Clear Sky Science · nl
Multimodale modellen voor huidkankerclassificatie met klinische vrije tekst en dermatoscopische beelden
Waarom slimere huidcontroles ertoe doen
Huidkanker komt veel voor, maar wanneer het vroeg wordt ontdekt hebben mensen meestal een goede prognose. Dokters gebruiken al close-upfoto’s van moedervlekken om te bepalen welke plekken zorgwekkend lijken. Deze studie stelt een eenvoudige vraag met grote consequenties: als computers ook de aantekeningen van de arts bij elke moedervlek zouden kunnen lezen, en niet alleen de beelden, zouden ze dan huidkankers accurater en eerlijker kunnen opsporen?

Beelden plus woorden vertellen een vollediger verhaal
De onderzoekers bouwden een grote dataset op uit routinematige dermatologiepoliklinieken in het Verenigd Koninkrijk. Deze bevatte 5481 close-up dermatoscopische afbeeldingen van 4538 volwassenen, samen met basisgegevens zoals leeftijd en huidtype, en vier soorten klinische aantekeningen. Die aantekeningen gingen over hoe de laesie eruitzag en veranderde in de tijd, of huidkanker in de familie voorkwam, hoeveel blootstelling aan zon de persoon had gehad, en wat de chirurg dacht en van plan was te doen. Elk geval werd gelabeld als goedaardig of kwaadaardig, waarbij kwaadaardige gevallen waar mogelijk door biopsie werden bevestigd.
Verborgen aanwijzingen in klinische aantekeningen
In tegenstelling tot eenvoudige vinkvakgegevens stelt vrije tekst artsen in staat subtiele kenmerken te beschrijven: een moedervlek die donkerder is geworden, een plekje dat bloedt, of een patiënt die jaren buiten heeft gewerkt. Zulke details kunnen zeer informatief zijn, maar ze kunnen ook het antwoord verraden. Veel aantekeningen bevatten wat de auteurs "leidende taal" noemen: zinnen die de diagnose of behandeling expliciet stellen of sterk suggereren, zoals "basalioom, verwijzen voor biopsie" of "geen behandeling nodig." Als een machine-learningmodel zich eenvoudigweg op deze korte wegen vastklampt, kan het op historische data zeer accuraat lijken terwijl het weinig leert over hoe kanker daadwerkelijk te herkennen uit beelden of patiëntbeschrijvingen.
Computers leren shortcuts negeren
Om dit probleem aan te pakken, ontwierp het team meerdere niveaus van tekstopschoning. Eenvoudige regels verwijderden eerst expliciete namen van huidaandoeningen en de woorden goedaardig en kwaadaardig. Daarna gebruikten ze een groot taalmodel voor subtielere filtering. In een opzet werden sleutelzinnen over diagnose en behandelingsplannen vervangen door neutrale tags zodat de auteurs konden meten hoeveel elk type uitspraak de prestaties versterkte. In de strengste opzet werd alleen feitelijke informatie bewaard die een patiënt redelijkerwijs zelf zou kunnen geven, zoals hoe lang een moedervlek aanwezig was of eerdere zongewoonten. Deze aanpak was bedoeld om de tekst dichter bij te brengen wat een patiëntgericht systeem zou zien in plaats van afhankelijk te zijn van interne aanwijzingen van specialisten.
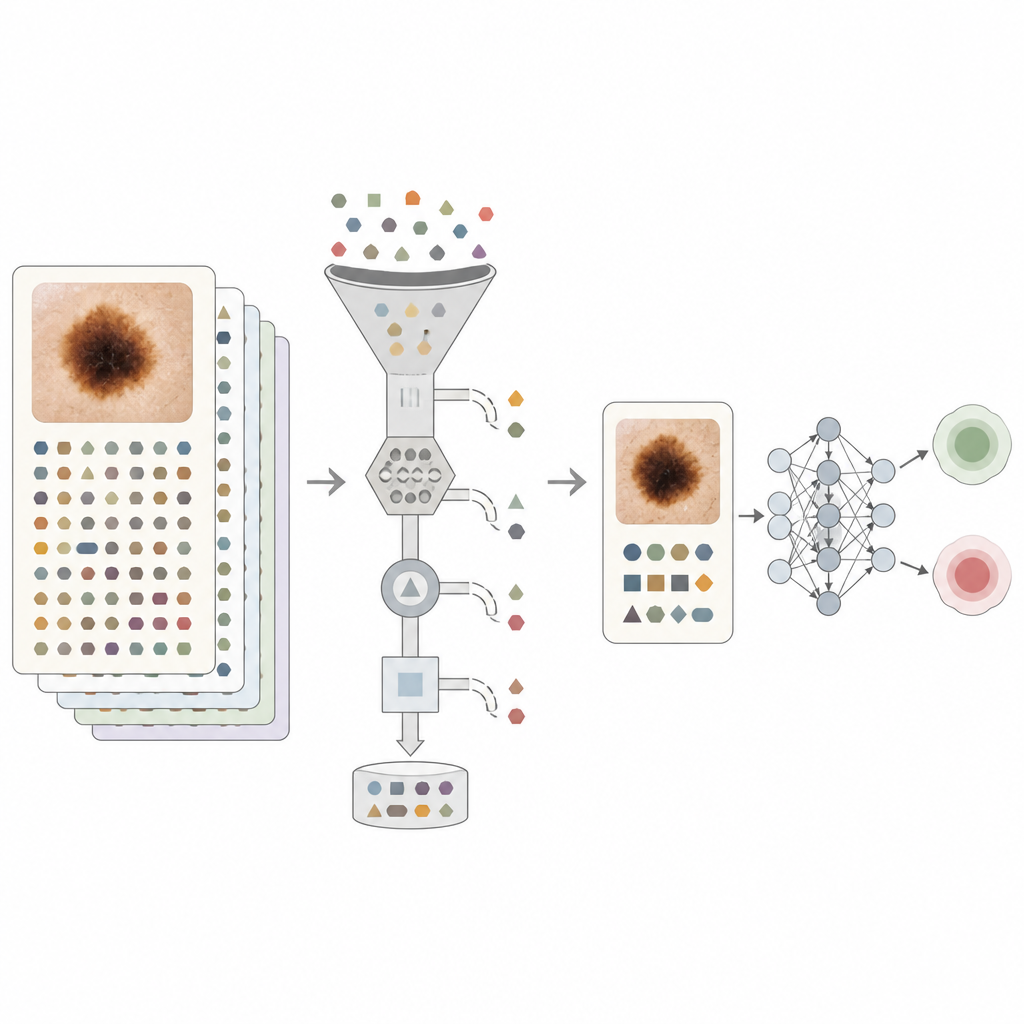
Wat de modellen daadwerkelijk leerden
Wanneer het computermodel alleen op beelden vertrouwde, presteerde het goed, maar het toevoegen van ongefilterde aantekeningen maakte het significant beter. De belangrijkste nauwkeurigheidsmaat, de oppervlakte onder de receiver operating characteristic-curve (AUROC), steeg van 0,909 met alleen beelden naar 0,970 met beelden plus ruwe aantekeningen. Zelfs wanneer alle duidelijke diagnostische taal was verwijderd, bereikte de combinatie van beelden met zorgvuldig gefilterde tekst nog steeds een AUROC van ongeveer 0,948, hoger dan één van de bronnen afzonderlijk. Experimenten met getagde zinnen toonden aan dat simpele uitingen als "verwijzen naar ziekenhuis" bijna evenveel informatie gaven als een expliciet kankerl etiket, wat bevestigt dat vele aantekeningen sterke ingebouwde bias bevatten. De auteurs onderzochten ook de prestaties over leeftijdsgroepen en huidtintcategorieën en vonden relatief lage niveaus van oneerlijkheid, zowel voor de alleen-beeldmodellen als voor de volledig multimodale modellen.
Wat dit betekent voor toekomstige huidcontroles
Voor niet-experts is de belangrijkste conclusie dat doktersnotities echte, bruikbare aanwijzingen bevatten die computers kunnen helpen bij beslissingen rond huidkanker, maar dat ze met zorg moeten worden behandeld. Als modellen ongefilterde aantekeningen mogen lezen, kunnen ze de formulering van dokters nadoen in plaats van zelf risicovolle moedervlekken te herkennen. Deze studie laat zien dat door de tekst doordacht te schonen en te combineren met beelden en basispatiëntgegevens, het mogelijk is de nauwkeurigheid te verhogen terwijl verborgen bias wordt verminderd. In de loop van de tijd zouden zulke multimodale hulpmiddelen huisartsen kunnen helpen beter te verwijzen en wachttijden voor specialistische zorg te verkorten, en tegelijkertijd de basis leggen voor veilige, tekstaandachtige systemen die op termijn mogelijk direct patiënten kunnen ondersteunen.
Bronvermelding: Watson, M., Winterbottom, T., Hudson, T. et al. Multimodal models for skin cancer classification using clinical freetext and dermatoscopic images. Commun Med 6, 277 (2026). https://doi.org/10.1038/s43856-026-01456-2
Trefwoorden: huidkanker, machine learning, dermatologie, klinische aantekeningen, medische beeldvorming