi espliciti delle malattie cutanee e le parole benigno e maligno. Poi è stato usato un grande modello di linguaggio per effettuare un filtraggio più sottile. In una modalità, frasi diagnostiche chiave e piani di trattamento sono stati sostituiti con tag neutri così che gli autori potessero misurare quanto ciascun tipo di affermazione aumentasse la performance. Nella modalità più rigorosa, sono state mantenute solo le informazioni fattuali che un paziente potrebbe ragionevolmente fornire, come da quanto tempo era presente un neo o abitudini solari pregresse. Questo approccio mirava ad avvicinare il testo a ciò che un sistema rivolto ai pazienti potrebbe vedere, piuttosto che fare affidamento su indizi interni forniti da specialisti.
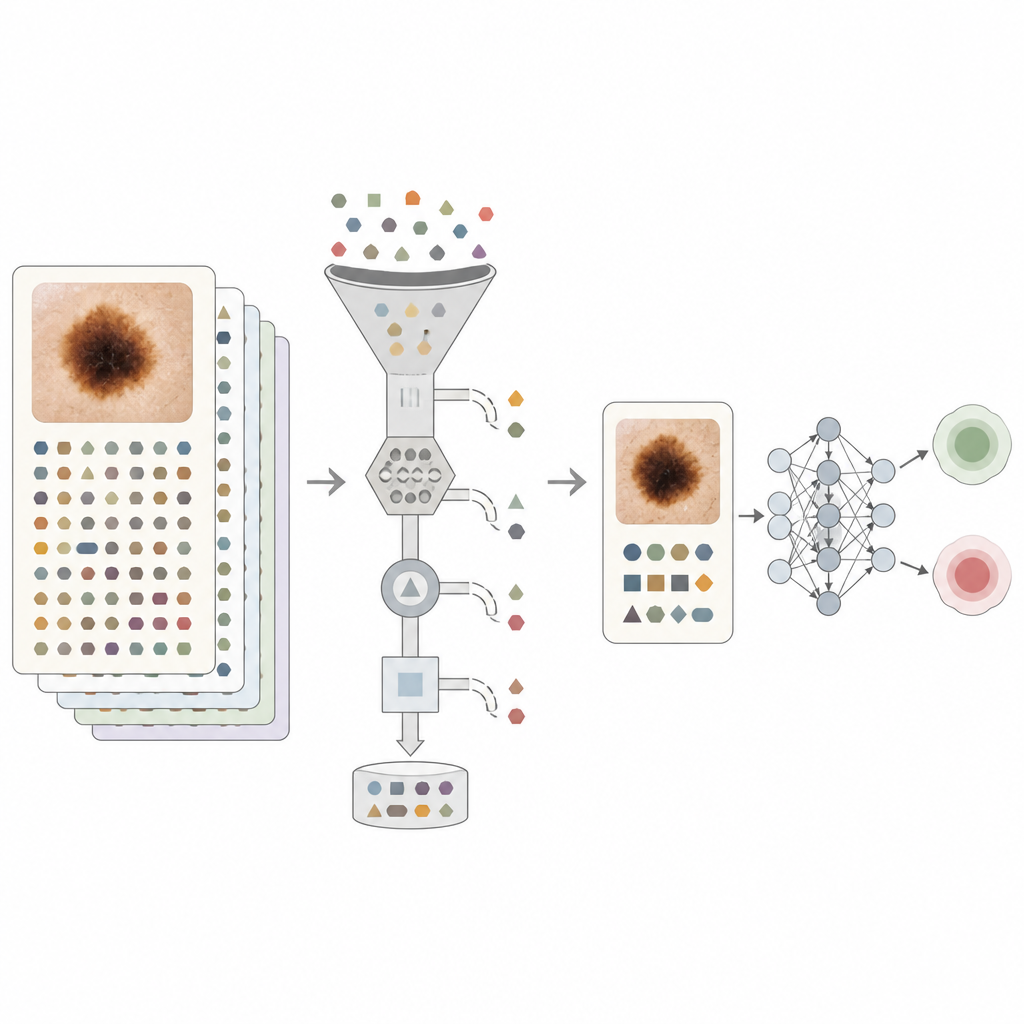
Ciò che i modelli hanno effettivamente imparato
Quando il modello computerizzato si basava solo sulle immagini, rendeva bene, ma aggiungere le note non filtrate lo ha reso significativamente migliore. La misura principale di accuratezza, l’area sotto la curva caratteristica operativa del ricevitore (AUROC), è salita da 0,909 con solo immagini a 0,970 con immagini più note grezze. Anche quando tutto il linguaggio diagnostico ovvio è stato rimosso, combinare immagini con testo attentamente filtrato ha comunque raggiunto un AUROC di circa 0,948, superiore a ciascuna fonte da sola. Gli esperimenti con frasi taggate hanno mostrato che azioni semplici come “inviare in ospedale” trasmettevano informazioni quasi quanto un’etichetta di cancro esplicita, confermando che molte note contengono forti bias incorporati. Gli autori hanno inoltre esaminato le prestazioni per fasce d’età e categorie di tono della pelle e hanno riscontrato livelli relativamente bassi di iniquità, sia per i modelli basati solo sulle immagini sia per i modelli completamente multimodali.
Cosa significa per i controlli cutanei futuri
Per i non esperti, il punto chiave è che le note del medico contengono indizi reali e utili che possono aiutare i computer a supportare le decisioni sul cancro della pelle, ma devono essere gestite con attenzione. Se ai modelli è permesso leggere note non filtrate, potrebbero imparare a imitare la formulazione dei medici invece di riconoscere autonomamente i nei a rischio. Questo studio mostra che pulendo con cura il testo e combinandolo con immagini e dati di base del paziente è possibile aumentare l’accuratezza riducendo al contempo bias nascosti. Col tempo, strumenti multimodali di questo tipo potrebbero aiutare i clinici di cure primarie a effettuare referral migliori e ridurre i tempi d’attesa per le cure specialistiche, oltre a porre le basi per sistemi sicuri e consapevoli del testo che un giorno potrebbero assistere direttamente anche i pazienti.
Citazione: Watson, M., Winterbottom, T., Hudson, T. et al. Multimodal models for skin cancer classification using clinical freetext and dermatoscopic images. Commun Med 6, 277 (2026). https://doi.org/10.1038/s43856-026-01456-2
Parole chiave: cancro della pelle, apprendimento automatico, dermatologia, note cliniche, imaging medico